Zaloguj
Zaloguj





Tabela 10. Sposób kodowania cyfr (kolejność wag) w różnych rodzajach kodów typu 2 z 5. Waga 0 jest też czasem oznaczana jako waga P, tj. parzystości
Czytelników zorientowanych w telekomunikacji i szczegółach technologicznych niektórych interfejsów komunikacyjnych czy w informatyce może zastanawiać, dlaczego nie próbowano przygotować kodu kreskowego, który odzwierciedlałby stosowane w technice kodowanie "2 z 5", nadające się do reprezentacji cyfr systemu dziesiętnego, proste w użyciu, a także pozwalające na 100-procentowe wykrywanie błędów pojedynczych, potrójnych i pięciokrotnych oraz 40-procentowe wykrywanie błędów podwójnych i poczwórnych. W istocie, to popularne rozwiązanie znalazło zastosowanie w postaci kodu Code 25 czy po prostu kod "dwa z pięciu", przy czym istnieją jego różne implementacje, w których jedynki i zera są różnie oznaczane.
2 z 5 (Industrial 2of5)
Znaczenie symboli kodu "2 z 5", stosowanego powszechnie w technice, zostało przedstawione w tabeli 10. W skrócie: każda cyfra dziesiętna jest zapisywana na pięciu bitach, z czego dwa są jedynkami, a pozostałe to zera. Wartość cyfry zależy od pozycji jedynek, które to pozycje odpowiadają dodawanym do siebie wagom, zgodnie z tabelą 10. Jedynki mogą być kodowane jako czarne paski szerokie, a zera jako czarne paski wąskie (najczęściej 2-3-krotnie węższe niż szerokie). Oczywiście, pomiędzy paskami czarnymi konieczne jest umieszczenie cienkich pasków białych, by te czarne się ze sobą nie zlewały. Tak wydrukowany kod nie zawiera znaków startu i kodu ani cyfry kontrolnej, więc jego odczyt, choć cechuje się dużą

Rysunek 23. Treśc "0222578463" zakodowana w postaci kodu Industrial 2of5
Na tej samej zasadzie opracowano stosowane w poczcie kody POSTNET (rysunek 24) i PLANET (rysunek 25) z tym, że nie używa się w nich węższych i szerszych pasków, ale wyższe i niższe. W POSTNET wyższe to jedynki, a w PLANET jest odwrotnie. Wszystkie paski są umieszczone z przerwami obok siebie i wyrównane do dołu, przy czym paski wyższe są 2-krotnie dłuższe niż paski niższe.
|
Rysunek 24. Treśc "03197" zakodowana w postaci kodu POSTNET 5 |
Rysunek 25. Treśc "00222578463" zakodowana w postaci kodu PLANET |

Tabela 11. Wygląd kodów typu 2 z 5. Symbole niektórych kodów bazujących na 2 z 5. W przypadku Code 25, IATA 2of5 i Industrial 2of5, jedynka oznaczana jest grubym paskiem, a zero cienkim. W przypadku POSTNET jedynka oznaczana jest wysokim paskiem, a zero niskim. W kodzie PLANET - odwrotnie. W przypadku kodów Matrix 2of5 i COOP 2of5 jedynka jest oznaczana szerokim czarnym lub białym paskiem (zależnie od wagi), a zero wąskim czarnym lub białym paskiem (również zależnie od wagi)
Standardowo kod POSTNET służy do zapisu kodu pocztowego wraz z cyfrą kontrolną, podawanego w różnych formatach (amerykańskie rozszerzone kody pocztowe mają 9 cyfr). Kody POSTNET można znaleźć na starszych listach z USA. Kod PLANET był natomiast używany do logistyki na poczcie. Niedawno oba kody zostały wyparte przez bardziej zaawansowany kod Intelligent Mail Barcode. Ciekawostką jest kod Inverted 2of5, który jest tworzony tak samo jak klasyczny Code 25, z tą różnicą, że kolory pasków są odwrócone. Wnikliwi czytelnicy mogą zauważyć, że w przypadku kodów kreskowych w pewnym sensie dostępnych jest nieco więcej możliwości kodowania znaków niż w technice cyfrowej, gdyż zarówno czarne, jak i białe paski mogą być szerokie lub wąskie. Oznacza to, że przerwy pomiędzy bitami kodu 2 z 5 również mogą coś reprezentować, co pozwoliłoby gęściej upakować dane, praktycznie bez strat w pewności odczytu. Idąc tym tropem, stworzono trzy dodatkowe kody bazujące na 2 z 5.

