 Zaloguj
Zaloguj




Na przestrzeni lat opracowano kilkadziesiąt rodzajów monochromatycznych kodów kreskowych. Niektóre z nich służą do zapisywania tylko cyfr, niektóre do znaków alfanumerycznych, a jeszcze inne pozwalają na zapis dowolnej treści. Kody różnią się między sobą sposobem oznaczania zer i jedynek, dopuszczalną długością zapisanego ciągu znaków, gęstością upakowania znaków, odpornością na błędy odczytu oraz sformalizowanymi wymaganiami, dostosowanymi do specyfiki branż, w których są stosowane.
I choć niektóre z kodów zostały zaprojektowane z myślą o bardzo konkretnych aplikacjach, niejednokrotnie zdarza się, że bywają też używane w zupełnie innych przypadkach, niż planowali autorzy. To czy tak się dzieje, zależy przede wszystkim od dostępności narzędzi do kodowania i skanowania danych formatów, ale czasem też zapewne z nieświadomości inżynierów odnośnie dostępności innych standardów, bardziej adekwatnych do danego zastosowania. Niniejszy artykuł ma na celu zwiększyć świadomość polskich inżynierów w zakresie możliwości używania różnorodnych kodów kreskowych.
Najpopularniejsze kody
Chyba nie ma wątpliwości, że kodami kreskowymi, z jakimi większość ludzi spotyka się na co dzień są oznaczenia produktów sprzedawanych w sklepach. Są one drukowane w kilku formatach, których użycie zależy od regionu w którym towar został wyprodukowany oraz od wielkości produktu.
W USA, Kanadzie, Wielkiej Brytanii, Australii i Nowej Zelandii powszechnie stosowany jest kod standard UPC, a np. w Europie: EAN. Oba z tych kodów występują w wersjach krótszych i dłuższych, przy czym krótsze nadrukowuje się tam, gdzie dłuższy kod by się zwyczajnie nie zmieścił: na opakowaniach gum do żucia i innych małych przedmiotach.
Kody UPC
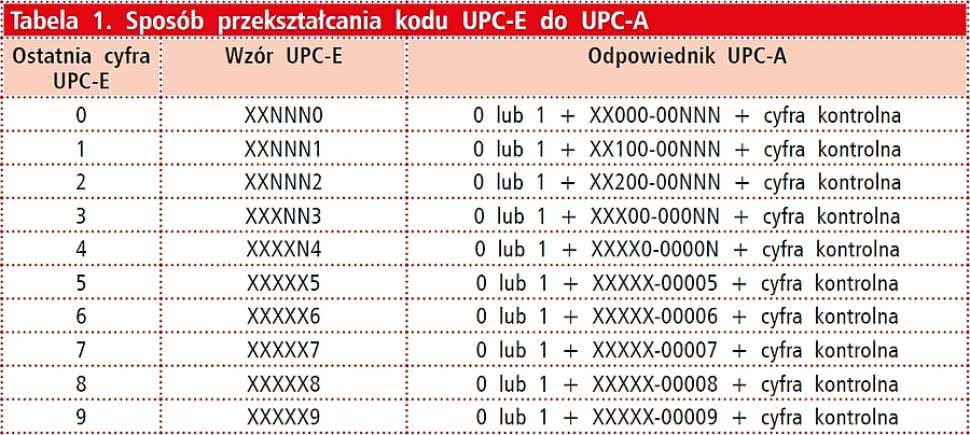
Tabela 1. Sposób przekształcania kodu UPC-E do UPC-A
Kody w tym formacie mogą zawierać tylko cyfry w systemie dziesiętnym. Istnieją dwie powszechnie stosowane odmiany kodów UPC (Universal Product Code): 12-cyfrowy UPC-A i 6-cyfrowy UPC-E oraz kilka mających tylko specjalistyczne zastosowanie (UPC-B, UPC-C, UPC-D, UPC-2, UPC-5, które różnią się długością i obecnością cyfry kontrolnej).
Kod UPC-E z założenia ma dać się przekształcić do kodu UPC-A, poprzez dodanie w jego środkowej części określonego ciągu zer i dodatkowych cyfr, zależnych od ostatniej z cyfr w kodzie UPC-E (zgodnie z tabelą 1). Kod UPC-A zawiera na swojej ostatniej pozycji cyfrę kontrolną, co oznacza, że może pomieścić 1011 (sto miliardów) wartości.
Dla kodu UPC-E również jest obliczana cyfra kontrolna, ale nie jest ona zapisywana na jednej z 6 pozycji, a jedynie wpływa na sposób prezentacji kolejnych cyfr w kodzie, o czym dalej. Ponieważ ostatnia cyfra w kodzie UPC-E informuje natomiast o sposobie konwersji na UPC-A, więc jest też użyteczna, oznaczałoby to, że w UPC-E można zapisać milion kombinacji, zachowując przy tym zdolność do wykrycia 100% błędów w postaci jednej niepoprawnie odczytanej cyfry.
W praktyce liczba dostępnych kombinacji jest nawet większa i wynosi 64 miliony, co wynika z faktu, że sam sposób zakodowania poszczególnych cyfr w UPC-E też ma znaczenie. To jeden z najbardziej skomplikowanych systemów kodowania w kodach jednowymiarowych.
Sposób druku kodu UPC-A nie jest trywialny. Cyfry podzielone są na dwa bloki, po 6 cyfr każdy. Pomiędzy tymi blokami umieszczony jest znak środka, który nie reprezentuje żadnej liczby. Na krańcach kodu znajdują się identyczne znaki startu/stopu, które również nie reprezentują żadnej liczby, a jedynie, wraz ze znakiem środka, wskazują czytnikowi początek, środek i koniec kodu, ułatwiając analizę obrazu.
Aby umożliwić poprawny odczyt kodu, na zewnątrz znaków startu i stopu muszą znaleźć się odpowiednio szerokie strefy czyste (quiet zones), dzięki którym obrazy znajdujące się naokoło kodu nie będą traktowane jako jego fragmenty.
Same cyfry zakodowane są za pomocą 7 przylegających do siebie, cienkich czarnych lub białych pasków dla każdej z nich. Jak łatwo policzyć, 7 pasków, które mogą przyjąć tylko jeden z dwóch kolorów (biały lub czarny) skutkuje powstaniem 27, czyli 128 kombinacji, które wykorzystywane są do zapisu tylko 10 różnych cyfr. Nie jest to bynajmniej przeoczenie, a celowy zabieg, zwiększający poprawność odczytu.
Każda cyfra musi być zakodowana z użyciem 7 pasków, które przez to, że nie ma pomiędzy nimi odstępów, mogą się ze sobą zlewać, tworząc wizualnie paski o grubości równej wielokrotności pojedynczego paska. Co więcej wprowadzono też regułę, że wizualnie, każda cyfra może być reprezentowana jedynie za pomocą dwóch białych i dwóch czarnych pasków, co oznacza, że maksymalna grubość takiego połączonego paska(czy to czarnego, czy białego), może być równa czterokrotnej grubości paska pojedynczego.
Wtedy to, z konieczności zmieszczenia się w bloku o szerokości 7 pojedynczych pasków, pozostałe trzy paski muszą mieć szerokość pojedynczą (każdy). W efekcie dostępne jest tylko osiem kombinacji, w których pojawia się biały lub czarny pasek o wizualnej grubości czterech pojedynczych pasków, osiem kombinacji, w których jest tylko jeden pasek pojedynczych rozmiarów i trzy paski podwójnych rozmiarów oraz 24 kombinacje z dwoma paskami o grubości pojedynczej, jednym podwójnym i jednym potrójnym.
Razem daje to już tylko 40, a nie 128 dopuszczalnych kombinacji! Ale to nie wszystko. Połowa z tych kombinacji zaczyna się od paska białego, kończąc na czarnym, a połowa od czarnego, a kończąc na białym (co wynika z faktu, że każda kombinacja składa się wizualnie z czterech pasków, a więc z parzystej ich liczby).
Gdyby zestawić obok siebie dwie cyfry, z których jedna byłaby zakodowana z użyciem kombinacji zaczynającej się od paska białego, a druga od czarnego, to ponieważ pomiędzy kodami dla poszczególnych cyfr nie ma odstępów, ostatni pasek pierwszej cyfry byłby czarny i zlewałby się z pierwszym, czarnym paskiem drugiej cyfry.
Znacznie zwiększyłoby to trudność odczytu, gdyż w najgorszym wypadku prowadziłoby to do zlania się ze sobą 8 pojedynczych pasków, których odróżnienie np. od 7 zlanych ze sobą pasków wymagałoby dużo większej precyzji niż odróżnienie zlanych ze sobą 3 i 4 pasków.
Wszak pasek o grubości 8-krotności paska pojedynczego różni się od paska o grubości 7-krotności paska pojedynczego tylko o 12,5%, podczas gdy paski pasek poczwórny od potrójnego o 25%, co pozwala dopuścić mniejszą precyzję pomiaru szerokości pasków. Oczywiście pod warunkiem, że skaner jest w ogóle w stanie wykryć pasek pojedynczej grubości, co jednak jest w praktyce zadaniem łatwiejszym niż rozróżnienie paska 7-krotnego od 8-krotnego.
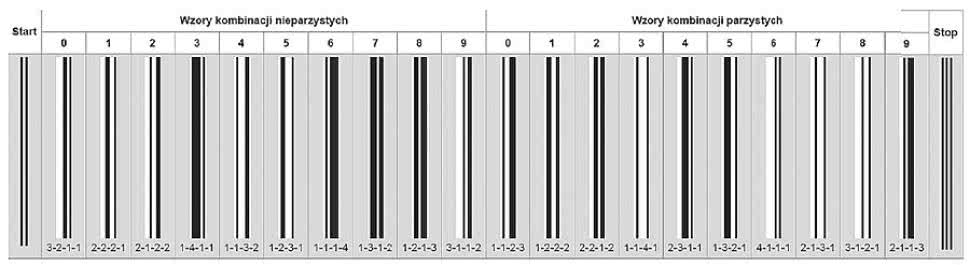
W związku z powyższym, aby uniknąć tych problemów, inżynierowie tworzący kod UPC uznali, że skoro dostępna liczba kombinacji przy ustalonych wcześniej zasadach wynosi 40, a do zakodowania cyfr dziesiętnych wystarczy tylko 10, można swobodnie odrzucić połowę z nich, tych zaczynających się od paska czarnego, zwiększając tym samym pewność odczytu kodu.
Jednakże zrezygnowanie z wykorzystania 10 z pozostałych 20 dopuszczalnych kombinacji byłoby zwykłym marnotrawstwem, w związku z tym podjęto jeszcze jedną decyzję, ułatwiającą wykrywanie błędów podczas skanowania: ustalono, że suma grubości (liczonych jako wielokrotności grubości paska pojedynczego) czarnych pasków musi być nieparzysta, co zredukowało liczbę dopuszczalnych kombinacji do 10.
Teoretycznie tak zaprojektowany kod pozwala zabezpieczyć się przed błędnym rozpoznaniem kodu odczytywanego "do góry nogami", gdyż wszystkie cyfry muszą się zaczynać od białego, a kończyć czarnym paskiem. Uznano jednak, że to zbyt małe zabezpieczenie i zadecydowano, że cyfry znajdujące się po prawej stronie od znacznika środka będą musiały kodowane w inny sposób niż te po lewej.

