Zaloguj
Zaloguj




Jak w każdym teście lub badaniu ogromnie ważną rolę odgrywa używana metoda. Bez jej opisu informacje są niepełne i właściwie bezwartościowe, więc poświęćmy jej kilka słów.
Zastosowana metoda
Ponieważ zależało nam na podejściu maksymalnie praktycznym, mierzyliśmy czas wykonania zestawu testów reprezentujących typowe operacje wykonywane przez mikrokontrolery. W testach wykorzystano następujące typy mikrokontrolerów:
- STM32F030R8 (Cortex-M0),
- STM32L053R8 (Cortex-M0+),
- STM32F103RB (Cortex-M3),
- STM32L152RE (Cortex-M3),
- STM32F446RE (Cortex-M4),
- STM32F746ZG (Cortex-M7).
Kolejne testy obejmowały (na początku podano skrótowe oznaczenia stosowane dalej w tabelach):
- int – proste operacje arytmetyczne i logiczne na liczbach stałopozycyjnych: dodawanie, odejmowanie, mnożenie, dzielenie, modulo, suma logiczna, iloczyn logiczny, różnica symetryczna.
- float – proste operacje na liczbach zmiennopozycyjnych pojedynczej precyzji: dodawanie, odejmowanie, mnożenie, dzielenie, modulo, wartość bezwzględna, pierwiastek kwadratowy, podnoszenie do potęgi.
- double – proste operacje na liczbach zmiennopozycyjnych podwójnej precyzji – dokładnie takie same operacje jak dla liczb zmiennopozycyjnych pojedynczej precyzji.
- matrix fl, matrix fix – operacje na macierzach liczb odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31. Wykorzystano funkcje z biblioteki CMSIS: dodawanie, odejmowanie, mnożenie, transpozycja i odwrotność (ostatnie tylko dla liczb zmiennopozycyjnych, ze względu na brak odpowiedniej funkcji operującej na liczbach stałopozycyjnych w bibliotece CMSIS).
- fft fl, fft fix – prosta i odwrotna, szybka transformata Fouriera w wersji operującej na liczbach odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31. Test został przeprowadzony dla mikrokontrolerów, które miały wystarczająco dużą pamięć, aby można było wgrać program wykorzystujący funkcje z biblioteki CMSIS, tj. STM32L152RE, STM32F446RE, STM32F746ZG.
- foc fl, foc fix – algorytmy wykorzystywane przy Field Oriented Control: PID, transformata Clarka, transformata Parka (prosta i odwrotna). Wykorzystano funkcje z biblioteki CMSIS w wersji operującej na liczbach odpowiednio zmiennopozycyjnych pojedynczej precyzji i stałopozycyjnych w formacie Q1.31.
- sm – skoki i rozejścia warunkowe w Finite State Machine. Jako automat do testów wykorzystany został prosty hex loader.
W każdym przypadku częstotliwość taktowania mikrokontrolera została ustawiona na największą możliwą dla danego mikrokontrolera. Sygnał zegarowy mikrokontrolera pochodził z PLL. Tam, gdzie było to możliwe, jako źródło częstotliwości wejściowej PLL wybrano HSE. W przypadku mikrokontrolera STM32F030R8 używana płytka Nucleo była w konfiguracji „HSE not used”, w związku z czym do taktowania PLL wykorzystano HSI.
Do pomiaru czasu wykorzystane zostały sprzętowe timery. Pomiary wykonano z rozdzielczością 1 ms dla mikrokontrolerów: STM32F103RB, STM32F446RE, STM32F746ZG i z rozdzielczością 10 ms dla STM32F030R8, STM32L053R8, STM32L152RE. Wyniki zostały następnie znormalizowane. Żeby nie zakłócać testów przez obsługę przerwań, pomiary polegały na odczytaniu rejestru CNT timera przed i po teście, a następnie wyliczeniu na tej podstawie czasu wykonania testu. Wyniki zostały następnie sprawdzone i ewentualnie skorygowane – w przypadku wyników większych niż 216 – 1 – na podstawie wyników pomiarów przeprowadzonych z 10 razy mniejszą rozdzielczością. Po zakończonych testach wyniki były przesyłane do komputera PC przez UART.
Dla wszystkich mikrokontrolerów sprawdzono wpływ następujących opcji:
- Poziom optymalizacji: –o2 vs –o3 – różnice w otrzymanych wynikach z reguły były niewielkie (w większości przypadków nie przekraczały ±1%), dlatego dalej przedstawiono wyniki dla poziomu optymalizacji –o3, a krótkie podsumowanie różnic między –o2 i –o3 umieszczono przy opisie wyników dla każdego z mikrokontrolerów.
- Wykorzystanie bądź nie sprzętowej jednostki zmiennopozycyjnej (FPU) tam, gdzie jest ona dostępna (tj. dla STM32F446RE, STM32F746ZG – w obu przypadkach jest to jednostka zmiennopozycyjna pojedynczej precyzji).
- Wykorzystanie biblioteki Microlib zoptymalizowanej na niewielki rozmiar kodu względem biblioteki standardowej.
Dla konkretnych mikrokontrolerów sprawdzono wpływ specyficznych opcji mających przyspieszyć wykonanie programów, takich jak: prefetch, buforowanie, kieszenie.
Porównano również czas wykonania testów fft i foc w wersji operującej na liczb zmiennopozycyjnych i stałopozycyjnych oraz wyniki testów double i float (te same obliczenia na liczbach podwójnej i pojedynczej precyzji).
Wpływ dostępnych opcji na czas wykonywania programu
1. STM32F030R8 (Cortex-M0)
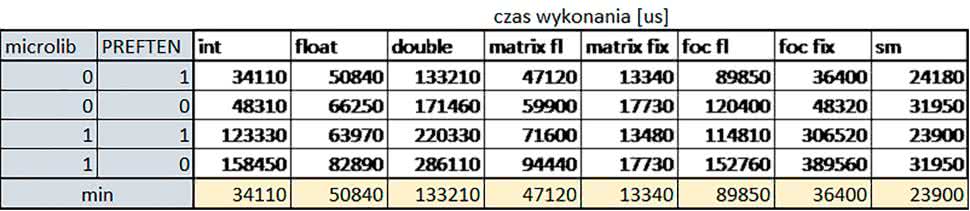
W przypadku STM32F030R8 ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję.
Wyniki:



Wnioski:
- –o2 vs –o3
- Różnice między poziomem optymalizacji –o2 a –o3 praktycznie nie występowały (nie przekraczały ±1%).
- microlib vs std lib
- Rozmiar kodu wynikowego był o ok. ¼ większy dla biblioteki standardowej. W przypadku automatu i obliczeń na macierzach liczb stałopozycyjnych różnice nie występowały lub były bardzo małe (do ok. 1%). Dla obliczeń zmiennopozycyjnych w przypadku korzystania z Microlib czas wykonania był ok. 1,2…1,7 razy dłuższy.
Znaczne różnice wystąpiły w przypadku prostych obliczeń stałopozycyjnych, gdzie czas wykonania wersji wykorzystującej Microlib okazał się ok. 3,5 razy dłuższy. Jeszcze większe w przypadku FOC operującego na liczbach stałopozycyjnych, gdzie użycie Microlib spowodowało ponad 8-krotny wzrost czasu wykonania.
- PREFTEN
Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania ok. 1,3…1,4 razy. Największy wpływ miało na operacje na macierzach liczb stałopozycyjnych, FOC operujące na liczbach zmiennopozycyjnych, automat oraz, w przypadku korzystania z biblioteki standardowej, na proste operacje stałopozycyjne i FOC operujące na liczbach stałopozycyjnych.
- double vs float
Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,5 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
- floating point vs fixed point
Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 2,5 razy krótszy, jeżeli wykorzystywana była biblioteka Microlib.