Rysunek 26. Treśc "0222578463" zakodowana w postaci kodu Matrix 2of5
Dwa bardzo podobne do siebie to Matrix 2of5 i COOP 2of5 (rysunek 26). Bazują one na odwrotnych systemach wag (tabela 10), ale korzystają z tego samego założenia: każda cyfra jest kodowana za pomocą dwóch długie elementów i trzech krótkich, przy czym długie lub krótkie mogą być zarówno czarne paski, jak i przerwy pomiędzy nimi. Wiadomo tylko, że każda cyfra zaczyna się od czarnego paska i czarnym kończy, a więc składa się z trzech czarnych pasków i dwóch przerw. Wszystkie dopuszczalne kombinacje zostały zawarte w tabeli 11. Kody Matrix 2of5 i COOP 2of5 różnią się znakami startu i stopu. W Matrix 2of5: znak startu i stopu to 10 000, cyfra kontrolna jest opcjonalna, długość kodu jest dowolna. W COOP 2of5: znak startu to: 101, znak stopu to: 011, cyfra kontrolna jest opcjonalna, najczęściej stosowany jest kod 4-cyfrowy. Odmiana Matrix 2of5 ze zmienionymi znakami startu i stopu jest stosowana przez chińską pocztę i zwyczajowo nazywana China Postal Code, Chinese 25 albo Datalogic 2of5.

Rysunek 27. Treśc "0222578463" zakodowana w postaci kodu Interleaved 2 of 5
W latach siedemdziesiątych ubiegłego wieku opracowano też kod ITF, czyli "Interleaved Two of Five", tj. "Przeplatany 2 z 5" (rysunek 27). W kodzie tym jedynki oznaczane są szerokimi paskami, a zera wąskimi, przy czym cyfry kodowane są parami. Cyfry na nieparzystych pozycjach reprezentowane są przez paski czarne, a na parzystych przez paski białe. Paski szerokie muszą być 2-3-krotnie szersze niż wąskie. Wagi dla cyfr są takie, jak w tabeli 10.
Ponieważ cyfry kodowane są parami, ITF może zostać użyty teoretycznie tylko do ciągów cyfr o parzystej liczbie wyrazów. W praktyce, w przypadku ciągów o nieparzystej liczbie albo przed całym kodem dostawiane jest zero, by wydłużyć ciąg cyfr o jedną, albo ostatnia cyfra jest kodowana z użyciem wszystkich białych przerw pojedynczej długości. Symbol dla dwóch cyfr składa się więc z 5 czarnych pasków (z czego dwa są szerokie, na tej samej zasadzie jak w Industrial 2of5) i 5 przeplatanych z nimi białych pasków, z których dwa są szerokie również w oparciu na tej samej zasadzie).

Rysunek 28. Treśc "0000222578463" zakodowana w postaci kodu ITF-14
Kod "Przeplatane 2 z 5" został w praktyce zastosowany w wielu aplikacjach, w których określono dodatkowe zasady drukowania kodu. Jednym z takich przykładów jest ITF-14 (rysunek 28), który zaproponowała wspomniana już wcześniej organizacja GS1 do przechowywania numerów GTIN produktów na opakowaniach zbiorczych.
Kod ten został wybrany, ponieważ dobrze się sprawdza, nawet gdy jest nadrukowany na grubym kartonie, a takie właśnie są często opakowania zbiorcze. Ponadto, by mieć pewność, że został poprawnie nadrukowany, ITF-14 wymaga zachowania odpowiednio dużych odstępów po lewej i prawej stronie oraz grubej ramki naokoło kodu, która utrudnia błędne zeskanowanie i pozwala łatwo zauważyć, czy kod się poprawnie wydrukował. Kod ITF-14, jak sama nazwa wskazuje, zawiera 14 cyfr, podczas gdy numery GTIN są 13-cyfrowe. Pierwsza cyfra ITF-14 symbolizuje odmianę wersji opakowania zbiorczego.
ITF został także użyty do znakowania rolek klisz fotograficznych oraz samych klisz - na pomysł ten wpadła firma Kodak, tworząc format DX (Digital IndeX), który stał się standardem ANSI. Na kod DX składają się trzy rodzaje kodów:
- 6-cyfrowy numer, zakodowany z użyciem ITF, umieszczany na obudowie rolki i informujący o producencie, wersji kliszy i pojemności.
- Nietypowy kod drukowany na brzegach kliszy i umożliwiający nie tylko rozpoznanie producenta, ale też m.in. numeru klatki oraz synchronizację jej pozycji.
- Duży kod, złożony z dwóch rzędów kwadratów, informujący o czułości i pojemności kliszy, zakodowany w sposób arbitralnie ustalony przez firmę Kodak.
W końcu ITF znalazł też zastosowanie na poczcie - w Niemczech jest używany do prezentowania numerów w formacie Identcode i Leitcode.
Pozostałe kody pocztowe
Kody kreskowe są powszechnie stosowane w sortowniach pocztowych. Oprócz wymienionych już standardów POSTNET, PLANET, Chinese 25, Identcode (rysunek 29) i Leitcode (rysunek 30), na rynku funkcjonuje jeszcze kilka innych. Kody paskowe opracowane na potrzeby poczty, ze względu na to, że są nadrukowywane na korespondencję, cechują się najczęściej delikatnym wyglądem i mogą znaleźć zastosowanie też tam, gdzie kod powinien nie być zbytnio widoczny. Co więcej, często są nadrukowywane słabo widocznym dla gołego oka, ale fluorescencyjnym tuszem, by można je było odczytać przy odpowiednim świetle.

