 Zaloguj
Zaloguj



Jak mawia mój przyjaciel, dźwięki (szczególnie te o wysokich częstotliwościach) słyszymy tym lepiej, im „bardziej jesteśmy młodzi i im bardziej jesteśmy dziewczynkami”. Dla muzyków, instrumentalistów, wokalistów może to być istotna uciążliwość, przeciętny człowiek nawet nie zdaje sobie sprawy z ułomności własnego słuchu. Osoba z dobrym słuchem muzycznym zgrzyta zębami, słuchając fałszującego piosenkarza, podczas gdy duża część ludzi w ogóle tego fałszowania nie odczuwa.
Czym właściwie jest dźwięk?
Wszyscy doskonale pamiętamy różne sceny batalistyczne z filmów science fiction. Turbolasery i działa jonowe instalowane m.in. na Drednot Core Galaxy Systems z Wojen Gwiezdnych wydawały podczas bitew w przestrzeni kosmicznej charakterystyczne dźwięki przyprawiające ludzi „wysokosłyszącyh” o ból głowy. Problem polega jednak na tym, że batalistyczne fragmenty filmu mieszczą się całkowicie w części fiction tego gatunku filmowego. Dźwięk może rozchodzić się tylko w jakimś medium, np. w ośrodku sprężystym, gazowym, ciekłym lub stałym. W przestrzeni kosmicznej jest próżnia, nie ma żadnego medium, dźwięki więc nie mogą się rozchodzić.
Dźwięk jest naszym subiektywnym odczuciem fali dźwiękowej, czyli zaburzenia rozchodzącego się w ośrodku sprężystym. Zaburzenie takie może być generowane na przykład przez głośnik, słuchawkę, tubę itp. Dźwięk rozchodzi się w kierunku od źródła, stopniowo wytracając amplitudę. I całe szczęście, że tak się dzieje, w przeciwnym razie utonęlibyśmy w uciążliwej kakofonii dźwięków. Jak na ironię korzyścią dla człowieka jest też... niedoskonałość naszego własnego słuchu powodująca odbieranie dźwięków tylko w ograniczonym zakresie częstotliwości. Przeglądając literaturę fachową, możemy natrafić na różne definicje zakresu dźwięków słyszalnych. Dość powszechnie przyjmuje się, że zakres słyszalnych częstotliwości zawiera się między 20 Hz a 20 kHz. Pamiętają te liczby audiofile słuchający niegdyś muzyki ze sprzętu Hi-Fi. Ale spotykamy też definicję: od 20 Hz do 16 kHz. Określenie takiego zakresu jest oczywiście umowne, gdyż jak już było powiedziane, każdy człowiek odbiera dźwięki inaczej. Kompromisem byłoby ustalenie tych parametrów na podstawie szerokiego badania populacji i przyjęcie wartości skrajnych. Z tego względu spotykamy również niekiedy definicję ustalającą minimalną słyszalną częstotliwość na 16 Hz. Z moich obserwacji wynika, że duża część ludzi nie słyszy dźwięków powyżej 12 kHz, a nawet niższych.
Należy wspomnieć o jeszcze jednym parametrze dźwięku, jakim jest jego natężenie. Przyjmijmy, że dźwięk jest generowany przez membranę głośnika wprawianą w drgania. Drgania te powstają na skutek doprowadzenia do uzwojenia głośnika elektrycznego sygnału sinusoidalnego uzyskiwanego z generatora (rysunek 1).