Rysunek 1. Treść "00222578463" zakodowana w postaci kodu UPC-A
Wizualnie będą zakodowane w sposób odwrotny niż ten dla cyfr z lewej strony paska. Oznacza to, że cyfry po prawej zawsze zaczynają się od paska czarnego, a kończą białym oraz że suma grubości czarnych pasków po prawej (liczona tak samo jak po lewej) stronie od środka będzie dla każdej z cyfr parzysta.
W efekcie, wizualnie jedynka zapisana po prawej stronie będzie inwersją jedynki zapisanej po lewej stronie (rysunek 1). W ten sposób udało się też uniknąć problemu zlewania się ze sobą czarnych lub białych pasków z paskami startu, końca i środkowym.
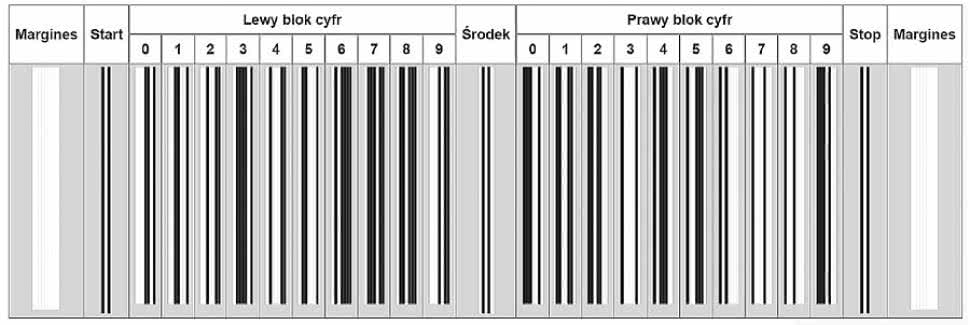
Rysunek 2. Sposób kodowania cyfr w UPC-A
Zestaw dopuszczalnych cyfr po obu stronach oraz format kodu UPC-A został przedstawiony na rysunku 2. Ponieważ znaki startu i końca mają szerokość 3 pojedynczych segmentów, znak środka ma szerokość 5 pojedynczych segmentów, puste przestrzenie po lewej i prawej stronie całego kodu muszą mieć szerokość równą przynajmniej 9-krotności pojedynczego segmentu, a każda z 12 cyfr ma wspomnianą już szerokość 7 segmentów, daje to łączną szerokość kodu 3*2+5+12*7=95 szerokości najcieńszego paska, a razem z pustymi przestrzeniami kod musi zająć nie mniej niż 113 szerokości pojedynczego segmentu.
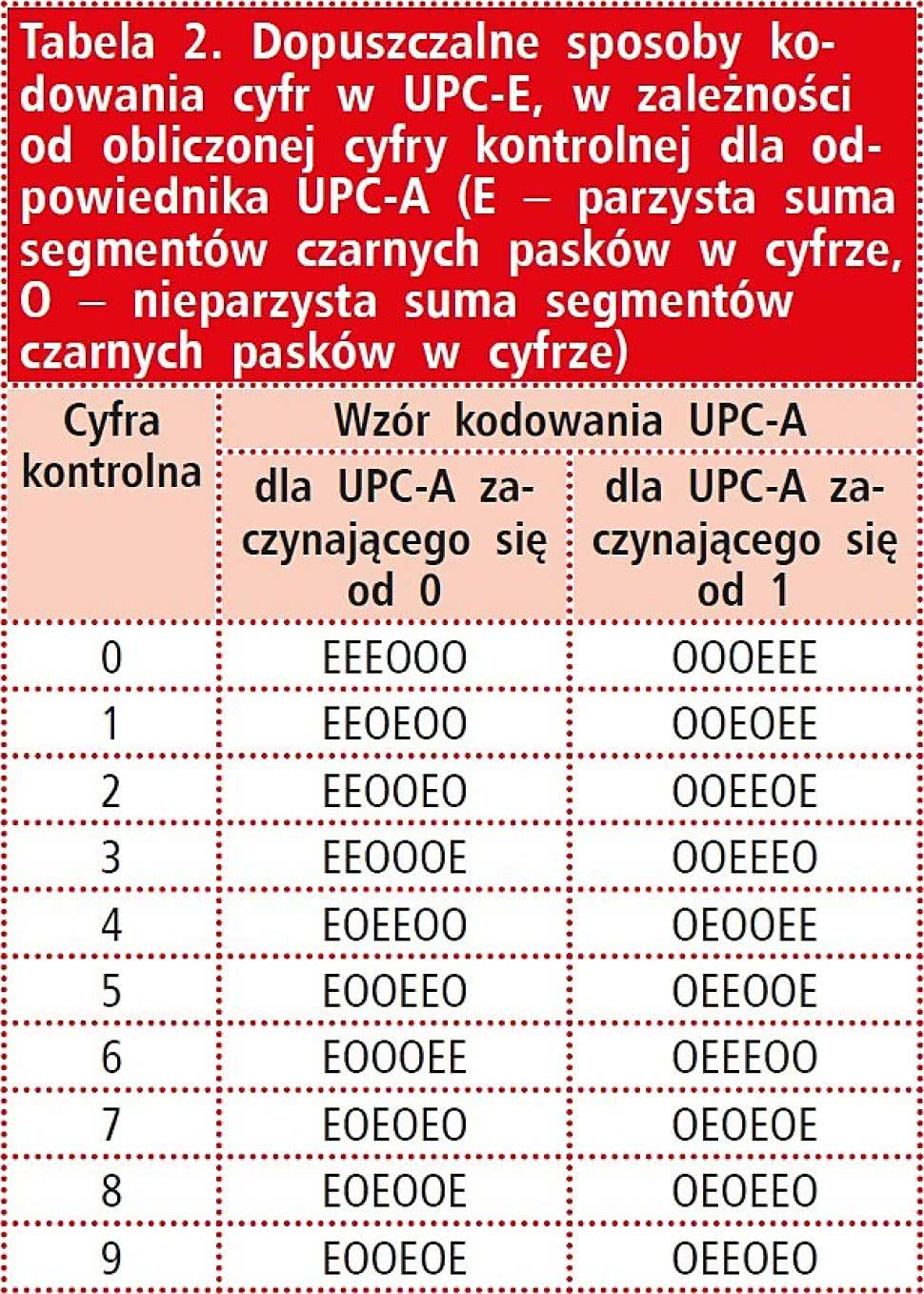
Tabela 2. Dopuszczalne sposoby kodowania cyfr w UPC-E, w zależności od obliczonej cyfry kontrolnej dla odpowiednika UPC-A (E – parzysta suma segmentów czarnych pasków w cyfrze, O – nieparzysta suma segmentów czarnych pasków w cyfrze)
Zasady dotyczące kodowania UPC-E są bardzo podobne do UPC-A, ale dostępne 40 kombinacji rozmieszczenia pasków dla cyfr zostało użyte do zwiększenia liczby przechowywanych informacji. Kod UPC-E nie ma znaku środka, znak początku jest identyczny jak w przypadku UPC-A, a znak końca ma szerokość sześciu segmentów i postać naprzemiennych pojedynczych białych i czarnych pasków.
Cyfry nadal kodowane są za pomocą czterech naprzemiennych pasków, zajmujących za każdym razem 7 segmentów (40 kombinacji), ale z braku znaku środka, całkowicie wykluczono z użycia kody zaczynające się od czarnego paska - dzięki temu nie ma obaw, że dwie przylegające cyfry będą się ze sobą zlewać.
Z pozostałych 20 kombinacji zamiast wykluczyć te, które mają parzystą sumaryczną grubość czarnych pasków przyjęto, że ich obecność będzie niosła ze sobą dodatkową informację, a problem odczytu kodu "do góry nogami" będzie niwelowany dzięki kodowi końca, odmiennemu od kodu początku.
Ta dodatkowa informacja obejmuje zarówno wartość cyfry kontrolnej, jak i informację o pierwszej cyfrze kodu UPC-A, do którego UPC-E można rozszerzyć. Aby pokazać jak to jest zrealizowane, trzeba najpierw zaprezentować sposób obliczania cyfry kontrolnej kodu UPC-A.
Cyfra kontrolna liczona jest poprzez zsumowanie nieparzystych cyfr kodu UPC-A, przemnożenie tej sumy przez 3 i dodanie do wyniku cyfr parzystych kodu (z pominięciem 12. cyfry, która jest przecież właśnie obliczana). Następnie bierze się resztę z dzielenia uzyskanej sumy przez 10 i jeśli jest ona różna od 0, odejmuje się ją od 10, co pozwala na uzyskanie cyfry kontrolnej.
Cyfrę kontrolną dla kodu UPC-E oblicza się w identyczny sposób, ale dopiero po rozszerzeniu kodu do postaci UPC-A. Ponieważ zgodnie z tabelą 1., odpowiednik UPC-E w postaci UPC-A może zaczynać się od cyfry 0 lub 1, licząc cyfrę kontrolną dla UPC-E uzyskuje się dwa możliwe rozwiązania.
Rysunek 3. Sposób kodowania cyfr w UPC-E
Jeśli kod jest aktualnie tworzony, a nie skanowany, twórca wie, czy pierwszą cyfrą odpowiadającego UPC-E kodu UPC-A powinno być 0 czy 1 (wie, który kod chce zapisać), dzięki czemu wie, która z cyfr kontrolnych jest poprawna i na tej podstawie określa schemat zastosowania 20 wcześniej wspomnianych kombinacji pasków do utworzenia kodu UPC-E.
Jeśli kod jest odczytywany, a cyfra kontrolna sprawdzana, skaner rozważa obie obliczone wartości cyfry, a następnie sprawdza, która z nich pasuje do zastosowanego schematu kodowania. Dopuszczalne schematy zostały zebrane w tabeli 2 i odnoszą się do sposobu kodowania cyfr, przedstawionego na rysunku 3.
Szerokość kodu UPC-E również można przedstawić w postaci wielokrotności najmniejszego segmentu. 6 cyfr po 7 segmentów każda plus 3 segmenty startu i 6 segmentów stopu oraz brak przerw dają łącznie 51 segmentów szerokości, czyli o ponad połowę mniej niż kod UPC-A, który UPC-E może reprezentować (rysunek 4).