Rysunek 29. Treśc "00222578463" zakodowana w postaci kodu Identcode |

Rysunek 30. Treśc "0000222578463" zakodowana w postaci kodu Leitcode |
Dobrym przykładem jest nietypowy, bo binarny, kanadyjski kod CPC, w którym zapisywany jest m.in. kod pocztowy adresata. Kanadyjskie kody pocztowe mają 6 znaków alfanumerycznych, które - by zapisać w postaci CPC, dzieli się najpierw na cztery sekcje. Sposób kodowania poszczególnych sekcji został określony w postaci tabelarycznej, której nie przytaczamy w artykule. W ogólności polega ona na przypisaniu pierwszej i ostatniej sekcji po jednej 8-bitowej liczbie, jedną 5-bitową liczbę sekcji drugiej oraz jedną 4-bitową liczbę sekcji trzeciej. Następnie liczby te są zestawiane obok siebie w postaci binarnej, w kolejności sekcji. Jedynki drukowane są jako pionowe kreski kolorowe, a zera jako puste przestrzenie. Aby uniknąć problemu związanego z liczeniem pustych przestrzeni, na końcu kodu dodawana jest jedynka, zapewniając tym samym wyrównanie kodu paskowego do prawej, a następnie zliczana jest liczba jedynek zastosowanych w kodzie. Jeśli jest parzysta, na przodzie kodu dodaje się jeszcze jedną jedynkę.
W identyczny sposób zapisywane są zera i jedynki w kodzie kreskowym FIM (Facing Identification Mark), używanym przez amerykański urząd pocztowy z tą różnicą, że jest on zawsze nadrukowywany na koperty czarnym tuszem. Kod FIM, pomimo że zapisuje zawsze 9-bitowy ciąg, reprezentuje tylko 5 wartości, określających typ listu. Aby kod ten był czytelny z każdej strony, wszystkie ciągi znaków są symetryczne względem piątego bitu.

Rysunek 31. Treśc "222578463" zakodowana w postaci kodu KIX |

Rysunek 32. Treśc "222578463" zakodowana w postaci kodu RM4SCC |
Nieco bardziej skomplikowane są kody DAFT Code, Japanese Postal Code, Dutch Post KIX Code (rysunek 31)/Royal Mail 4-State Customer Code (RM4SCC - rysunek 32) i Intelligent Mail barcode.