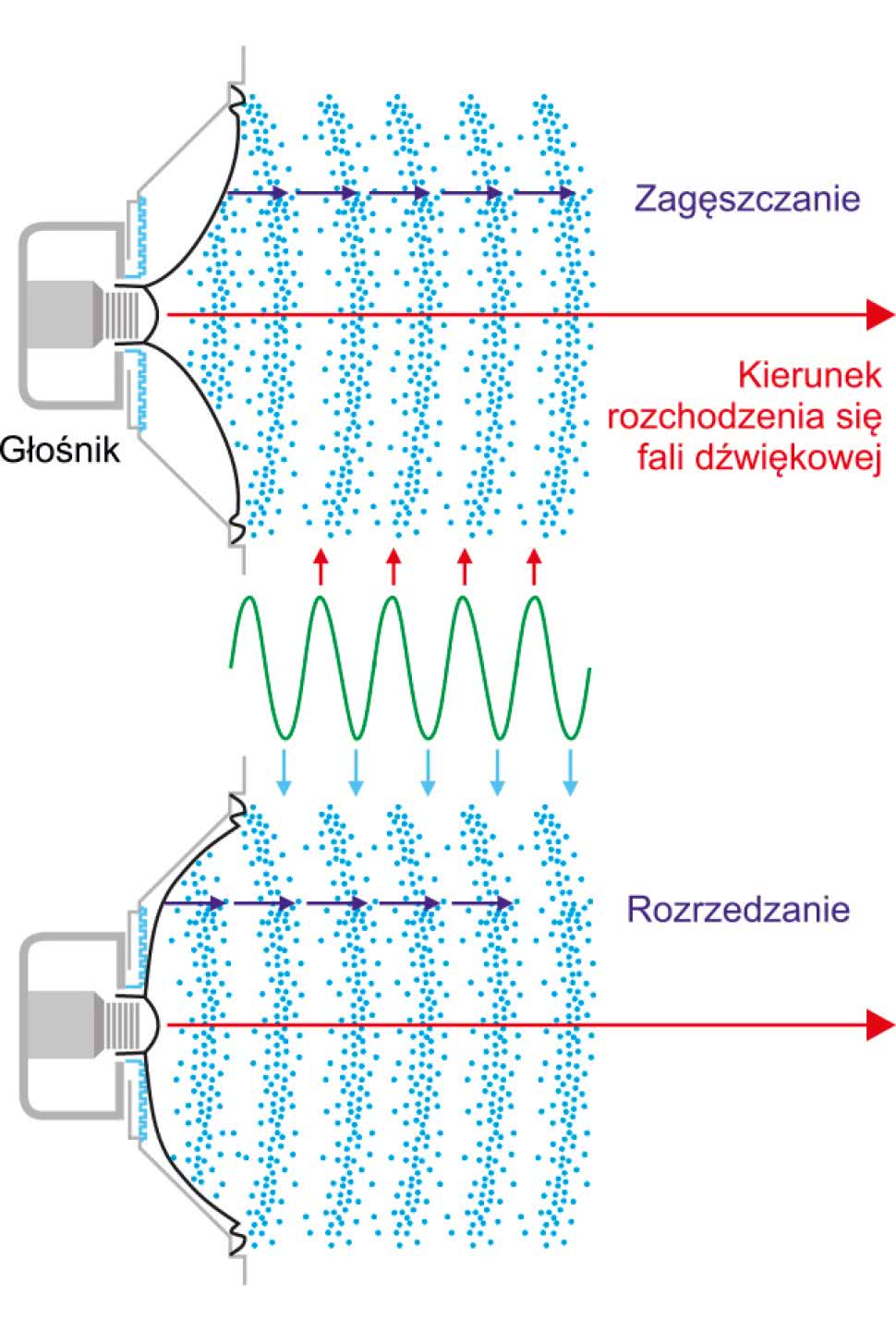
Poruszająca się membrana okresowo zagęszcza i rozrzedza powietrze. Jak wiemy, zaburzenia te rozchodzą się w kierunku od głośnika. Należy zwrócić uwagę na to, że amplituda zaburzeń maleje wraz z kwadratem odległości od źródła. Zagęszczenie lub rozrzedzenie powietrza oznacza, że lokalnie wzrasta i maleje jego ciśnienie w odniesieniu do statycznego ciśnienia otoczenia. Nie spodziewajmy się jednak spektakularnych efektów. Przyjmuje się, że minimalne zmiany ciśnienia, które ludzkie ucho jest w stanie rozpoznać, tzw. próg słyszalności, to 2·10–5 Pa (20 μPa). Normalne statyczne ciśnienie atmosferyczne jest równe 1013,25 hPa = 101325 Pa. Oznacza to, że zmiany ciśnienia dla progu słyszalności są 5066250000 razy mniejsze od ciśnienia otoczenia (sic!). Jest to aż 9 rzędów wielkości. Chyba trzeba zweryfikować pogląd o niedoskonałości naszego ucha. No dobrze, ale to jest przypadek skrajny. Sprawdźmy, jak będą wyglądały powyższe zależności dla bardziej naturalnych warunków. Okazuje się, że normalnie mówiący człowiek, nie polityk na wiecu wyborczym, wywołuje w odległości 1 metra od siebie zmiany ciśnienia na poziomie 0,1 Pa. W tym przypadku nadal jest to stosunek ok. 6 rzędów wielkości (milion razy).