Rysunek 4. Treść "12345670" zakodowana w postaci kodu UPC-E
Zastosowanie kodów UPC obejmuje przede wszystkim znakowanie towarów przeznaczonych do sprzedaży detalicznej na rynkach w krajach anglojęzycznych, ale bywają one też wykorzystywane w farmaceutyce i w wydawnictwach.
Oczywiście, aby zapewnić jednoznaczną, unikalną identyfikację produktów pochodzących od różnych wytwórców, konieczne było określenie zasad przypisywania numerów produktom oraz stworzenie organizacji, która by to nadzorowała.
Aktualnie, kodami tymi zarządza międzynarodowa organizacja GS1, przy czym kody UPC są zastępowane kodami w formacie EAN, a jednocześnie wszystkie z nich, jeśli są wprowadzane do sprzedaży detalicznej, muszą pasować do standardu GTIN (Global Trade Item Numbers).
Kody EAN
W Europie i Azji również postanowiono opracować standard kodów kreskowych, bazując na osiągnięciach amerykańskich, czyli na kodzie UPC, ale tworząc nieco bardziej zaawansowane rozwiązanie. A ponieważ globalizacja pociągnęła za sobą konieczność ułatwienia sprzedaży importowanych towarów w dowolnym kraju, uznano, że projektowany kod będzie wstecznie kompatybilny z UPC. W ten sposób powstał kod EAN (dawniej European Article Number, a obecnie International Article Number), który jest aktualnie promowanym przez organizację GS1 i ma docelowo zastąpić kody UPC.
Podstawowym kodem EAN jest EAN-13, który zawiera 13 cyfr dziesiętnych, a więc o jedną więcej niż UPC-A. Każdy kod UPC-A będzie poprawnie odczytany przez czytnik kodów EAN-13 z tym, że dodatkowo, odczytana wartość zostanie poprzedzona cyfrą 0. Natomiast czytniki kodów UPC-A będą w stanie poprawnie odczytywać kody EAN-13, które zaczynają się od zera.
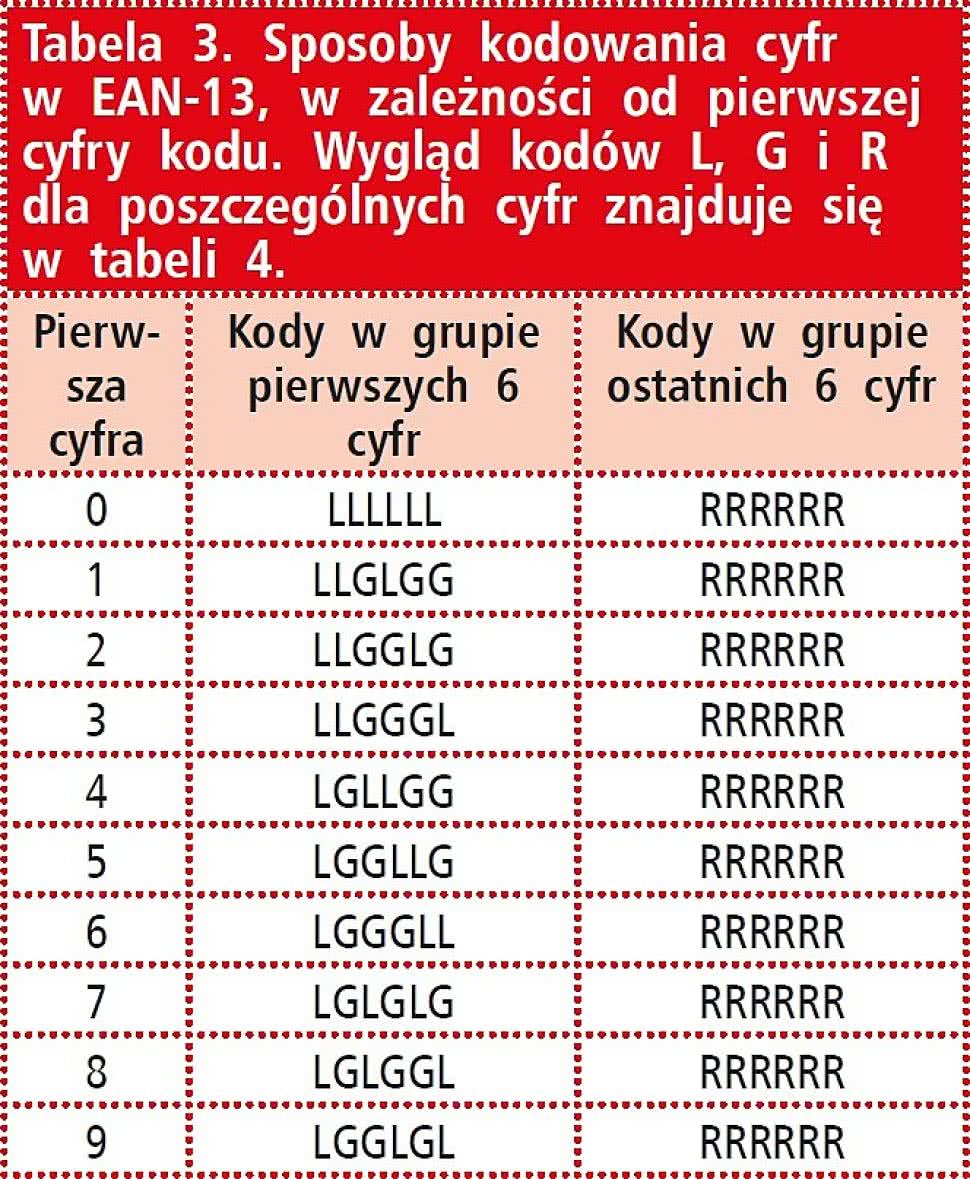
Tabela 3. Sposoby kodowania cyfr w EAN-13, w zależności od pierwszej cyfry kodu. Wygląd kodów L, G i R dla poszczególnych cyfr znajduje się w tabeli 4. |
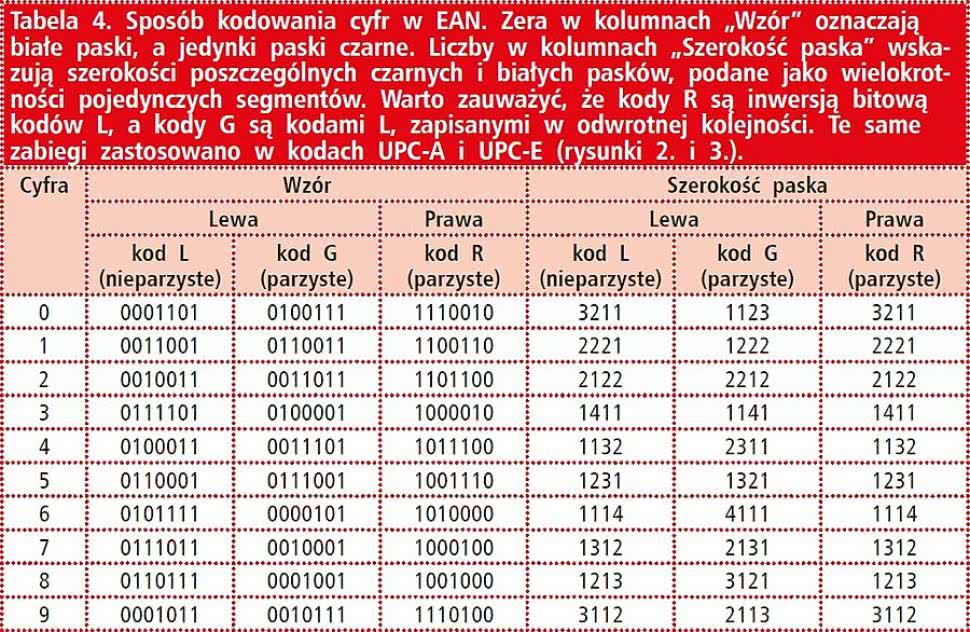
Tabela 4. Sposób kodowania cyfr w EAN. Zera w kolumnach "Wzór" oznaczają białe paski, a jedynki paski czarne. Liczby w kolumnach "Szerokość paska" wskazują szerokości poszczególnych czarnych i białych pasków, podane jako wielokrotności pojedynczych segmentów. Warto zauważyć, że kody R są inwersją bitową kodów L, a kody G są kodami L, zapisanymi w odwrotnej kolejności. Te same zabiegi zastosowano w kodach UPC-A i UPC-E (rysunki 2. i 3.). |
Wynika to z faktu, że w kodach EAN-13, zastosowano niemal identyczny sposób kodowania cyfr, z tą różnicą, że pierwsza (czyli ta dodatkowa cyfra) nie jest bezpośrednio zapisywana tak jak pozostałe, ale wpływa na zmianę schematu używanych kombinacji pasków. W przypadku, gdy pierwszą cyfrą jest 0, schemat zapisu pozostałych cyfr jest identyczny, jak w kodzie UPC-A.
Jeśli natomiast pierwsza cyfra jest inna, niektóre z cyfr w lewej połowie pozostałego kodu są zapisywane z użyciem kodów z parzystą sumą szerokości czarnych pasków - na analogicznej zasadzie, jak w UPC-E. Cyfry w prawej połowie kodu zawsze są zapisywane w ten sam sposób, identyczny jak w UPC-A. Tabela 3 zawiera opis sposobu kodowania cyfr EAN-13, w zależności od wartości pierwszej cyfry (rysunek 4).
Przykładowo, jeśli pierwszą cyfrą ma być 4, cyfry w lewej części kodu będą zapisywane z użyciem kolejno kodów LGLLGG (zgodnie z tabelą 3), a te w prawej części z użyciem kodów RRRRRR. Warto zauważyć podobieństwo do sposobu kodowania cyfr w UPC-E w zależności od wartości cyfry kontrolnej, w sytuacji gdy pierwsza cyfra odpowiadającego mu UPC-A to 0. Znaczenie kodów L, G i R zostało zademonstrowane w tabeli 4.