Tabela 12. Symbole kodu RM4SCC
Kod RM4SCC, używany w Wielkiej Brytanii oraz kod KIX (różniący się głównie brakiem znaków startu, stopu i sum kontrolnej) obejmuje 36 znaków alfanumerycznych oraz znak stopu i startu. Każdy ze znaków alfanumerycznych składa się z czterech pasków, przy czym każdy pasek może mieć cztery postaci: krótki, długi w górę, długi w dół oraz długi w górę i w dół. Zostały one pokazane w tabeli 12, wraz ze znakami startu i stopu. RM4SCC jest używany do zapisu kodu pocztowego i jego rozszerzenia, wraz z cyfrą kontrolną.
Niemal takie same rodzaje pasków ma kod Intelligent Mail barcode, który niedawno całkowicie zastąpił starsze kody kreskowe używane na poczcie w USA. Kod ten zawsze składa się z 65 kresek i obejmuje takie informacje, jak identyfikator kodu, typ usługi, identyfikator nadawcy, numer sekwencyjny oraz kod pocztowy adresata. Użyteczna pojemność kodu wynosi 103 bity, zapewniając przy tym detekcję pojedynczych błędów oraz obsługę cyfry kontrolnej.
Kody farmaceutyczne
Kody kreskowe mają też niemałe znaczenie w przemyśle farmaceutycznym, gdzie konieczne jest zarówno kontrolowanie wydawania leków, jak i poprawne ich oznaczanie, tak by trudno je było ze sobą pomylić. Jednym z zastosowań jest nawet sprawdzanie, czy informacje o leku zostały poprawnie naniesione na opakowanie lub ulotkę - zakłada się, że jeśli kod paskowy drukowany tą samą farbą co ważne informacje jest poprawny, to znaczy, że pozostały tekst też jest czytelny.
Powszechnie wykorzystywanym w tym celu standardem w farmaceutyce jest Pharmoacode, który występuje w dwóch wersjach: One Track i Two Track. Oba służą do zapisywania liczb - pierwszy pozwala na zakodowanie liczb naturalnych od 3 do 131070, a drugi od 4 do 64570080. Pharmacode jest binarny. W wersji One Track składa się z czarnych pasków o dwóch szerokościach, oddzielonych od siebie cienkimi białymi paskami. Kod dekoduje się od prawej do lewej, sumując kolejne liczby powstające z podniesienia dwójki do numeru pozycji, zaczynając od 0, przy czym jeśli pasek jest gruby, daną liczbę dodaje się dwukrotnie. Ponieważ kod nie może być krótszy niż dwa wąskie paski, najmniejsza kodowana liczba to 3 (20+22=3), a największa to 131070, złożona z 16 szerokich pasków.
W przypadku Pharmacode Two Track stosowane są paski tej samej szerokości, ale różniące się wysokością i położeniem (podobnie jak w kodach stosowanych w systemach pocztowych): krótki u góry, krótki u dołu i długi. Liczba 4 składa się z 2 krótkich pasków u dołu, a liczba 64570080 z 16 długich pasków. Wynika to z systemu, w którym pasek krótki dolny oznacza 3N, pasek krótki górny to 2*3N, a pasek długi to 3*3N, gdzie N to pozycja liczona od prawej, począwszy od zera.
Innym kodem stosowanym w farmaceutyce (głównie we Włoszech) jest Code 32, zwany też IMH lub Radix 32 Barcode. Zawsze zaczyna się on od litery A, po czym następuje 9 znaków. W praktyce jest odmianą Code 39, w którym dopuszczono użycie jedynie cyfr oraz liter "A", "E", "I", "O" oraz "U". Pierwsza litera "A" nie jest w ogóle kodowana, a jedynie notowana pod kodem kreskowym w postaci czytelnej dla człowieka. Ostatni znak to zazwyczaj cyfra kontrolna. Konieczne jest też zachowanie marginesów po obu stronach kodów, o długości przynajmniej 10-krotnej długości najcieńszego paska (pojedynczego segmentu).
Pozostałe, uniwersalne kody 1-wymiarowe
Choć opisane dotąd kody kreskowe odpowiadają za większość nowoczesnych aplikacji, w których wykorzystywane jest jednowymiarowe znakowanie graficzne, na rynku wciąż funkcjonuje kilka starszych standardów, których użytkowanie wynika z zaszłości historycznych, konieczności zachowania kompatybilności ze starszymi urządzeniami lub z nietypowych warunków technicznych druku. Świetnym przykładem takiego kodu jest Codabar, nazywany też czasem mianami Code-a-bar, Ames Code, NW-7 czy Monarch. Został opracowany na początku lat 70., a więc w czasach, gdy królowały drukarki igłowe. To właśnie z myślą o nich go stworzono, dzięki czemu jest dobrze czytelny, nawet jeśli zostanie wydrukowany na urządzeniu o bardzo niskiej rozdzielczości. W dawnych czasach drukowano go nawet bez użycia komputerów, na drukarkach ręcznych.

Rysunek 33. Treśc "ELEKTRONIKA" zakodowana w postaci kodu RM4SCC |

Rysunek 34. Treśc "22578463" zakodowana w postaci kodu Australijska poczta |
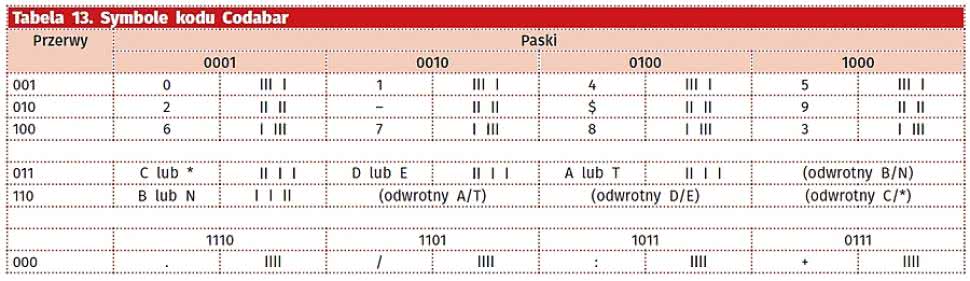
Tabela 13. Symbole kodu Codabar
Codabar pozwala na zapisywanie 16 symboli: cyfr oraz znaków "-", "$", ":", "/", ".", "A", "B", "C" i "D". Każdy znak jest kodowany w postaci 4 pasków czarnych i trzech białych, a poszczególne znaki są od siebie oddzielane białymi przerwami. Zarówno paski białe, jak i czarne mogą być wąskie lub szerokie, przy czym szerokie są (w wersji standardowej) 2,25-3 razy szersze od wąskich. Sposób kodowania poszczególnych znaków został pokazany w tabeli 13. Cyfra kontrolna raczej nie jest stosowana. Litery, które można zakodować, są w praktyce używane tylko do oznaczenia początku i końca kodu, przy czym przyjęły się różne sposoby ich wykorzystania, w zależności od obszaru zastosowania kodu. W rzeczywistości kod ten był używany do oznaczania pakietów krwi w szpitalach, do śledzenia przesyłek firmy FedEx i w wielu bibliotekach. W tej ostatniej aplikacji kod zaczynał się zawsze od "C", a kończył na "D". Co ciekawe, pierwotna specyfikacja kodu nakazywała używanie różnych proporcji szerokości szerokich pasków do wąskich, tak by cały kod, niezależnie od treści, miał dla danej liczby znaków taką samą długość. Wersja "zracjonalizowana" - Rationalized Codabar - nakazuje użycie stałej proporcji szerokości, w efekcie czego długość kodu graficznego jest zmienna, w zależności od zapisanych danych.