Ciekawa jest też analiza tych zależności z drugiej strony zakresu, to znaczy dla dźwięków powodujących ból, a nawet utratę słuchu. Ciśnienie akustyczne jest wówczas równe ok. 20 Pa, a więc ok. 5 tysięcy razy mniejsze od ciśnienia otoczenia.
Jeszcze raz należy podkreślić, że podanych wartości liczbowych nie należy traktować jako bezwzględnie obowiązujących, gdyż wrażenia słuchowe są bardzo indywidualne dla każdego człowieka i między poszczególnymi osobami mogą się znacznie różnić.
Jest jeszcze jeden aspekt sprawy, na który należy zwrócić uwagę. Intuicyjnie możemy sądzić, że natężenie dźwięku jest tożsame z subiektywnym odczuciem głośności. Oznaczałoby to, że jeśli słuchamy dwóch dźwięków, z których jeden ma dwa razy większe natężenie od drugiego, tzn. powoduje dwukrotnie większe zmiany ciśnienia, to odczujemy również wrażenie dwukrotnej różnicy subiektywnie odbieranej głośności. Tak jednak nie jest. Natężenie dźwięku to mierzalny specjalnymi przyrządami parametr, a głośność to tylko nasze subiektywne odczucie. Co więcej, okazuje się, że głośność zależy nie tylko od natężenia dźwięku, ale też od jego częstotliwości. Bardzo dobrze ilustrują to krzywe izofoniczne, znane również jako krzywe Fletchera-Munsona (rysunek 2).
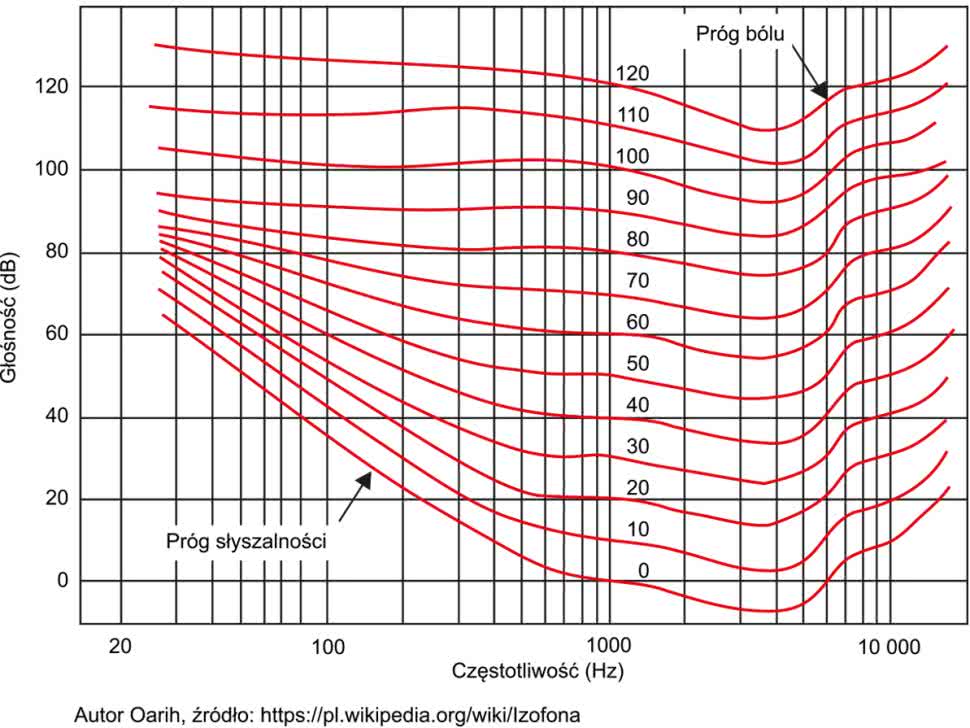
Każda z krzywych obrazuje, jaki powinien być poziom dźwięków o różnych częstotliwościach, aby słuchacz odczuwał je jako dźwięki o jednakowej głośności. Jak widać, nasze ucho ma największą czułość dla dźwięków o częstotliwości między 3 kHz a 4 kHz.