Rysunek 5. Treść "1234567890128" zakodowana w postaci kodu EAN-13
Twórcy systemu EAN również mieli świadomość ograniczeń dostępnej przestrzeni na niektórych przedmiotach wprowadzanych do sprzedaży i przygotowali skróconą wersję kodu w EAN-13 w postaci EAN-8 (rysunek 5). Kody EAN-8 nie są jednak kompatybilne w jakikolwiek sposób z UPC i nie rozwijają się do pełnych kodów EAN-13, choć budowane są na tej samej zasadzie, co zwykłe kody UPC, z tą różnicą, że zamiast po 6 cyfr po każdej stronie znaku środka, mają tylko po 4 cyfry (łącznie 8 cyfr).
Zarówno kody EAN-13, jak i EAN-8 zawierają cyfrę kontrolną. Konieczne jednak było zmodyfikowanie algorytmu jej obliczania, w stosunku do kodów UPC-A, tak by uwzględniał dodatkową cyfrę z EAN-13, a jednocześnie by obliczana wartość dla tej cyfry równej zeru była taka sama, jak w przypadku odpowiadającego kodowi EAN-13 kodu UPC-A.

Rysunek 6. Treść "2578463" zakodowana w postaci kodu EAN-8
W EAN, podobnie jak w UPC, co druga cyfra jest mnożona przez trzy, wyniki mnożeń są sumowane a następnie dodawane są do tego pozostałe cyfry. Całkowitą sumę dzieli się przez dziesięć i bierze z tego resztę, a następnie, jeśli jest to wartość różna od 0, odejmuje ją od 10, uzyskując w ten sposób cyfrę kontrolną. Różnica polega na tym, które cyfry mnożone są przez 3, a które nie.
Uniwersalna zasada polega na tym, że przedostatnia cyfra kodu (a więc ostatnia, która nie jest cyfrą kontrolną) jest mnożona przez 3, a następnie począwszy od niej, liczona jest co druga, która będzie także mnożona przez 3. Oznacza to, że w przypadku kodu EAN-13, pierwsza cyfra nie jest mnożona przez 3, a druga, będąca pierwszą cyfrą ewentualnego odpowiednika w postaci UPC-A już tak. W przypadku kodu EAN-8, pierwsza cyfra jest mnożona przez 3. Ta sama zasada obowiązuje w przypadku odmiany EAN-18, określanej też mianami SSCC-18 (Serial Shipping Container Code) lub NVE (Nummer der Versandeinheit), a stosowanej w logistyce.
Postać kodów GTIN