Rysunek 35. Treśc "222578463" zakodowana w postaci kodu Pharmacode One Track
Kolejnym, dawnym kodem uniwersalnym jest Plessey, który opracowano z myślą o przechowywaniu cyfr systemu szesnastkowego. Zastosowano prostą ideę: każda cyfra zapisana jest za pomocą czterech bitów, zgodnie z kodem binarnym, gdzie jedynki prezentowane są przez szerokie czarne paski, a zera przez wąskie czarne paski. Po każdym pasku następuje biała przerwa, której długość jest dobrana tak, by niezależnie od kodowanego bitu zajmował on tę samą szerokość.
Kod ten jest łatwy w druku na drukarkach igłowych i ma gęstsze upakowanie znaków niż niektóre inne kody. Oprócz przechowywanych danych właściwych, każdy kod Plessey zawiera znak startu (identyczny jak dla 0xB kodu szesnastkowego 16-bitową wartość kontrolną, bardzo gruby pasek końca i odwrotny kod startu (identyczny jak dla 0xC kodu szesnastkowego).

Rysunek 36. Treśc "222578463" zakodowana w postaci kodu Pharmacode Two Track
Na podstawie kodu Plessey powstał kod MSI (Modified Plessey), w którym dopuszczono jedynie umieszczanie cyfr dziesiętnych oraz odwrócono kolejność zapisu ich bitów. Znak startu składa się z jednego szerokiego czarnego paska i jednej białej cienkiej przerwy, a znak stopu z dwóch cienkich czarnych pasków i grubej przerwy pomiędzy nimi. Sposób kodowania został pokazany w tabeli 14. Zastosowano też pięć dopuszczalnych wersji liczenia cyfry kontrolnej. Inną modyfikacją Plesseya jest Anker Code, który od oryginału różni się odwrotnym sposobem liczenia cyfry kontrolnej. Anker Code był stosowany w punktach sprzedaży w Europie, zanim wprowadzono kody EAN.

Rysunek 37. Treśc "22257846" zakodowana w postaci kodu Code 32 |

Rysunek 38. Treśc "0222578463" zakodowana w postaci kodu Codabar (ze znakami startu i stopu B i D) |
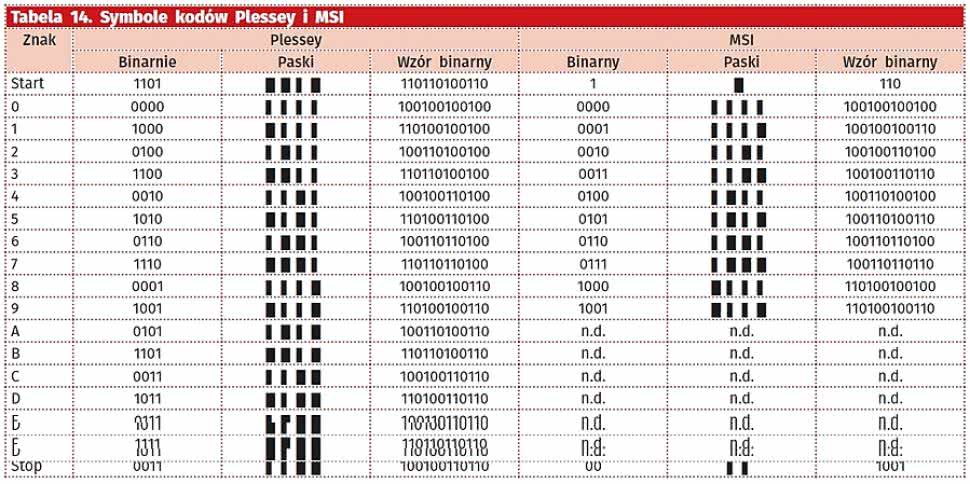
Tabela 14. Symbole kodów Plessey i MSI
Jednym z pierwszych kodów kreskowych do zapisywania wszystkich 128 znaków ASCII, bez konieczności przełączania pomiędzy zestawami alfabetów, był powstały w 1972 roku Telepen. Jest to kod binarny, w którym stosowane są tylko dwie szerokości pasków i w praktyce pozwala na zapisanie dowolnego ciągu bitów, zawierającego parzystą liczbę zer. Bajty zapisywane są w formacie little- -endian. Ciąg bitów jest dzielony na bloki złożone z pojedynczych bitów oraz z (dowolnej, nawet zerowej liczby) jedynek otoczonych pojedynczymi zerami. Następnie pojedyncza jedynka jest zapisywana jako wąski czarny pasek i wąski odstęp, dwa sąsiadujące zera są zapisywane jako szeroki czarny pasek i wąski odstęp, a ciąg "010" jako szeroki czarny pasek i szeroka przerwa. Początkowe znaki "01" oraz końcowe "10" mogą być zapisywane w identycznej postaci jako wąski pasek i szeroka przerwa. Paski i przerwy szerokie są 3-krotnie szersze niż wąskie, co oznacza, że średnio na jeden bit przypada przestrzeń o szerokości dwóch wąskich pasków. Dodatkowo, kod zawsze zaczyna się znakiem podkreślnika (bitowo: 11111010), a kończy znakiem małego "z" - czyli bitowo: 01011111. Dla całości kodu obliczana jest suma kontrolna modulo 127.