Charakterystyczne jest też znaczne zmniejszenie czułości słuchu dla niskich częstotliwości (poniżej 500 Hz) i częstotliwości wysokich, powyżej 5 kHz. Z krzywych izofonicznych wynika ponadto wniosek, że subiektywnie odczuwana głośność zależy również od poziomu dźwięku. Efekt ten jest widoczny szczególnie wyraźnie dla niskich częstotliwości – krzywe izofonicznie w tym zakresie znacznie nachylają się. Zatem słuchając na przykład muzyki bardzo cicho, możemy w ogóle nie słyszeć tonów niskich, gdy zwiększymy głośność, będą ona słyszane coraz lepiej. Swego czasu w sprzęcie audio były nawet instalowane filtry „loudness”, w polskim sprzęcie znane jako „kontur”. Miały one niwelować różnice w różnym odbiorze dźwięków niskich i wysokich w zależności od ustawionej we wzmacniaczu głośności. Rozwiązanie to miało tylu zwolenników, co przeciwników. Szczęśliwi byli ci, którzy korzystali ze sprzętu wyposażonego w wyłącznik filtru pozwalający ominąć go podczas odsłuchu.
A co powyżej 20 kHz?
Wydaje się, że nasza czujność w zakresie postrzegania dźwięków jest mocno usypiana przez sprzedawców sprzętu grającego. Podkreślanie, że zestawy audio wysokiej jakości odtwarzają muzykę w paśmie 20 Hz...20 kHz, wyrabia u laików pojęcie, że wszystkie otaczające dźwięki mieszczą się tylko w tym zakresie częstotliwości. Oczywiście pamiętamy ze szkoły, że istnieją jeszcze ultradźwięki, ale kto korzysta na co dzień z myjek ultradźwiękowych czy robi badania USG? Wiemy natomiast, że znaczna część zwierząt słyszy dźwięki o dużo wyższych częstotliwościach niż człowiek: nietoperze nawet do 200 kHz, psy 40 kHz, koty 45 kHz, jest też pewien gatunek motyla, który słyszy ultradźwięki aż do 300 kHz. Nie może więc dziwić fakt, że pies oczekuje nas pod drzwiami, zanim się do nich zbliżymy, nawet nim wejdziemy na piętro. Można sądzić, że ciekawe by było poznanie, jakie dźwięki w rzeczywistości nas na co dzień otaczają?