Rysunek 7. Treść "990222578463" zakodowana w postaci kodu EAN-99
Choć z punktu widzenia elektronika nie ma znaczenia, co reprezentują wartości w skanowanych kodach EAN i UPC, warto wiedzieć, dlaczego nie należy swobodnie, w sobie znany sposób, umieszczać takich kodów na produktach (choć niektórzy producenci tak robią), które mogą znaleźć się w sprzedaży detalicznej. Kody EAN i UPC mogą być świetnym sposobem na zapisania ciągu liczb, ale w praktyce reprezentują numery GTIN, przydzielane przez organizację GS1.
W przypadku numeru GTIN-13 zapisywanego w postaci EAN-13, pierwsze trzy cyfry określają narodową organizację, do której producent towaru wystąpił o przydzielenie puli kodów. Jeśli kod EAN-13 jest użyty do zapisania numeru ISBN (bywa wtedy nazywany mianem BookLand), pierwsze trzy cyfry będą miały wartość 978 lub 979 (dla nowszych publikacji), w przypadku numerów ISSN, pierwsze trzy cyfry również będą sprowadzały się do 979, a w dla czasopism, posiadających numer ISSN, prefiks to 977.
Drugi blok cyfr, o długości od trzech do ośmiu pozycji, to identyfikator producenta. Producenci wytwarzający szeroki asortyment dóbr wykupują (odpowiednio droższe) pule numerów, w których wspomniany blok ten jest krótki, podczas gdy mali wytwórcy rejestrują tańsze pule z długim blokiem.
Następne dwie do sześciu cyfr (w zależności od długości poprzedniego bloku) służą do oznaczania indywidualnych towarów. Ostatnia cyfra, to wspomniana wcześniej cyfra kontrolna, obliczana zgodnie z podanym algorytmem.
Organizacja GS1 zarezerwowała także pule numerów przeznaczonych do zastosowań wewnętrznych w firmach, a więc nie do wprowadzania do powszechnej dystrybucji. Kody te nie powinny być mylone z kodami produktów wprowadzonych do sprzedaży detalicznej w różnych sklepach.

Rysunek 8. Treść "257846" zakodowana w postaci kodu EAN-Velocity
Jako ciekawostkę można wspomnieć, że kody EAN-13, zaczynające się od cyfr 99, zostały określone mianem EAN-99 (rysunek 7) i zarezerwowane przez GS1 na rzecz kuponów emitowanych i używanych tylko w ramach jednej jednostki - np. sklepu.
Kody GTIN EAN-13, wydawane w USA, ze względu na zgodność z UPC-A, zaczynają się od zera. Ponadto przygotowano też zestaw numerów GTIN do innych potrzeb - np. do oznaczania małych produktów z użyciem EAN-8. W przypadku tych ostatnich, kody zaczynające się od zera noszą miano EAN-Velocity (rysunek 8) i są przeznaczone do znakowania towarów na potrzeby sprzedaży detalicznej, w sytuacji gdy producent towaru nie oznakował go numerem GTIN. Kody EAN-Velocity mogą być używane tylko w ramach jednostki, która je wyemitowała.
Czasem można się spotkać z kodami określanymi mianem JAN, które są identyczne z EAN-13, ale nazwa JAN dotyczy kodów stosowanych w Japonii. Ich wyróżnienie wynika z faktu tamtejszej ogromnej popularności kodów kreskowych - Japonii przypisane są 2 różne kody krajów (49 i 45).
Warto też wspomnieć o kodach EAN 2 i EAN 5, które są używane jako rozszerzenie EAN-13, dodatkowo do oznaczania numerów wydania lub sugerowanej ceny detalicznej. Kod EAN-13 z kodem EAN 2 można znaleźć na okładce Elektroniki Praktycznej.

Rysunek 9. Treść "9771230352153:04" zakodowana w postaci kodu ISSN + 2
W 5-cyfrowym kodzie EAN 5 pierwsza cyfra standardowo reprezentuje walutę (np. piątka - dolara amerykańskiego), a kolejne cztery cyfry to sugerowana cena wyrażona w setnych częściach waluty (w przypadku dolara - w centach). Kody EAN 2 i EAN 5 zapisywane są z użyciem takich samych kombinacji pasków, jak w przypadku kodu EAN-13, z tym że dodatkowo stosowane są paski separatorów, a kontrola parzystości realizowana jest w postaci zmiany rodzaju używanych kombinacji pasków na poszczególnych pozycjach.
W końcu, należy też wspomnieć o standardowym sposobie drukowania kodów EAN-13, EAN-8, UPC-A i UPC-E. W każdym z tych przypadków, znaki startu i stopu oraz znak środka (jeśli występuje) są dłuższe (wystają w dół), niż pozostałe. Dodatkowo, tylko w UPC-A, znaki dla pierwszej i ostatniej cyfry również są dłuższe i równe długością znakom startu i stopu.
W praktyce konieczne jest też drukowanie cyfr zawartych w kodzie, by w razie niemożności zautomatyzowanego zeskanowania kodu, można było go odczytać i wprowadzić ręcznie. Tu została przyjęta praktyka, która jednocześnie zabezpiecza kod przed wydrukowaniem go bez obowiązkowych marginesów. W przypadku 12-cyfrowego kodu UPC-A, skrajne cyfry znajdują się na zewnątrz kodu, rozszerzając tym samym cały piktogram.

Rysunek 10. Treść "9788360233702:12345" zakodowana w postaci kodu ISBN + 5
Pozostałe cyfry umieszczane są po 5, pomiędzy paskami pierwszej cyfry, środka i ostatniej cyfry. W kodach EAN-13, pierwsza cyfra jest na zewnątrz po lewej, pomiędzy paskami startu, środka i końca umieszczone są dwie grupy po 6 cyfr, a za znakiem końca umieszczany jest znak ">", który wraz z pierwszą cyfrą, zapewnia zachowanie marginesu.
W kodach UPC-E skrajne znaki umieszczone są na zewnątrz kodu, w celu zachowania marginesów, a w kodzie EAN-8 praktykuje się dodanie znaków "<" i ">" na zewnątrz kodu, podczas gdy pozostałe 8 cyfr jest umieszczonych w grupach po cztery, pod kodem.
Przykłady kodów ISSN+2 i ISBN+5 pokazano na rysunkach 9 i 10.
Code 39

Rysunek 11. Treść "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu Code 39
Bardzo popularnym kodem jest Code 39, opracowany w latach siedemdziesiątych ubiegłego wieku przez pracowników firmy Intermec (rysunek 11, rysunek 12). Code 39 nazywany jest też mianem Code 3 of 9 oraz został ustandaryzowany jako ISO/IEC 16388. Nazwa kodu ma podwójne znaczenie.

Rysunek 12. Treść "0222578463" zakodowana w postaci kodu Code 39
Po pierwsze, Code 39 w pierwotnej wersji pozwalał na zapisanie dowolnie długiego ciągu 39 różnych znaków: 26 liter, 10 cyfr i trzech znaków przestankowych: kropki, myślnika i spacji. Jednocześnie, każdemu z tych znaków odpowiadało 9 pasków (białych lub czarnych), z których trzy były grube, a pozostałe sześć - cienkie.
Pasek rozpoznawany jest jako gruby, jeśli jest 2-3 razy grubszy niż pasek cienki (nazywany też pojedynczym segmentem). Dodatkowo zdefiniowano znak startu i końca, który dzięki temu, że jest asymetryczny, pozwala na wykrycie, czy kod nie jest odczytywany "do góry nogami".
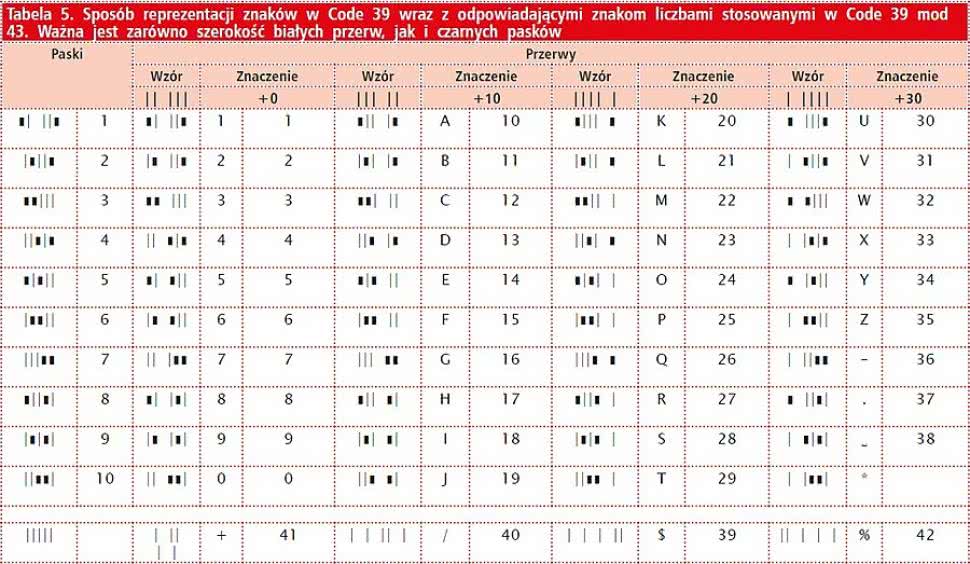
Tabela 5. Sposób reprezentacji znaków w Code 39 wraz z odpowiadającymi znakom liczbami stosowanymi w Code 39 mod 43. Ważna jest zarówno szerokość białych przerw, jak i czarnych pasków
W Code 39 nie przewidziano specjalnej cyfry kontrolnej, ale zamiast tego paski dla poszczególnych znaków zaprojektowano tak, aby można było łatwo sprawdzić, czy w trakcie ich skanowania nie wkradł się błąd. Wszystkie znaki zawierają dwa grube czarne paski i jeden gruby biały oraz po trzy cienkie białe i czarne.
Tak zdefiniowany kod (tabela 5) jest dosyć redundantny, a niewielka liczba dopuszczalnych znaków niweczyła sens stosowania Code 39 w wielu sytuacjach. Dlatego po pewnym czasie wprowadzono rozszerzenie o cztery dodatkowe znaki: plus, slash, dolar i procent, kodowane z użyciem trzech białych grubych pasków, jednego białego cienkiego i pięciu czarnych, cienkich.