Rysunek 39. Treśc "0222578463" zakodowana w postaci kodu MSI |

Rysunek 40. Treśc "222578463" zakodowana w postaci kodu Telepen |
Bardzo prostym uniwersalnym kodem jest niemiecki FlatterMarken, stosowany np. na grzbietach książek i czasopism, który ułatwia ich sortowanie. FlatterMarken składa się z wąskich pasków - wszystkich tej samej szerokości, otoczonych białą przestrzenią. Służy do zapisywania cyfr i każda cyfra zajmuje tę samą objętość, a pozycja paska w tej przestrzeni informuje o wartości. Przykładowo, jedynka będzie miała pasek na lewym brzegu przestrzeni danej cyfry, a 9 na prawym, podczas gdy 5 pośrodku. Cyfra 0 oznacza brak czarnego paska w przestrzeni danej cyfry.

Rysunek 41. Treśc "ELEKTRONIKA" zakodowana w postaci kodu Telepen |
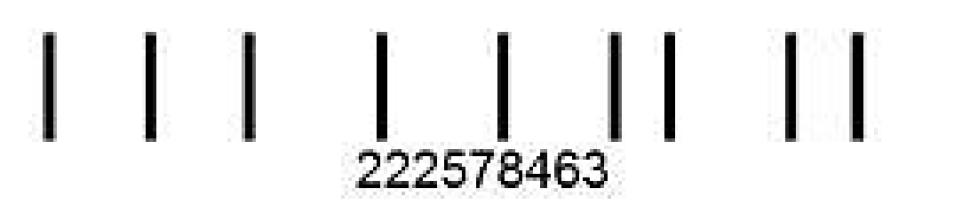
Rysunek 42. Treśc "222578463" zakodowana w postaci kodu FlatterMarken |
Ostatnim omawianym kodem uniwersalnym jest Channel Code (standard ANSI/AIM BC12 - USS Channel Code). Pozwala na zapis liczb 2-7-cyfrowych, z zakresów zależnych od długości kodu:
- 00…26,
- 000…292,
- 0000…3493,
- 00000…44072,
- 000000…576688,
- 0000000…7742862.
Omówione na końcu kody uniwersalne są używane m.in. w bibliotekach oraz w logistyce, a szczególnie w starych systemach.
GS1 DataBar
Specyficznym kodem kreskowym, który w zależności od odmiany może być traktowany już jako kod dwuwymiarowy, jest GS1 Data- Bar, opracowany przez organizację GS1. To ważny kod, który stał się standardem ISO (ISO/IEC 24724). Podstawowym celem, przyświecającym twórcom GS1 DataBar, było zwiększenie stopnia upakowania danych niż w kodach EAN oraz powiększenie ilości zapisywanych informacji, w stosunku do EAN-13. Zaobserwowano bowiem, że firmy często potrzebują dłuższych kodów, które mogłyby być swobodnie używane w sklepach, ale które zarazem nie zajmowałyby zbyt wiele przestrzeni. Tyle że w praktyce szczegóły wymagań stawianych kodom dobieranym do poszczególnych zastosowań zależą od sytuacji. W związku z powyższym, twórcy GS1 DataBar zdecydowali, że będzie on dostępny w wielu odmianach, z których część będzie można dodatkowo różnie komponować. Podstawowym kodem w tej grupie jest GS1 DataBar Omnidirectional, który mógłby bezpośrednio zastąpić kod EAN-13/EAN-14, ale jest dwukrotnie mniejszy (istnieją nawet plany, by oficjalnie zadecydować o takiej zamianie i wiele sklepów na świece jest już na to przygotowanych). GS1 DataBar składa się ze znaków startu i stopu, umieszczanych na krańcach kodu, które zarazem pełnią funkcje marginesów.
Po lewym znaku startu następuje pierwszy blok danych. Później umieszczany jest lewy znak pozycjonujący, którego wygląd zależy od cyfry kontrolnej. Po tym znaku umieszczane są następne dwa bloki danych, po których umieszczany jest prawy znak pozycjonujący (jego wygląd również zależy od cyfry kontrolnej). W końcu drukowany jest ostatni blok danych, a po nim znak stopu. W podanych 4 blokach danych zapisywane jest 14 cyfr. Skrajne bloki danych są kodowane inaczej niż środkowe - każdy z nich ma szerokość 16 najcieńszych pasków, podczas gdy bloki środkowe mają szerokości 15 najcieńszych pasków.