2. STM32L053R8 (Cortex-M0+)
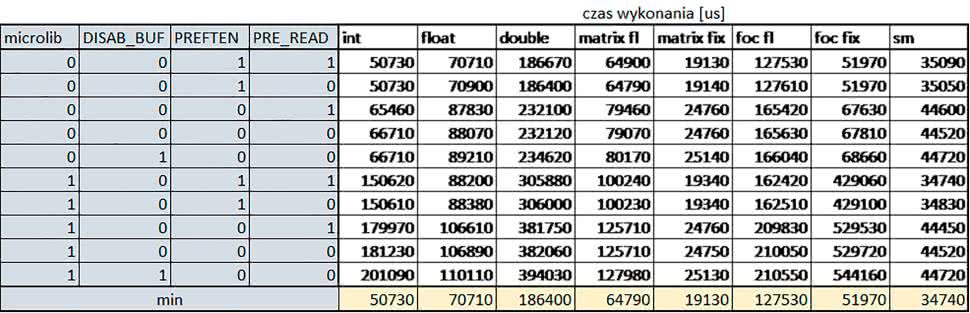
W przypadku STM32L053R8 ustawienie bitu DISAB_BUF w rejestrze FLASH_ACR wyłącza bufory używane jako kieszenie dla odczytów z NVM (Non-Volatile Memory). Jeśli DISAB_BUF = 0, to ustawienie w rejestrze FLASH_ACR bitu PREFTEN włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję, a ustawienie bitu PRE_READ włącza mechanizm pre-read, czyli spekulatywne pobieranie kolejnego słowa danych.
Wyniki:




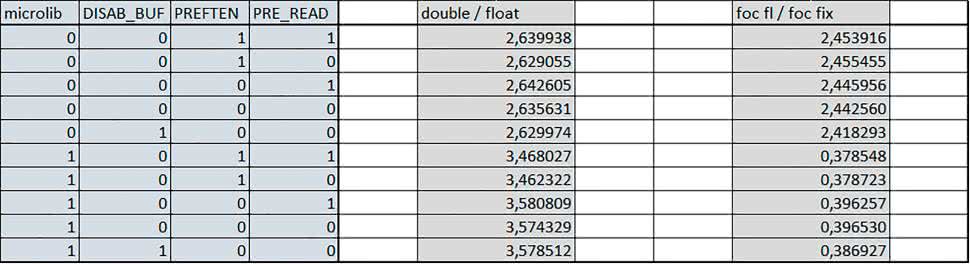
Wnioski:
- –o2 vs –o3
Dla automatu czas wykonania w przypadku poziomu optymalizacji o2 był ok. 2…3% krótszy. W pozostałych wypadkach różnice praktycznie nie występowały.
- microlib vs std lib
Rozmiar kodu wynikowego był o ok. 25% większy dla biblioteki standardowej. W przypadku automatu i obliczeń na macierzach liczb stałopozycyjnych różnice nie występowały lub były bardzo małe (do ok. 1%). Dla obliczeń zmiennopozycyjnych w przypadku korzystania z Microlib czas wykonania był ok. 1,2…1,6 razy dłuższy.
Znaczne różnice wystąpiły w przypadku prostych obliczeń stałopozycyjnych, gdzie czas wykonania wersji wykorzystującej Microlib okazał się ok. 3 razy dłuższy. Jeszcze większe w przypadku FOC operującego na liczbach stałopozycyjnych, gdzie użycie Microlib spowodowało ok. 8-krotny wzrost czasu wykonania.
- DISAB_BUF
Wyłączenie buforów spowodowało wydłużenie czasu wykonania o maksymalnie kilka procent. Wyłączenie buforów praktycznie nie miało wpływu w przypadku automatu, FOC operującego na liczbach zmiennopozycyjnych i prostych obliczeń stałopozycyjnych, jeżeli wykorzystywana była biblioteka standardowa. Natomiast jeżeli wykorzystywana była biblioteka Microlib, to czas wykonania dla prostych obliczeń stałopozycyjnych był ok. 1,1 razy dłuższy przy wyłączonych buforach.
- PREFTEN
Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania o ok. 10…30%. Największy wpływ miało na operacje na macierzach liczb stałopozycyjnych, FOC operujące na liczbach zmiennopozycyjnych oraz, w przypadku korzystania z biblioteki standardowej, na proste operacje stałopozycyjne i FOC operujące na liczbach stałopozycyjnych.
- PRE_READ
Bardzo małe różnice.
- double vs float
Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,5 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
- floating point vs fixed point
Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2,5 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 2,5 razy krótszy, jeżeli wykorzystywana była biblioteka Microlib.
3. STM32F103RB (Cortex-M3)
W przypadku STM32F103RB ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano jako instrukcję.
Wyniki:
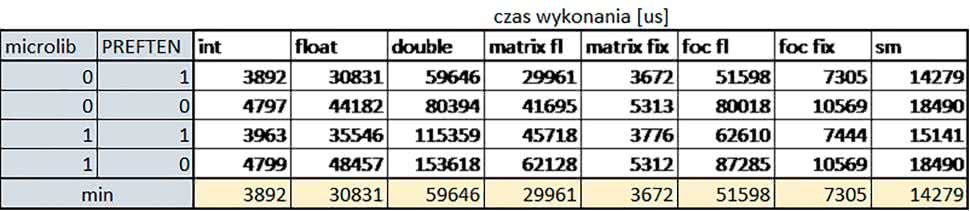



Wnioski:
- –o2 vs –o3
Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był do ok. 7% krótszy. W przypadku korzystania z biblioteki standardowej i przy włączonym prefetch dla prostych obliczeń zmiennopozycyjnych – ok. 6% krótszy, dla obliczeń na macierzach liczb zmiennopozycyjnych – ok. 9% krótszy, natomiast dla FOC operującego na liczbach zmiennopozycyjnych – ok. 2% dłuższy. Przy włączonym prefetch dla automatu – ok. 2–7% krótszy.
W pozostałych przypadkach różnice były niewielkie.
- microlib vs std lib
Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Różnice czasów wykonania w zależności od użycia biblioteki standardowej lub Microlib były średnio mniejsze niż dla Cortex-M0(+). Różnice były większe przy włączonym prefetch. Dla operacji na liczbach stałopozycyjnych i automatu różnice były niewielkie.
W przypadku korzystania z Microlib czas wykonania był ok. 2 razy dłuższy dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji, ok. 1,5 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,1–1,2 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych.
- PREFTEN
Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania ok. 1,2…1,5 razy. Największe znaczenie miało dla FOC, obliczeń na macierzach (szczególnie zmiennopozycyjnych) i prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej precyzji. Większe różnice występowały, jeżeli wykorzystywana była biblioteka standardowa niż dla Microlib.
- double vs float
Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana jest biblioteka standardowa i ok. 3,2 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
- floating point vs fixed point
Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 6…7 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ponad 8 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok. 7…8 razy i ok. 10 razy.
4. STM32L152RE (Cortex-M3)
W przypadku STM32L152RE ustawienie bitu PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnego słowa po tym, które ostatnio odczytano, jako instrukcję.
Wyniki:




Wnioski:
- –o2 vs –o3
Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był do ok. 2–3% krótszy, natomiast w przypadku korzystania z biblioteki standardowej dla prostych obliczeń zmiennopozycyjnych i obliczeń na macierzach liczb zmiennopozycyjnych – do ok. 4% dłuższy. W pozostałych przypadkach różnice były niewielkie.
- micro lib vs std lib
Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Różnice czasów wykonania w zależności od użycia biblioteki standardowej lub Microlib były średnio mniejsze niż dla Cortex-M0(+). Dla operacji na liczbach stałopozycyjnych i automatu różnice były bardzo niewielkie.
W wypadku korzystania z Microlib czas wykonania był ponad 2 razy dłuższy dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji, ok. 1,7 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,3 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych.
- PREFTEN
Włączenie mechanizmu prefetch spowodowało zmniejszenie czasu wykonania maksymalnie ok. 1,2 razy. Największe znaczenie miało dla obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji, jeżeli wykorzystywana była biblioteka standardowa.
- double vs float
Czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3,2 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
- floating point vs fixed point
Czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 6…7 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ponad 8 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok. 7…8 razy i ok. 10 razy.
5. STM32F446RE (Cortex-M4)
W przypadku STM32F446RE ustawienie w rejestrze FLASH_ACR bitu ICEN włącza kieszeń instrukcji o pojemności 64 linii po 128 bitów każda, natomiast ustawienie bitu DCEN włącza kieszeń danych o pojemności 8 linii po 128 bitów każda. Ustawienie PREFTEN w rejestrze FLASH_ACR włącza mechanizm prefetch, czyli spekulatywne pobieranie kolejnej 128-bitowej linii zawierającej instrukcje.