Tabela 6. Sposób kodowania znaków w Full ASCII Code 39
Ponieważ kod odpowiadający każdemu zapisywanemu znakowi jest niezależny od pozycji oraz w Code 39 nie ma cyfry kontrolnej, wprowadzenie drukowania tych kodów jest bardzo proste - wystarczy skorzystać z odpowiedniej czcionki, która dla poszczególnych znaków będzie miała przypisane odpowiednie kody graficzne. Pomiędzy znakami w Code 39 muszą znaleźć się pojedyncze przerwy, a znaki startu i stopu są standardowo przypisywane symbolowi gwiazdki (*).
Z czasem pojawiły się też trzy kolejne modyfikacje zmodyfikowanego wcześniej Code 39. Pierwsza z nich obejmowała wprowadzenie cyfry kontrolnej (Code 39 mod 43). By ją policzyć, konieczne jest przypisanie wszystkim 43 znakom rozszerzonego Code 39 wartości od 0 do 42, a następnie zsumowanie tych wartości odpowiadającym znakom w zapisanym kodzie i obliczeniu reszty z dzielenia takiej sumy przez 43.
Reszta ta powinna zostać zapisana na koniec ciągu znaków, w postaci kodu odpowiadającemu znakowi o przypisanej wcześniej wartości równej obliczonej reszcie. Odczyt takiego formatu kodu, tj. sprawdzanie poprawności liczby kontrolnej wymaga zazwyczaj włączenia odpowiedniej opcji w skanerze kodów.
Znacznie ciekawszą modyfikacją jest Full ASCII Code 39 (nazywana też Code 39 Extended), w którym wprowadzono obsługę wszystkich 128 znaków ASCII (dla Code 39 Extended również można obliczać sumę kontrolną mod 43).

Rysunek 13. Treść "0222578463" zakodowana w postaci kodu Code 11
Wielkie litery, cyfry oraz kropka, myślnik i spacja są zapisywane w sposób identyczny jak w Code 39, a pozostałe znaki ASCII składają się z dwóch sąsiadujących znaków Code 39, rozpoczynających się od procenta, slasha lub plusa (tabela 6). Warto przy tym dodać, że choć znak startu i stopu pozostał bez zmian, wprowadzono dodatkowy znak gwiazdki, reprezentowany sąsiadującymi ze sobą symbolami slasha i dużej litery J.
Oczywiście oznacza to, że do zapisu małych liter oraz wcześniej niedostępnych znaków ASCII konieczne jest użycie łącznie 18 pasków (w tym 6 grubych), podzielonych na dwie grupy, oddzielone od siebie białą przerwą. W efekcie kod ten, jak i zresztą cały Code 39, charakteryzuje się małą gęstością upakowania danych.
Niemniej, ze względu na swoją popularność, jest wciąż bardzo chętnie wykorzystywany, szczególnie w starszych aplikacjach. Jeszcze inną odmianą jest Code 39 Reduced, w którym dostępne są tylko znaki alfanumeryczne, bez przestankowych, co skutkuje pulą 36 różnych znaków. Znak kontrolny w Code 39 Reduced oblicza się modulo 36.

Rysunek 14. Treść "22-257-84-63" zakodowana w postaci kodu Code 11
Na podobnej zasadzie do Code 39, ta sama firma opracowała Code 11, przeznaczony do zapisu numerów telefonów (rysunek 13). W Code 11 dostępne jest 10 cyfr, znak myślnika oraz znak startu/stopu (rysunek 14). Każdy ze znaków zapisywany jest za pomocą trzech pasków czarnych i dwóch białych.
Niektóre znaki mają dwa szerokie czarne paski, a pozostałe tylko po jednym. Mogą też mieć szerokie białe paski. Wszystkie znaki są od siebie oddzielane pojedynczą białą przerwą. Standard przewiduje też możliwość dodawania jednej lub dwóch cyfr kontrolnych. Wykaz znaków dostępnych w Code 11 umieszczono w tabeli 7.
Code 93