Rysunek 43. Treśc "257846" zakodowana w postaci kodu Channel Code |

Rysunek 44. Treśc "0123456789012" zakodowana w postaci kodu GS1 DataBar |
Na potrzeby sytuacji, gdy nawet taki kod jest zbyt duży, GS1 opracowało jego zmniejszone wersje. Jedną z nich jest GS1 DataBar Truncated, który różni się tylko znacznie mniejszym wymogiem odnośnie do wysokości kresek i w praktyce nie może być stosowany w zautomatyzowanych systemach skanowania.
W GS1 DataBar Omnidirectional wysokość kodu musi wynosić przynajmniej tyle co 33 najcieńsze paski (segmenty), podczas gdy w GS1 DataBar Truncated wystarczy wysokość 13 najcieńszych pasków.
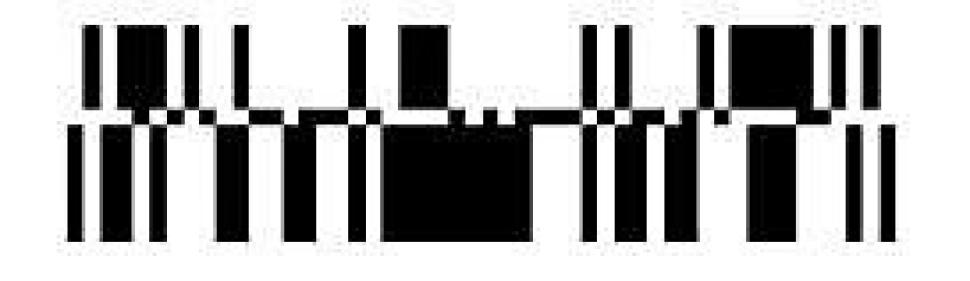
Rysunek 45. Treśc "1234567890123" zakodowana w postaci kodu GS1 DataBar Stacked
Jeśli zautomatyzowany odczyt jest konieczny, wtedy można zastosować kod GS1 DataBar Stacked Omnidirectional, który właściwie jest już kodem dwuwymiarowym, bo połowa treści jest zapisana w górnym rzędzie kodu, a połowa w dolnym. Kod ten jest wyższy niż dłuższy, co wynika z wymagań odnośnie do wysokości pasków. Pomiędzy rzędami znajduje się bardzo niski, choć trójrzędowy separator, przypominający mozaikę. Ma on uniemożliwić przypadkowe pomylenie fragmentów pasków dolnych z górnymi. W górnym rzędzie GS1 DataBar Stacked Omnidirectional znajdują się kolejno: znak startu, blok danych, lewy znak pozycjonujący, blok danych oraz znak stopu. W dolnym rzędzie umieszczane są kolejno: znak startu, blok danych, prawy znak pozycjonujący, blok danych i znak stopu. Oznacza to, że łączna powierzchnia tego kodu jest większa o jeden znak startu i jeden znak stopu oraz o separator, w porównaniu do kodu GS1 DataBar Omnidirectional, ale ze względu na inne proporcje może być bardziej wygodny do naniesienia.

Rysunek 46. Treśc "1234567890123" zakodowana w postaci kodu GS1 DataBar Stacked Omnidirectional
Jeśli kod GS1 DataBar Truncated jest zbyt długi, a GS1 Data- Bar Stacked Omnidirectional, a odczyt zautomatyzowany nie jest konieczny, można skorzystać z kodu GS1 DataBar Stacked, który kodowany jest tak samo jak GS1 DataBar Stacked Omnidirectional, ale:
- wysokość pasków w górnym rzędzie jest jedynie 5-krotnością szerokości najcieńszego paska;
- wysokość pasków w dolnym rzędzie jest 7-krotnością najcieńszego paska;
- separator jest jednorzędowy i ma wysokość równą szerokości najcieńszego paska.
W kodach GS1 DataBar Stacked Omnidirectional i GS1 DataBar Stacked zwyczajowo nie notuje się cyfr w sposób czytelny dla człowieka, co pozwala tym bardziej zaoszczędzić miejsce.
Innym niewielkim kodem z tej rodziny, który powstał dzięki zastosowaniu uproszczenia, jest GS1 DataBar Limited. Wymaga on, by pierwsza z cyfr kodu była zerem lub jedynką. Składa się kolejno z: znaku startu, bloku danych, znaku cyfry kontrolnej, drugiego bloku danych i znaku stopu. Bloki danych mają tu szerokości 26 najcieńszych pasków, a znak cyfry kontrolnej szerokość 18 najcieńszych pasków, co sumuje się do 70, nie licząc znaków startu i stopu. Dla porównania, w GS1 DataBar Omnidirectional same bloki zajmują w sumie 62 szerokości najcieńszego paska (segmenty). Dodatkowo wystarczy, by GS1 DataBar Limited miał wysokość 10 szerokości najcieńszego paska, co czyni go znacznie mniejszym, przy czym nie nadaje się zbytnio do zautomatyzowanego skanowania.