Wyniki:
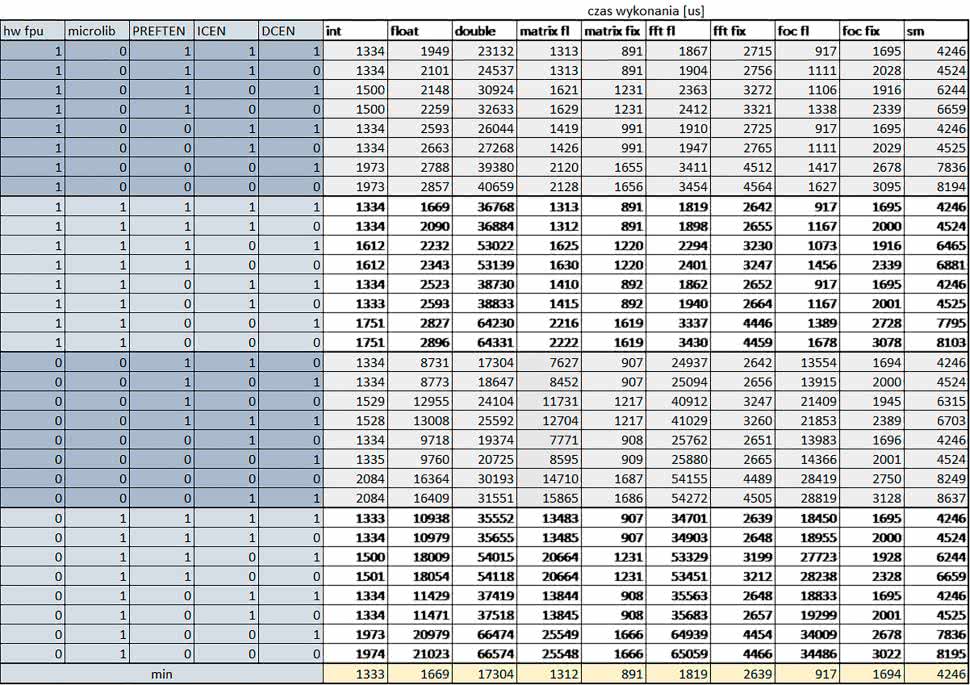
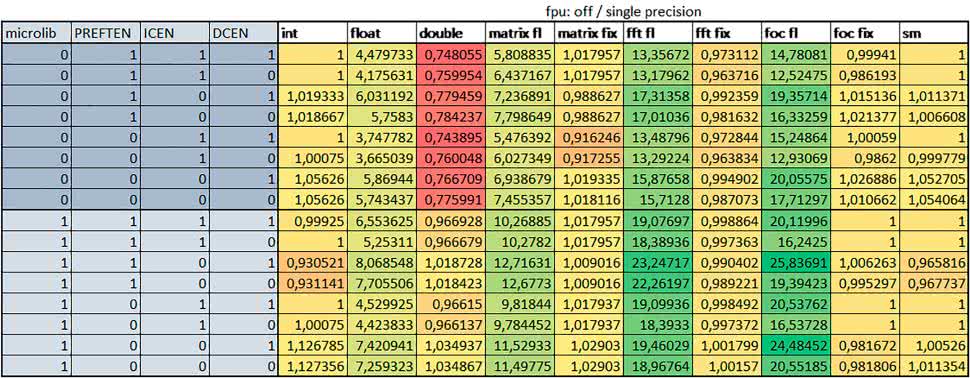
Wnioski:
- –o2 vs –o3
W większości wypadków różnice były nieznaczne (poniżej 1%). Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był do ok. 3% krótszy, jeśli włączona była kieszeń instrukcji oraz do ok. 20% krótszy, jeśli kieszeń instrukcji była wyłączona.
Dla operacji zmiennopozycyjnych pojedynczej precyzji w przypadku używania biblioteki standardowej przy wyłączonej kieszeni instrukcji i FPU czas wykonania dla poziomu optymalizacji –o2 był od kilku do kilkunastu procent krótszy.
W przypadku używania FPU, dla FOC operującego na liczbach zmiennopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był od kilku do ok. 10% dłuższy.
Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był do ok. 2…3% krótszy, natomiast w przypadku korzystania z biblioteki standardowej dla prostych obliczeń zmiennopozycyjnych i obliczeń na macierzach liczb zmiennopozycyjnych – do ok. 4% dłuższy. W pozostałych wypadkach różnice były niewielkie.
- FPU
Wykorzystanie FPU przyspieszyło obliczenia na liczbach zmiennopozycyjnych pojedynczej precyzji ok. 3,5…20 razy dla biblioteki standardowej i ok. 4,5…25 razy dla biblioteki Microlib. Użycie wsparcia sprzętowego dla obliczeń zmiennopozycyjnych było najbardziej korzystne w przypadku FOC i FFT, gdzie przyspieszenie wynosiło 15…20 razy dla biblioteki standardowej i 20…25 dla biblioteki Microlib. Trochę mniejsze różnice występowały w przypadku obliczeń na macierzach (6…8 razy dla biblioteki standardowej i 10…13 dla biblioteki Microlib) i prostych obliczeń (3,5…6 razy dla biblioteki standardowej i 4,5…8 dla biblioteki Microlib).
Obliczenia na liczbach zmiennopozycyjnych podwójnej precyzji w przypadku korzystania z FPU wykonywały się o ok. 30% wolniej dla biblioteki standardowej i ok. 4% wolniej dla biblioteki Microlib i włączonej kieszeni instrukcji.
Wyniki cd.:
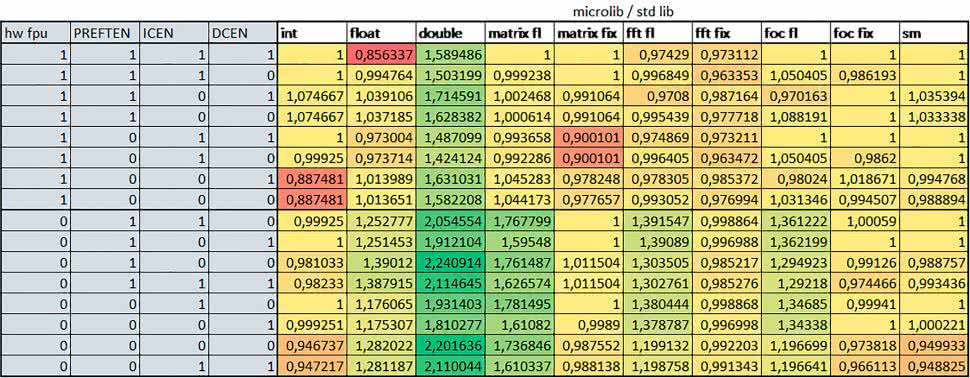
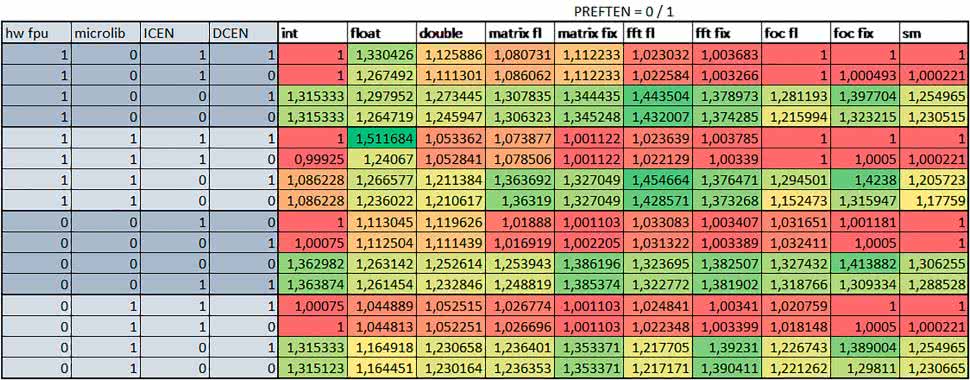
Wnioski cd.:
- micro lib vs std lib
Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Dla biblioteki Microlib czas wykonania dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji był ok. 1,5 razy dłuższy w przypadku używania FPU, i ok. 2 razy dłuższy, jeśli FPU nie było wykorzystywane. W przypadku niekorzystania z FPU czas wykonania dla biblioteki Microlib był ok. 1,7 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,2…1,4 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych.