Rysunek 15. Treść "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu Code 93
Inżynierowie z Intermec zdawali sobie sprawę, że ich Code 39 trudno nazwać oszczędnym. Dlatego na początku lat 80. opracowali Code 93, który ponadto miał się cechować lepszym zabezpieczeniem odczytu. Code 93, w odróżnieniu od Code 39 nie składa się z pasków o dwóch różnych szerokościach, ale tak jak kody UPC i EAN, z pasków o długościach równych maksymalnie czterokrotnej wielokrotności najcieńszego paska (pojedynczego segmentu).
Każdy znak zawiera trzy paski czarne i trzy białe, których łączna szerokość wynosi 9 segmentów. Przy założeniu, że rozdzielczość czytnika takiego kodu jest taka sama, jak przy odczycie Code 39, oznacza to, że w Code 93 każdy ze znaków zajmuje w praktyce o kilka szerokości najcieńszego paska mniej.
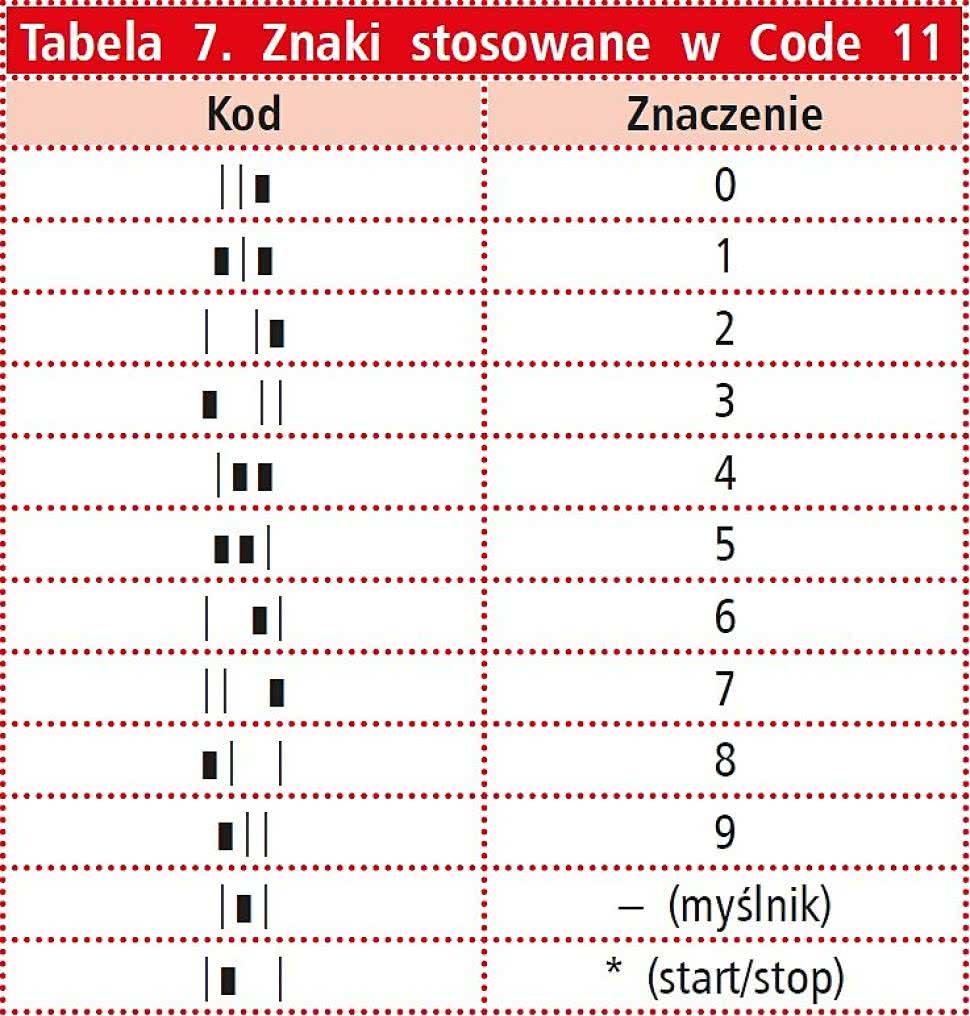
Tabela 7. Znaki stosowane w Code 11 |
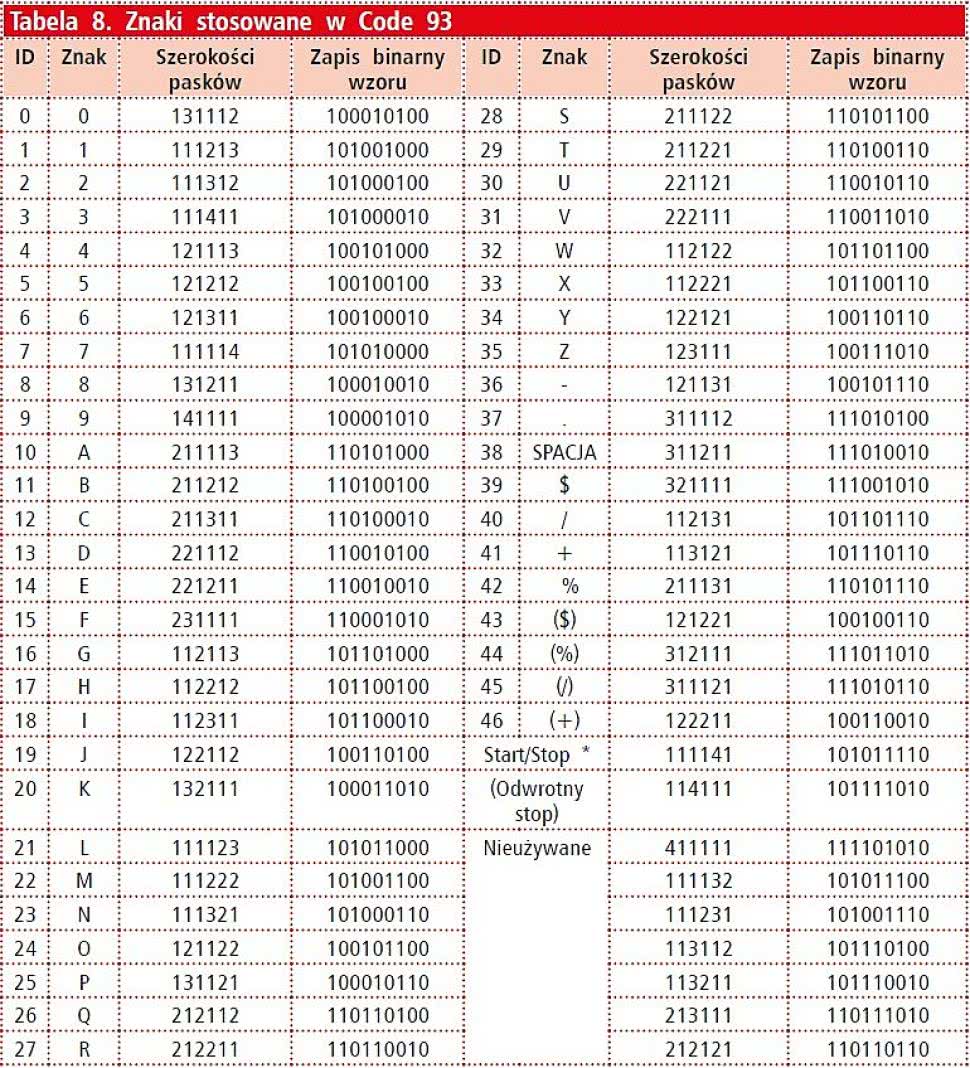
Tabela 8. Znaki stosowane w Code 93 |
Ponadto w standardowym Code 93 uwzględniono 26 dużych liter, 10 cyfr i 7 znaków specjalnych: myślnik, kropkę, dolar, slash, plus, procent i spację. Przestrzeń dopuszczalnych kombinacji kodów, zgodna z opisanymi regułami i zaczynających się od czarnego paska obejmuje 56 opcji, dlatego twórcy postanowili stworzyć kilka dodatkowych znaków, które ułatwią rozszerzenie Code 93 do obsługi pełnego zestawu znaków ASCII (Full ASCII Code 93 lub też Code 93 Extended), na podobnych zasadach, jak w przypadku Code 39 Extended.

Rysunek 16. Treść "0222578463" zakodowana w postaci kodu Code 93
Lista znaków i odpowiadających im kodów w Code 93 została zebrana w tabeli 8. Znaki Full ASCII Code 93 można obliczyć korzystając z tabeli 7 i zamieniając prefiksy "$", "%", "/" i "+" na "($)", "(%)", "(/)" i "(+)" (odpowiednio). Oznacza to zarazem, że same znaki dolara, procenta, slasha i plusa, w Code 93 Extended nie wymagają prefiksów.
Warto dodać, że w typowym Code 93, przed znakiem stopu stosuje się dwa znaki kontrolne modulo 47. Powinno się też używać przynajmniej kilkumilimetrowych marginesów po bokach. Przykłady użycia Code 93 pokazano na rysunkach 15 i 16.
Code 128

Rysunek 17. Treść "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu Code 128
Kolejnym po Code 39 i Code 93 standardem, umożliwiającym zapis znaków alfanumerycznych jest Code 128, który charakteryzuje się wyjątkowo dużą gęstością upakowania danych (rysunek 17). Jego jakość została doceniona w postaci standardu ISO/IEC 15417.
Code 128, podobnie jak Code 11, Code 39 i Code 93, obejmuje określony zestaw znaków. Są to 103 symbole danych, 3 symbole startu i dwa symbole stopu. Należy też pamiętać o pustych przestrzeniach naokoło kodu, o szerokości przynajmniej 10-krotności najcieńszego paska (pojedynczego segmentu). Poszczególne symbole składają się z trzech pasków białych i trzech czarnych.

Rysunek 18. Treść "0222578463" zakodowana w postaci kodu Code 128 Mode A
Znak stopu składa się z dwóch nachodzących na siebie symboli i ma cztery czarne paski. Znak stopu, czytany od tyłu, jest rozpoznawany jako odwrotny znak stopu, dzięki czemu skaner wie, że ma zamienić kolejność wczytanych danych. Pomimo, że Code 128 obejmuje tylko 103 symbole danych, jest w stanie zapisać wszystkie 128 znaków ASCII.
W tym celu został podzielony na trzy zbiory:
- 128A, zawierający znaki ASCII od numeru 00 do 95, a więc cyfry, duże litery, znaki kontrolne i specjalne oraz funkcyjne (rysunek 18).
- 128B, zawierający znaki ASCII od numeru 32 do 127, a więc cyfry, duże i małe litery, znaki specjalne oraz funkcyjne.
- 128C, zawierający liczby od 00 do 99 oraz jeden znak funkcyjny (rysunek 19).