Rysunek 47. Treśc "0123456789012" zakodowana w postaci kodu GS1 DataBar Limited |

Rysunek 48. Treśc "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu GS1 DataBar Expanded |
Potrzeba zaprojektowania nowych kodów wynikała nie tylko z konieczności zmniejszenia rozmiarów piktogramów, ale też po to, by móc w nich przechowywać dodatkowe informacje. W tym celu opracowano kody GS1 DataBar Expanded i GS1 DataBar Expanded Stacked. Mogą one przechowywać do 74 cyfr lub do 45 znaków alfanumerycznych. Kodowane są na dosyć podobnych zasadach co inne kody z tej rodziny. Kody te obsługują funkcje (nieco podobnie do Code 128) oraz mają przechowywać informacje z użyciem identyfikatorów atrybutów (jak w EAN-128). W USA GS1 DataBar Expanded Stacked jest obowiązkowym formatem popularnych kodów kuponów zniżkowych, co mocno zwiększyło liczbę wdrożeń tej technologii.
Warto przy tym dodać, że drugi z kodów typu Expanded może mieć różną postać, pomimo przechowywania tej samej informacji. Podczas generowania kodu określa się bowiem liczbę bloków danych zapisywanych w jednym rzędzie. Musi ona być parzysta i nie większa niż 22. Oznacza to, że dla dwóch bloków w rzędzie, przy kodzie maksymalnej długości, kompletny piktogram składa się aż z 11 rzędów, z których każdy oddzielany jest trójrzędową mozaiką separatora.
Kody typu Expanded można bez obaw skanować w systemach zautomatyzowanych - wysokość każdego rzędu danych jest równa 34-krotności wysokości najcieńszego paska. Pod kodami wielorzędowymi nie umieszcza się cyfr czytelnych dla człowieka.

Rysunek 49. Treśc "ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu GS1 DataBar Expanded Stacked |

Rysunek 50. Treśc "1234567890123|ELEKTRONIKA PRAKTYCZNA" zakodowana w postaci kodu GS1 DataBar Composite |
Ciekawostką są kody z rodziny GS1 DataBar Composite, które również dostępne są w wielu odmianach, przy czym składają się z wybranej wersji wcześniej opisanych GS1 DataBar, do której doklejony jest kod dwuwymiarowy, wybrany z listy dopuszczanych kodów tego typu. Kody typu "Composite" służą do przechowywania dużych ilości dowolnych informacji. Łączna liczba takich kombinacji kodów paskowych i matrycowych jest dosyć duża i nie będą one opisywane w niniejszym artykule.
Podsumowanie
Wybór pomiędzy powyższymi kodami nie jest łatwy, choć w praktyce stosuje się kody kreskowe wynikające z przepisów (np. EAN lub GS1 DataBar) albo w celu zachowania kompatybilności z istniejącymi systemami.
Jeśli projektant ma dużą swobodę wyboru rodzaju kodu kreskowego, a wymogi aplikacji nie są w żaden sposób specyficzne, najlepszym wyborem będzie prawdopodobnie sięgnięcie po bardzo uniwersalny i popularny Code 128. Jeśli natomiast kod ma być nadrukowywany bezpośrednio na grubym kartonie z tektury falistej, lepszym wyborem może okazać się ITF. Do kodów tych istnieje wiele narzędzi, które pozwalają na ich tworzenie oraz skanowanie - zarówno bibliotek programowych, jak i gotowego sprzętu: drukarek i skanerów. Nic nie stoi na przeszkodzie, by w jednej i tej samej aplikacji zastosować kilka różnych kodów, które mogłyby być skanowane na poszczególnych etapach obsługi przedmiotu. Choć może nie jest to najbardziej eleganckie rozwiązanie, często używane jest w celu zapewnienia wstecznej zgodności z urządzeniami wykorzystywanymi przez firmy.
Dobrym przykładem jest firma DHL, która na etykietach na przesyłkach krajowych umieszcza aż 6 kodów graficznych: 4 Code 128, 1 Code 39 i 1 kod dwuwymiarowy PDF417. Wszystkie te informacje można by zawrzeć w jednym kodzie dwuwymiarowym (w istocie, w przesyłkach DHL, kod PDF417 zawiera m.in. prawie wszystkie informacje z pozostałych kodów na paczce), ale zapewne niektóre urządzenia w procesie logistycznym nie byłyby w stanie odczytać tych danych. Kody graficzne dwuwymiarowe zostaną opisane w przyszłym numerze "Elektroniki Praktycznej".
Marcin Karbowniczek, EP