- PREFTEN
Jeśli kieszeń instrukcji była włączona, to mechanizm prefetch miał niezbyt duży wpływ na czas wykonania. W większości przypadków wyniki były bardzo podobne. Różnice występowały w kilku przypadkach: przy włączonym prefetch dla obliczeń na macierzach i prostych obliczeń zmiennopozycyjnych podwójnej precyzji czas wykonania był do ok. 1,1 razy krótszy, dla prostych obliczeń zmiennopozycyjnych pojedynczej precyzji – do ok. 1,3 razy krótszy (w pojedynczym przypadku 1,5 razy).
Jeśli kieszeń instrukcji była wyłączona, prefetch miało znacznie większy wpływ. Włączenie prefetch spowodowało skrócenie czasu wykonania ok. 1,1…1,5 razy (w większości przypadków ponad 1,2 razy).
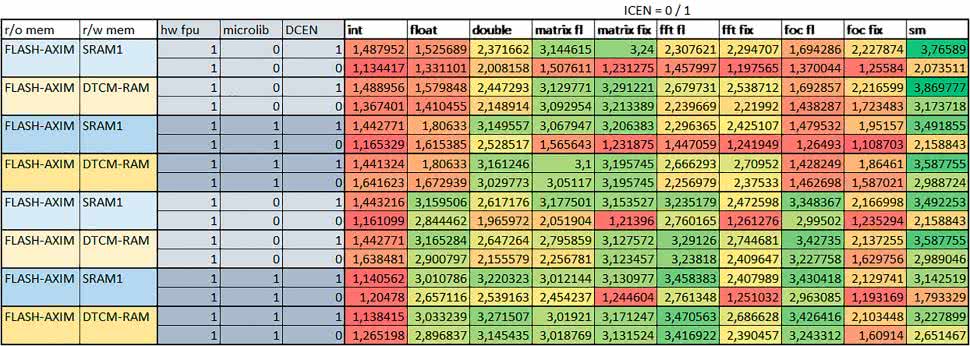
- Instruction Cache (ICEN)
Włączenie kieszeni instrukcji spowodowało zmniejszenie czasu wykonania ok. 1,1…2 razy. Miało większe znaczenie, jeśli mechanizm prefetch był wyłączony.
W wypadku obliczeń zmiennopozycyjnych miało większe znaczenie, jeśli FPU nie było wykorzystywane.
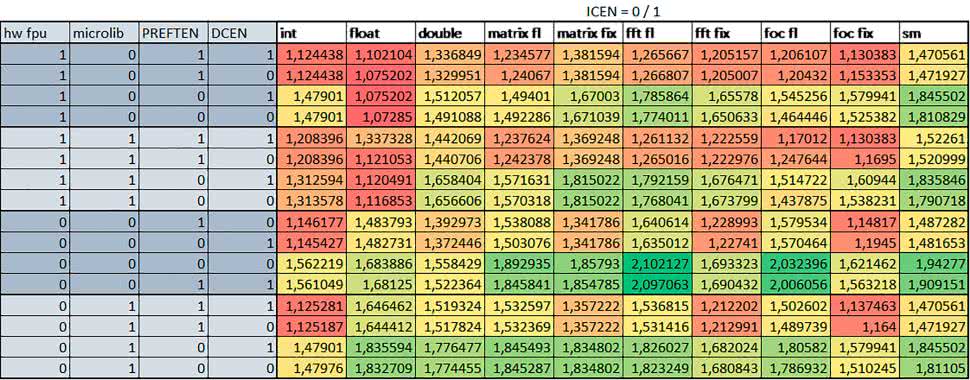
Wyniki cd.:
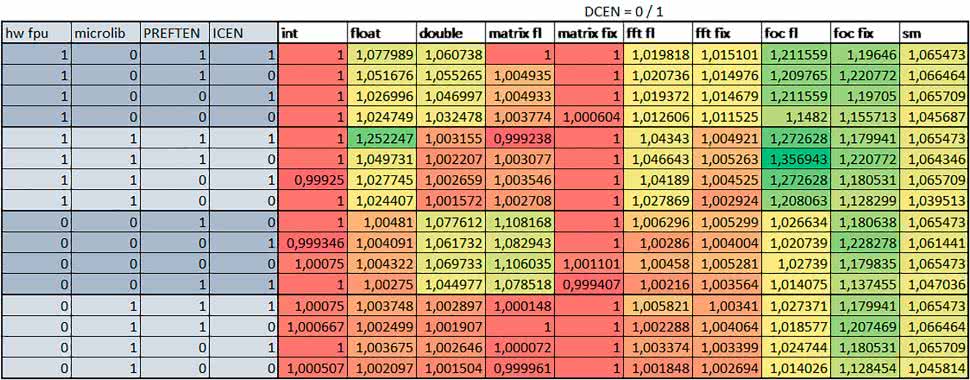
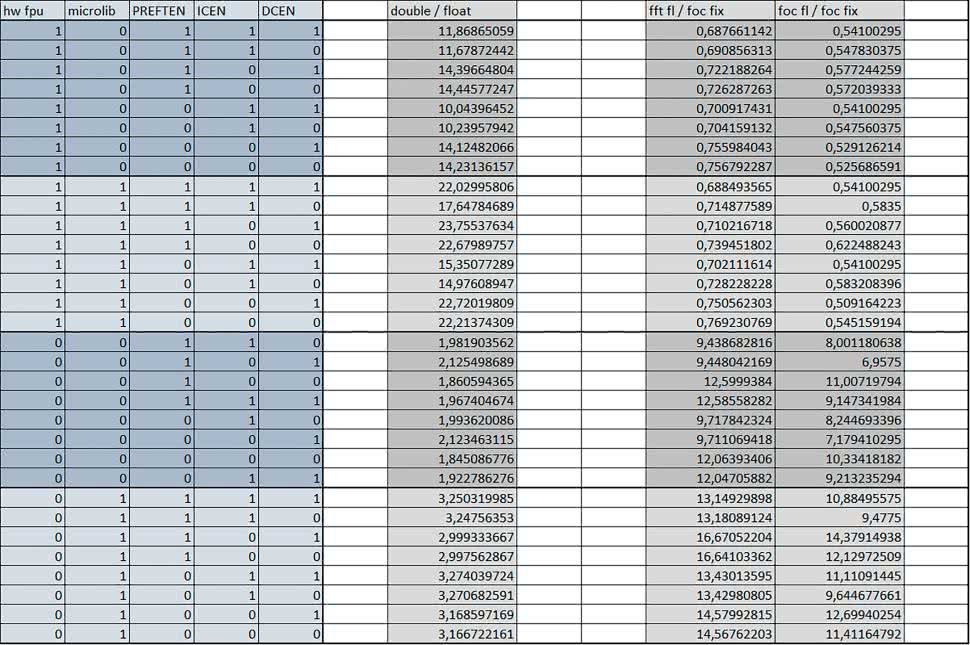
Wnioski cd.:
- Data Cache (DCEN)
Włączenie kieszeni danych największe znaczenie miało przy FOC – spowodowało skrócenie czasu wykonania ok. 1,2 razy dla wersji stałopozycyjnej i ok. 1,2–1,3 razy dla wersji zmiennopozycyjnej w przypadku nieużywania FPU. Miało niewielkie znaczenie dla pozostałych obliczeń stałopozycyjnych.
Włączenie kieszeni danych spowodowało skrócenie o ok. kilka procent czasu wykonania dla automatu, jak również dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji w przypadku używania biblioteki standardowej, prostych obliczeń zmiennopozycyjnych pojedynczej precyzji, jeśli FPU nie było wykorzystywane, oraz dla obliczeń na macierzach liczb zmiennopozycyjnych, jeśli używana była biblioteka standardowa i FPU nie było wykorzystywane.