Rysunek 19. Treść "0222578463" zakodowana w postaci kodu Code 128 Mode C
Co ważne, znaki funkcyjne pozwalają na przełączanie zestawów znaków w trakcie czytania kodu, dzięki czemu nie ma potrzeby stosowania podwójnych symboli dla nietypowych znaków ASCII. Tabela 9 zawiera listę dostępnych znaków w poszczególnych zbiorach kodu.
Każdy znak Code 128 (za wyjątkiem znaku stopu) zajmuje szerokość 11 segmentów, w których mieszczą się wspomniane 3 paski czarne i 3 białe. Maksymalna szerokość paska została ustalona na cztery segmenty (czterokrotność najcieńszego paska).
Przyjęto też, że wszystkie znaki muszą się zaczynać od paska czarnego, a więc kończyć na białym, dzięki czemu nie ma potrzeby stosowania dodatkowych przerw pomiędzy nimi. Daje to 108 kombinacji, z czego jedna nie jest wykorzystywana, po to by nie była mylona ze znakiem stopu, gdy ten jest czytany od tyłu. Znaki oznaczone jako "Shift A" i "Shift B" informują, że jeden następny znak w kodzie ma być traktowany jakby należał do Code 128A i Code 128B (odpowiednio).
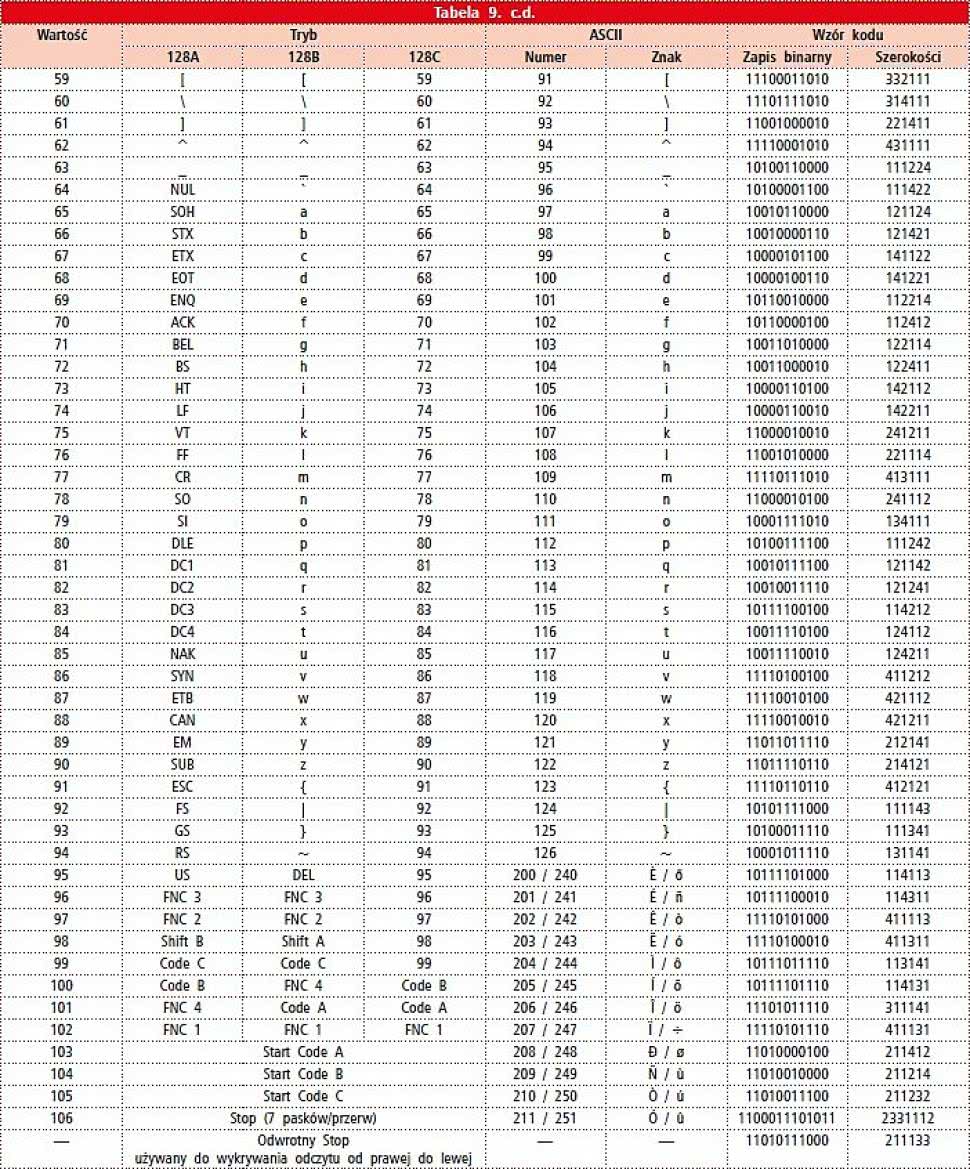
Tabela 9. Lista znaków kodu Code 128 we wszystkich jego trybach |
Znaki "Code A", "Code B" i "Code C" informują, że cały następujący po nich ciąg ma być traktowany jako zapisany w odpowiednim, innym niż dotąd z trzech zbiorów Code 128. Jeszcze inne znaczenie mają kody funkcyjne "FNC 1", "FNC 2", "FNC 3" i "FNC 4". Pierwszy z nich służy do informowania czytnika o znaczeniu zapisanej w kodzie treści, zgodnie z międzynarodowymi listami kodów.

Rysunek 20. Treść "222578463" zakodowana w postaci kodu GS1-128
Definiują one format zapisu informacji, taki jak np. sposób podania kodu pocztowego czy numeru telefonu (określają, czy użyty jest przedrostek kraju itp.). Kod "FNC 4" służy natomiast do zapisywania rozszerzonych znaków standardu ISO-8859-1 (tzw. LATIN 1) i informuje, że do wartości kodu kolejnego znaku należy dodać 128 i zinterpretować go jako kod ze zestawu znaków LATIN 1.
Dwa następujące po sobie znaki "FNC 4" informują, że wszystkie kolejne znaki mają być traktowane jako rozszerzone znaki standardu ISO-8859-1, a w przypadku gdy pojawią się w momencie gdy już są tak traktowane, stanowią komendę do powrócenia do normalnego odczytu kodów.
Warto zwrócić szczególną uwagę na Code 128C, który jest bardzo przydatny do zapisu ciągów numerycznych. Pozwala na niemal dwukrotne skrócenie długości kodu, dzięki czemu możliwe jest generowanie i poprawne skanowanie istotnie dłuższych ciągów znaków niż np. w przypadku Code 93.

Rysunek 21. Treść "(22)2578463" zakodowana w postaci kodu GS1-128
Wystarczy użyć znaku startu "Start C" lub jeśli ciąg numeryczny zaczyna się dopiero w środku kodu, przełączyć odczytywany zbiór znakiem "Code C". Jednakże w części numerów nie da się zapisać w całości z użyciem jedynie Code 128C - tych, które zawierają nieparzystą liczbę znaków.
Code 128 obejmuje też obowiązkowy znak kontrolny. Liczony jest on jako reszta z dzielenia przez 103 sumy iloczynów numerów pozycji znaków w kodzie i wartości kodów tych znaków, powiększonej o wartość kodu zastosowanego znaku startu.
Oznacza to, że ponieważ wszystkie znaki mają wygląd niezależny od ich pozycji w ciągu, podobnie jak w Code 93 możliwe jest generowanie kodów Code 128 z użyciem odpowiedniej czcionki, o ile tylko następnie obliczona zostanie i dodana na koniec takiego ciągu, przed znakiem stopu, liczba kontrolna w postaci odpowiedniego znaku.
GS1-128

Rysunek 22. Treść "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu GS1-128
Specyficznie skodyfikowanym podzbiorem Code 128 jest GS1-128, znany też jako EAN/ UCC-128. Wymaga on korzystania z znaku "FNC 1" do informowania o znaczeniu zakodowanego ciągu znaków, w oparciu o Identyfikatory Aplikacji GS1 (GS1 Application Identifiers).
Identyfikatory te mają długość od 2 znaków wzwyż i mogą informować, że następujące po nich znaki przechowują np. datę ważności, numer kontenera, numer seryjny, datę pakowania, gęstość, kwotę pieniężną, walutę, trasę, adres, kod kraju, wymiary, numer konta bankowego lub dane zapisane zgodnie z wewnętrznymi procedurami firmy, która kod stworzyła.
Zwyczajowo, kody Identyfikatorów Aplikacji, są zapisywane w nawiasach, wraz z resztą kodu (już poza nawiasami), w postaci czytelnej dla człowieka, pod paskami. Fakt, że Code 128 cechuje się dobrym upakowaniem ciągów liczb sprawia, że kody GS1-128 bardzo dobrze nadają się do reprezentacji wartości numerycznych.
Ciekawostką jest, że Identyfikator Aplikacji o wartości 01 oznacza, że następujące po nim 13 znaków to cyfry numeru GTIN, a więc powszechnie zapisywanego w kodach EAN-13, EAN-8 i UPC, a ostatnia, 14. (łącznie 16.) to cyfra kontrolna. Kod ten ma swoje osobne miano: GTIN-14 lub EAN-14.
Przykłady użycia kodu GSI-128 pokazano na rysunkach 20...22.
Marcin Karbowniczek, EP


