- double vs float
W wypadku nieużywania FPU czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
W przypadku używania FPU czas wykonania był odpowiednio ok. 10 i ok. 20 razy dłuższy.
- floating point vs fixed point
W wypadku nieużywania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 7–10 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 10–15 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib. Dla FFT czasy wykonania różniły się odpowiednio ok. 10…12 razy i ok. 13…16 razy.
W wypadku używania FPU czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 2 razy krótszy, natomiast FFT ok. 1,4 razy krótszy.
6. STM32F746ZG (Cortex-M7)
W przypadku STM32F746ZG możliwe są różne konfiguracje z różnym ulokowaniem kodu i danych w pamięci. Dla różnych konfiguracji różne są też mechanizmy wspomagające wykonanie programu. W przypadku korzystania z pamięci wewnętrznej mikrokontrolera, kod i stałe (Read Only Memory Area) znajdują się w pamięci Flash, a dostępy do nich mogą następować przez interfejs AHB/AXI (Flash-AXIM) albo przez interfejs ITCM – Instruction Tightly-Coupled Memory (Flash-ITCM), natomiast dane (Read/Write Memory Area) mogą być umieszczone w pamięci SRAM, do której dostęp następuje przez interfejs AHB, lub w pamięci DTCM-RAM, do której dostęp następuje przez interfejs DTCM.
Mikrokontroler wyposażony jest w kieszenie instrukcji i danych, które można włączyć korzystając z funkcji SCB_EnableICache() i SCB_EnableDCache() z biblioteki CMSIS. Każda z kieszeni ma rozmiar 4 KiB. Kieszenie mają znaczenie w przypadku, gdy dostępy do pamięci wykonywane są przez interfejs AHB.
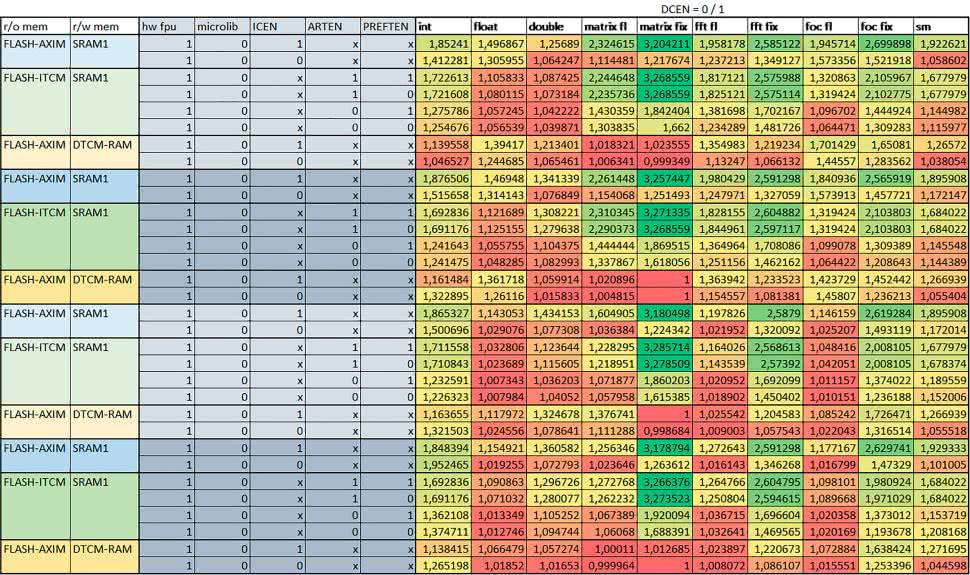
Mikrokontroler jest również wyposażony w Adaptive Real Time Accelerator (ART). ART dysponuje kieszenią o pojemności 64 linii po 256 bitów każda. Włączenie tej kieszeni następuje przez ustawienie bitu ARTEN w rejestrze FLASH_ACR. ART odpowiada także za mechanizm prefetch. Mechanizm prefetch jest włączany przez ustawienie bitu PREFTEN w rejestrze FLASH_ACR. ART i ART-prefetch mają znaczenie w przypadku, gdy instrukcje są pobierane z Flash przez interfejs ITCM.
Przetestowano następujące konfiguracje i wpływ odpowiednich mechanizmów wspomagających:
- RO-Mem: Flash-AXI, R/W-Mem: SRAM1 – kieszeń instrukcji, kieszeń danych,
- RO-Mem: Flash-ITCM, R/W-Mem: SRAM1 – ART i ART-prefetch, kieszeń danych,
- RO-Mem: Flash-AXI, R/W-Mem: DTCM-RAM – kieszeń instrukcji, kieszeń danych (ze względu na możliwy odczyt stałych z pamięci Flash przez interfejs AHB),
- RO-Mem: Flash-ITCM, R/W-Mem: DTCM-RAM – ART i ART-prefetch.
Wyniki:
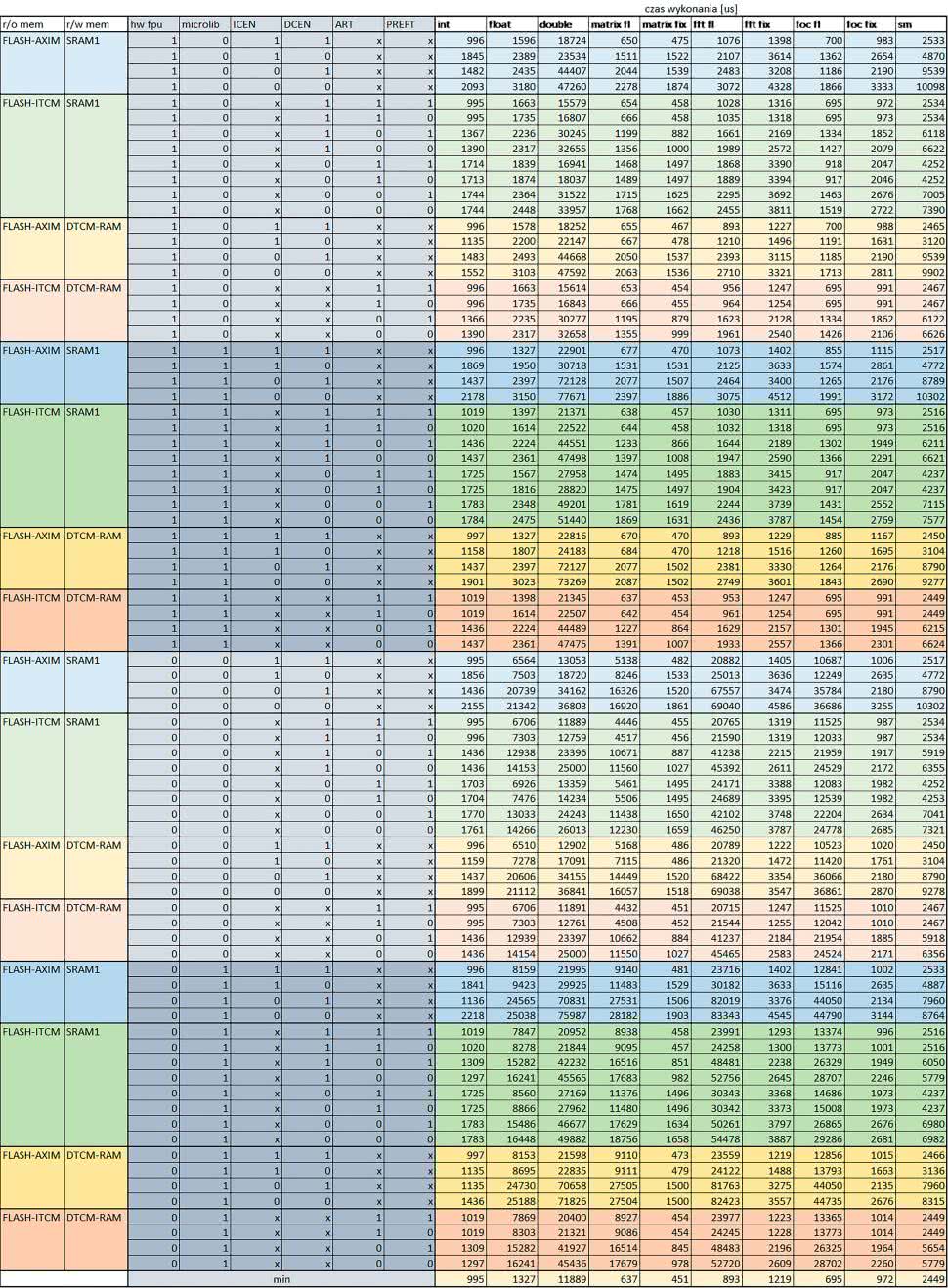
Wnioski:
- –o2 vs –o3
W większości wypadków różnice były nieznaczne (poniżej 2%). Dla prostych obliczeń stałopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był ok. 5…10% krótszy, jeśli odpowiednie mechanizmy wspomagające pobieranie instrukcji (kieszeń instrukcji lub ART i ART-prefetch) były włączone oraz do ok. 40% krótszy, jeśli nie były włączone.
Dla FOC operującego na liczbach stałopozycyjnych oraz, jeżeli używane było FPU, dla FOC operującego na liczbach zmiennopozycyjnych czas wykonania w przypadku poziomu optymalizacji –o2 był do ok. 15% dłuższy.
Jeśli odpowiednie mechanizmy wspomagania pobierania instrukcji nie były włączone, czas wykonania dla automatu był do ok. 15% krótszy przy poziomie optymalizacji –o2, jeśli używane było FPU lub biblioteka standardowa oraz do ok. 15% dłuższy, jeśli FPU nie było używane i korzystano z Microlib.
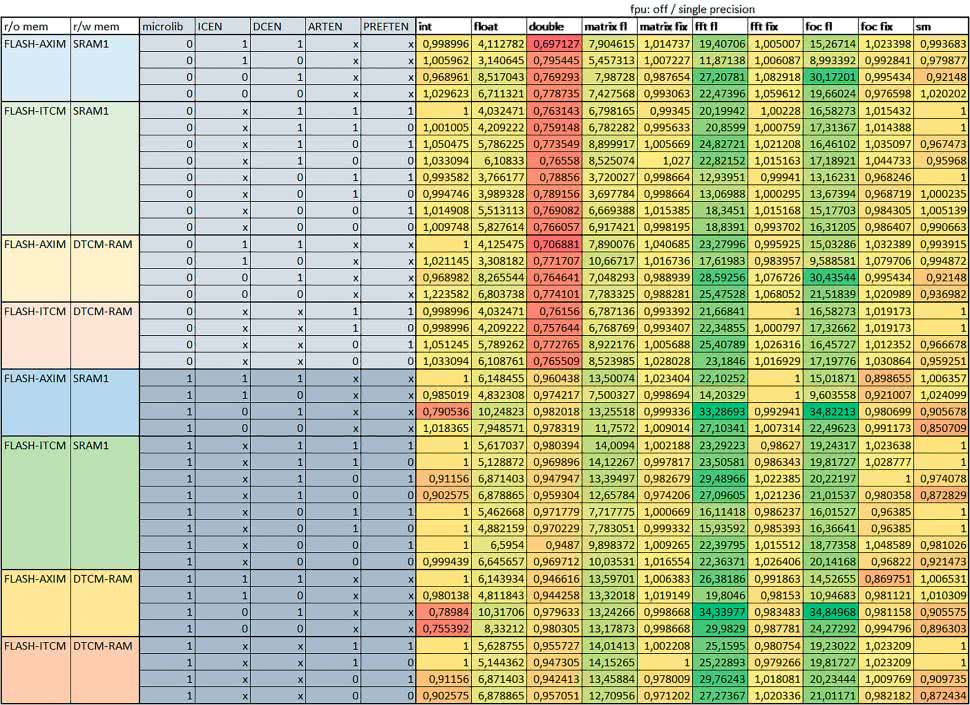
- FPU
Wykorzystanie FPU przyspieszyło obliczenia na liczbach zmiennopozycyjnych pojedynczej precyzji ok. 3,5–30 razy dla biblioteki standardowej i ok. 5–35 razy dla biblioteki Microlib. Użycie wsparcia sprzętowego dla obliczeń zmiennopozycyjnych było najbardziej korzystne w przypadku FOC i FFT, gdzie przyspieszenie wynosiło od ok. 10 do ok. 30 razy. Trochę mniejsze różnice występowały w wypadku obliczeń na macierzach (4…10 razy dla biblioteki standardowej i 7…14 razy dla biblioteki Microlib) i prostych obliczeń (3…8 razy dla biblioteki standardowej i 5…10 razy dla biblioteki Microlib).
Obliczenia na liczbach zmiennopozycyjnych podwójnej precyzji w przypadku korzystania z FPU wykonywały się o ok. 30% wolniej dla biblioteki standardowej i ok. 2…5% wolniej dla biblioteki Microlib.
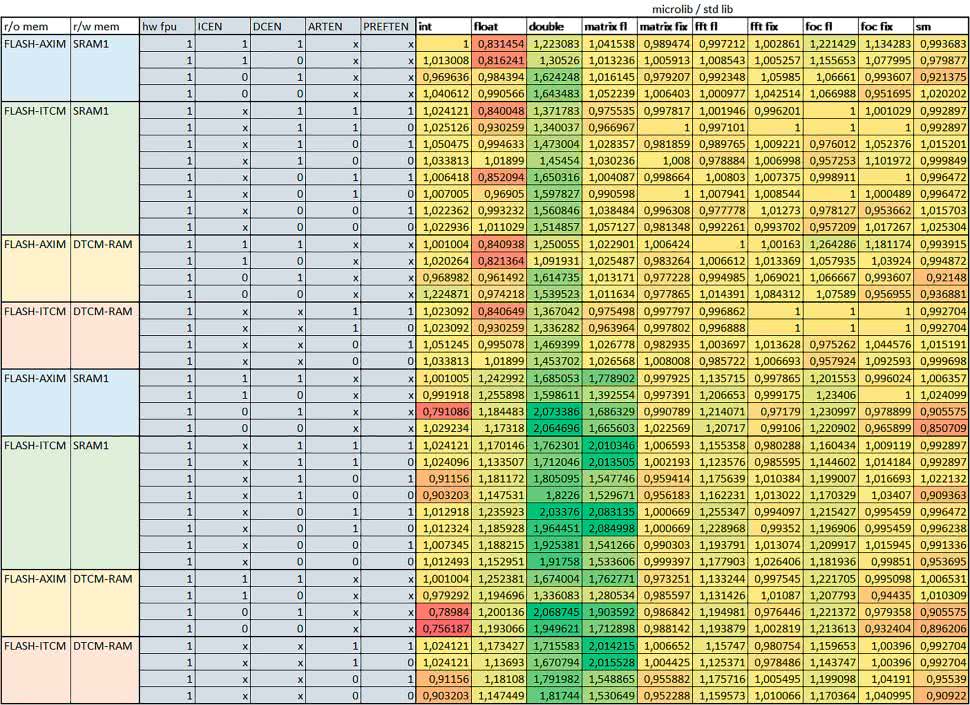
- micro lib vs std lib
Rozmiar kodu wynikowego był o ok. 1/6 większy dla biblioteki standardowej. Dla biblioteki Microlib czas wykonania dla prostych obliczeń zmiennopozycyjnych podwójnej precyzji był ok. 1,2…1,6 razy dłuższy w przypadku używania FPU i ok. 1,3…2 razy dłuższy, jeśli FPU nie było wykorzystywane. W wypadku niekorzystania z FPU czas wykonania dla biblioteki Microlib był ok. 1,5…2 razy dłuższy dla obliczeń na macierzach liczb zmiennopozycyjnych i ok. 1,2 razy dłuższy dla pozostałych obliczeń zmiennopozycyjnych.
W wypadku korzystania z FPU czas wykonania dla biblioteki Microlib był do ok. 1,2 razy krótszy dla prostych obliczeń zmiennopozycyjnych pojedynczej precyzji. Dla konfiguracji, gdzie dostęp do kodu następował przez interfejs AXI, czas wykonania dla biblioteki Microlib był do ok. 1,25 razy dłuższy dla FOC.
Wyniki cd.:
Wnioski cd.:
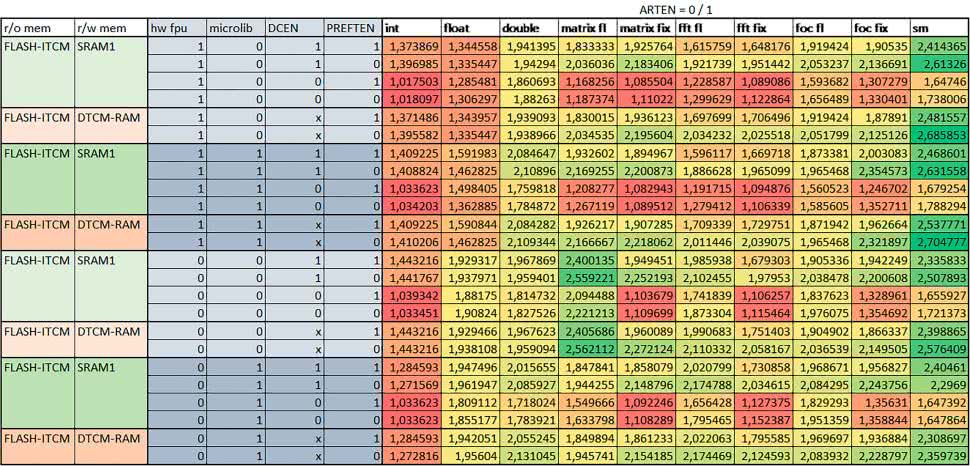
- Instruction Cache (IC)
Włączenie kieszeni instrukcji spowodowało skrócenie czasu wykonania ok. 1,2…3,8 razy. Największe znaczenie miało w przypadku automatu, operacji na macierzach i na liczbach zmiennopozycyjnych podwójnej precyzji, a w przypadku, gdy FPU nie było wykorzystywane również dla obliczeń na liczbach zmiennopozycyjnych pojedynczej precyzji. Przyspieszenie uzyskane dzięki włączeniu kieszeni instrukcji było większe, jeśli jednocześnie włączona była kieszeń danych.
- Data Cache (DC)
Włączenie kieszeni danych spowodowało skrócenie czasu wykonania maksymalnie ok. 3,3 razy. Włączenie kieszeni danych miało większy wpływ na przyspieszenie wykonania programu, jeśli jednocześnie włączone były odpowiednie mechanizmy wspomagające pobieranie instrukcji (kieszeń instrukcji w przypadku korzystania z interfejsu AHB/AXI, ART w przypadku korzystania z interfejsu ITCM).
Włączenie kieszeni danych miało mniejszy wpływ, jeśli dane do odczytu i zapisu znajdowały się w DTCM-RAM, ponieważ wtedy mogło przyspieszyć jedynie odczyt stałych.
Włączenie kieszeni danych miało największe znaczenie w przypadku obliczeń na macierzach liczb stałopozycyjnych oraz FFT i FOC operujących na liczbach stałopozycyjnych. Dość istotne było również dla tych samych testów w wersjach operujących na liczbach zmiennopozycyjnych, jeżeli wykorzystywane było FPU. Najmniejsze znaczenie miało dla prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji oraz dla pozostałych obliczeń zmiennopozycyjnych, jeśli FPU nie było używane. Jednak nawet w tym przypadku, jeśli dane do odczytu i zapisu znajdowały się w SRAM1 i używane były odpowiednie mechanizmy wspomagające pobieranie instrukcji, to przyspieszenie wynikające z włączenia kieszeni danych było dość duże.
- ART Accelarator (ARTEN)
Włączenie ART spowodowało skrócenie czasu wykonania maksymalnie ok. 2,6 razy. Włączenie ART miało największe znaczenie w przypadku automatu oraz, jeżeli FPU nie było używane i wykorzystano bibliotekę standardową, w przypadku obliczeń na macierzach liczb zmiennopozycyjnych. Dość duże również dla obliczeń na macierzach w pozostałych konfiguracjach, FOC (szczególnie operującego na liczbach zmiennopozycyjnych) oraz dla prostych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji.
Włączenie ART miało większy wpływ na czas wykonania, jeśli mechanizm prefetch nie był włączony. W konfiguracjach, gdzie dane do odczytu i zapisu były umieszczone w SRAM1, przyspieszenie uzyskane dzięki włączeniu ART Accelerator było znacznie mniejsze, jeśli kieszeń danych nie była włączona.
Wyniki cd.:
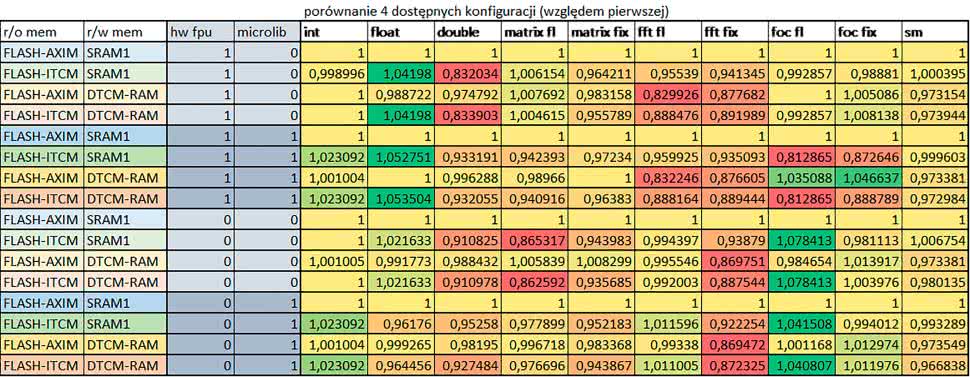
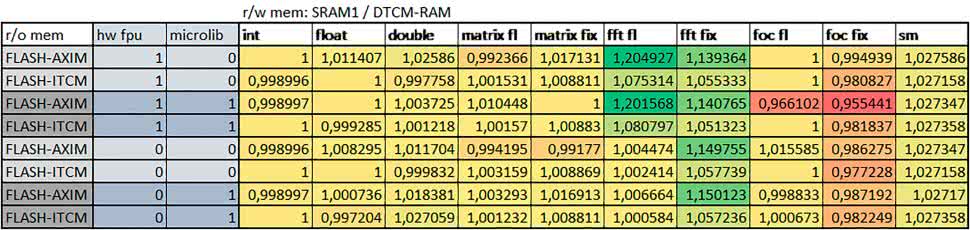
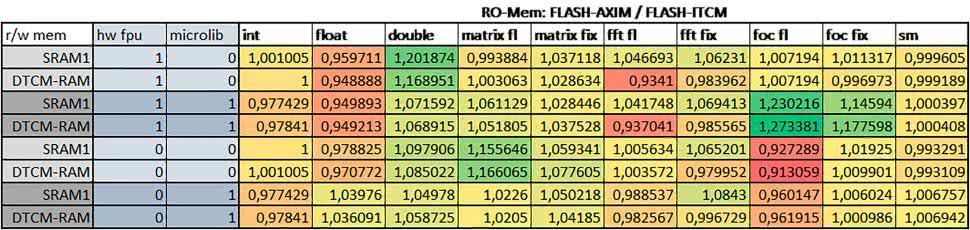
Porównanie konfiguracji
Wnioski cd.:
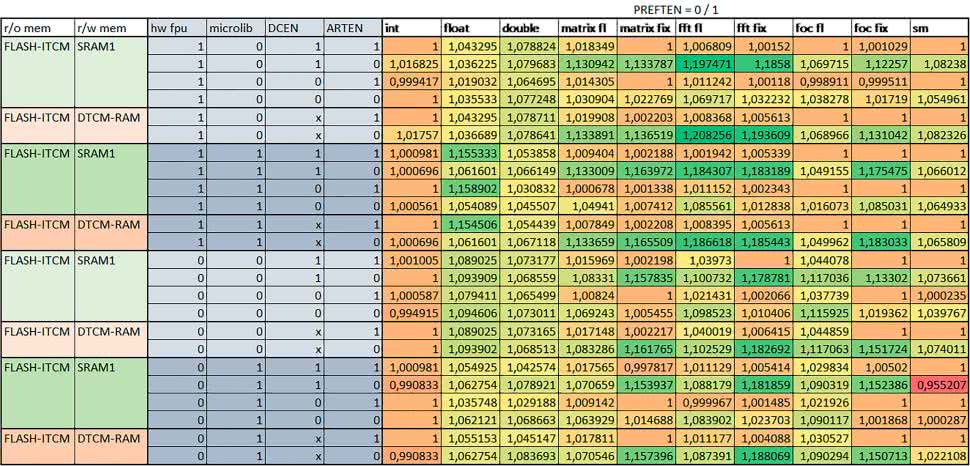
- ART-prefetch (PREFTEN)
Włączenie mechanizmu prefetch spowodowało skrócenie czasu wykonania maksymalnie ok. 1,2 razy. Włączenie mechanizmu prefetch miało większe znaczenie, jeśli ARTEN nie było ustawione. Jeśli ARTEN=1, to włączenie mechanizmu prefetch spowodowało skrócenie czasu wykonania dla prostych obliczeń na liczbach zmiennopozycyjnych pojedynczej i podwójnej precyzji oraz, jeśli FPU nie było używane, także dla pozostałych obliczeń zmiennopozycyjnych. Jeśli ARTEN=0, to istotna poprawa czasu wykonania wystąpiła również w przypadku obliczeń na macierzach liczb stałopozycyjnych oraz FFT i FOC operujących na liczbach stałopozycyjnych.
- Mechanizmy wspomagające (ogólnie)
Różnice czasów wykonania między przypadkiem, gdy mechanizmy wspomagające wykonanie programu są włączone, a przypadkiem, gdy są wyłączone, wyniosły od 1,5 do 7 razy. Jeśli mechanizmy wspomagające wykonanie programu były wyłączone, to czasy wykonania testów były nieraz dość znacząco gorsze niż dla mikrokontrolera STM32F446RE.
- Porównanie konfiguracji
Porównywano wyniki uzyskane, gdy dla danej konfiguracji wszystkie mechanizmy wspomagające były włączone.
- Read Only Memory Area
Różnice czasu wykonania między konfiguracjami różniącymi się interfejsem dostępu do RO-Mem wynosiły maksymalnie 1,2 razy, ale w większości przypadków były małe.
Jeżeli wykorzystywany był interfejs ITCM, to dla prostych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji, czasy wykonania były 1,05–1,2 razy krótsze, dla obliczeń na macierzach – do ok. 1,5 razy krótsze.
W wypadku używania FPU i Microlib, wykorzystanie interfejsu ITCM dało ok. 1,15 razy krótszy czas wykonania dla FOC operującego na liczbach zmiennopozycyjnych i ok. 1,25 razy dla FOC operującego na liczbach stałopozycyjnych. Natomiast jeśli FPU nie było używane, to FOC operujące na liczbach zmiennopozycyjnych wykonywało się 5–10% szybciej w przypadku interfejsu AHB/AXI.
- Read/Write Memory Area
Dla konfiguracji, w których dane do odczytu i zapisu znajdowały się w DTCM-RAM w przypadku FFT operującego na liczbach stałopozycyjnych oraz zmiennopozycyjnych, jeżeli używane było FPU, czasy wykonania były ok. 1,05–1,2 razy krótsze, natomiast w przypadku automatu – 1,03 razy krótsze.
Dla FOC operującego na liczbach stałopozycyjnych czasy wykonania były o kilka procent krótsze, jeśli dane do odczytu i zapisu znajdowały się w SRAM1.
Wyniki cd.:
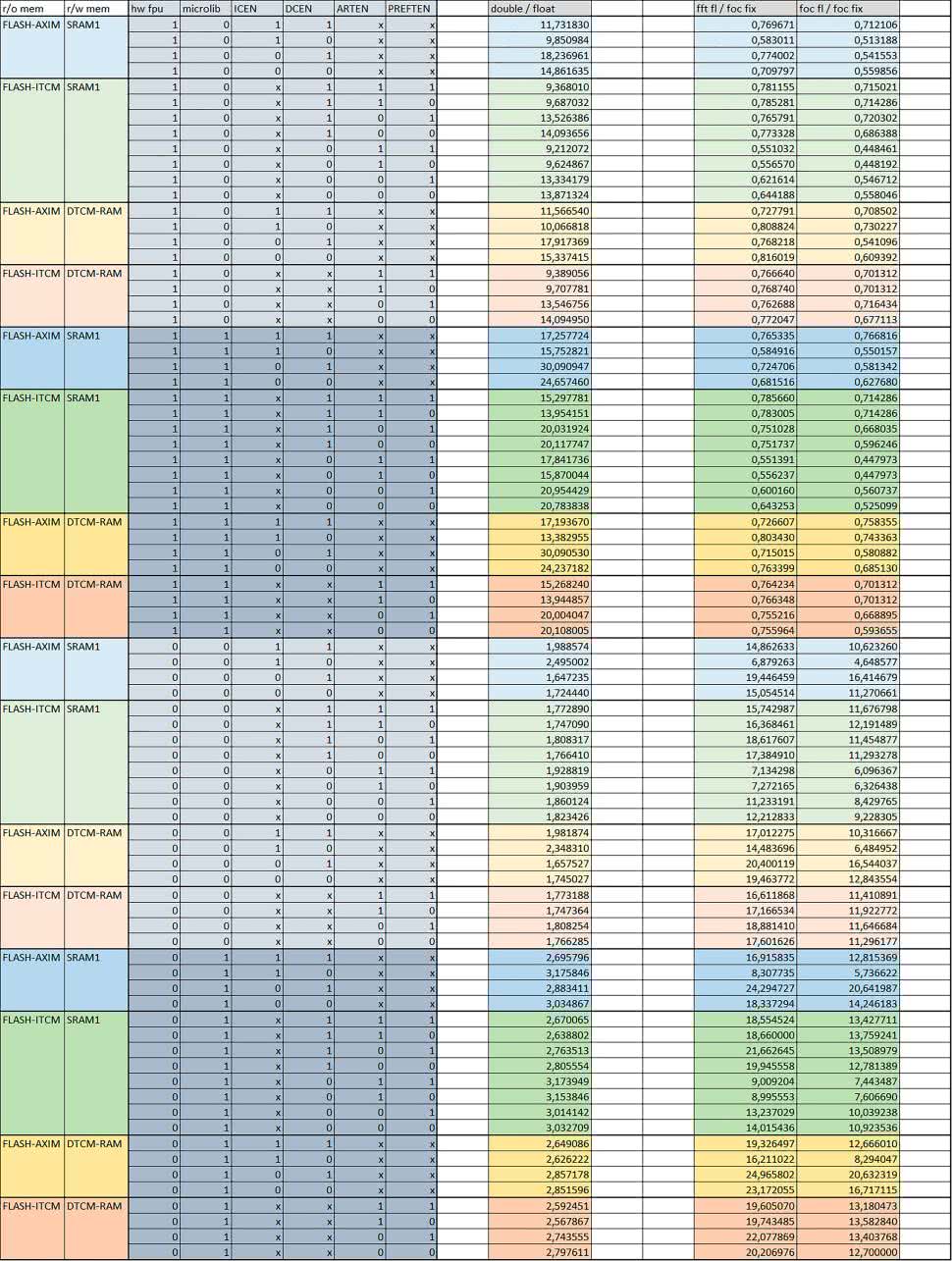
Wnioski cd.:
- double/float
W wypadku nieużywania FPU, czas wykonania tych samych obliczeń na liczbach zmiennopozycyjnych podwójnej precyzji był ok. 2 razy dłuższy, jeżeli wykorzystywana była biblioteka standardowa i ok. 3 razy dłuższy, jeżeli wykorzystywana była biblioteka Microlib.
W wypadku używania FPU, czas wykonania był odpowiednio ok. 10–15 i ok. 15–30 razy dłuższy.
- floating/fixed point
W wypadku nieużywania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 10…20 razy dłuższy. Dla FFT czasy wykonania różniły się typowo ok. 10…12 razy.
W wypadku używania FPU, czas wykonania FOC operującego na liczbach zmiennopozycyjnych był ok. 1,3 razy krótszy, natomiast FFT ok. 1,3…2 razy krótszy.
Katarzyna Kosowska