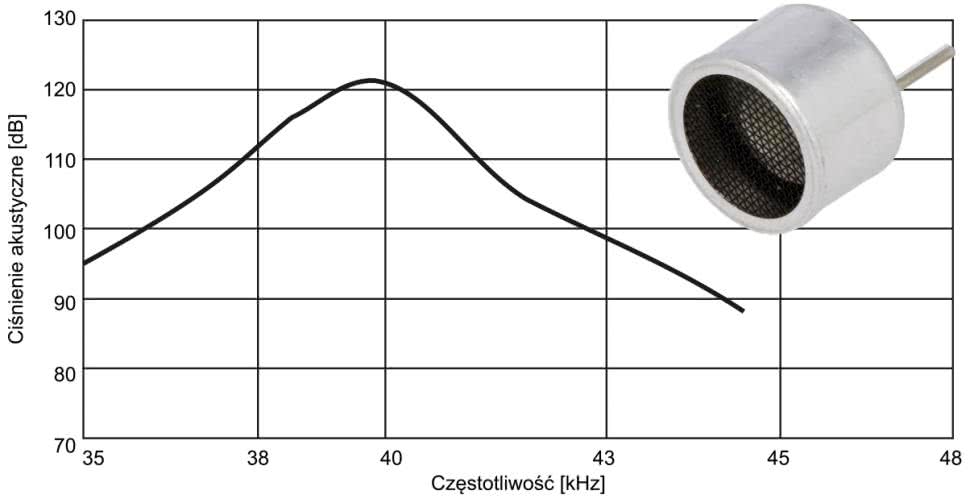
Problem jeszcze do niedawna był dość trudny do zbadania ze względu na ograniczony dostęp do mikrofonów ultradźwiękowych. Nawet jeśli można było znaleźć ofertę na odpowiedni przetwornik, to jego cena zwalała z nóg przeciętnego amatora. Są wprawdzie tanie i popularne przetworniki ultradźwiękowe, jak na przykład BPU-1640IOAH12, ale mają one dość wąskie pasmo. W zasadzie można nawet mówić, że działają selektywnie na częstotliwości 40 kHz (rysunek 3), spotykane są też przetworniki na 25 kHz.
Zbawienny stał się dynamiczny rozwój elementów MEMS. Na rynku pojawił się szereg miniaturowych mikrofonów wykonanych w tej technologii. Są to elementy bardzo małe, przeznaczone do montażu powierzchniowego. Występują zarówno w wersji cyfrowej, jak i analogowej. Mikrofony cyfrowe muszą współpracować z jakimś mikrokontrolerem, który odbiera i dekoduje zmodulowany sygnał z mikrofonu. Powszechnie stosowana jest modulacja PDM (Pulse Density Modulation). Niektóre takie mikrofony mają wydzielony tryb pracy umożliwiający odsłuchiwanie dźwięków w zakresie do ponad 80 kHz, przy względnie płaskiej charakterystyce częstotliwościowej. Dużo wygodniejsze będą jednak mikrofony analogowe ze względu na bezpośredni dostęp do sygnału analogowego, który można analizować np. za pomocą oscyloskopu.

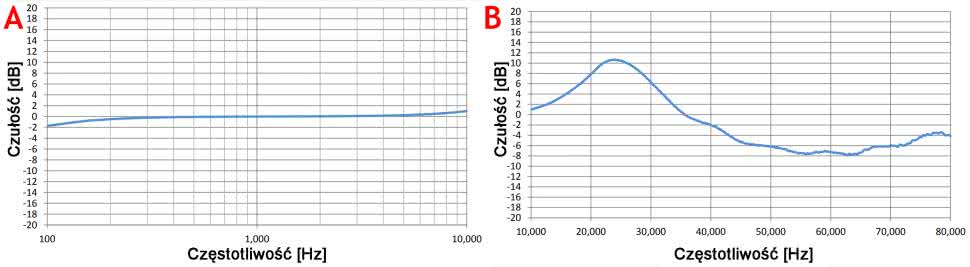
Do eksperymentów został zastosowany mikrofon SPH0641LU4H-1 (fotografia 1). Charakteryzuje się on niską ceną, ale co najważniejsze, rejestruje dźwięki do ponad 80 kHz. Charakterystyki częstotliwościowe mikrofonu zostały pokazane na rysunku 4. Charakterystyka jest niemal idealnie płaska do 10 kHz. W okolicach 25 kHz widoczne jest wyraźne 10-decybelowe podbicie czułości, ale nie będzie ono stanowiło problemu.
Układ pomiarowy
Naszym zadaniem jest jedynie obserwacja na oscyloskopie dźwięków w pełnym paśmie mikrofonu. Niestety, charakterystyka podawana w dokumentacji producenta urywa się na częstotliwości 80 kHz, nie wiadomo więc, czy mikrofon rejestruje jeszcze wyższe częstotliwości, czy nie. Na wszelki wypadek należy założyć, że wzmacniacz powinien pracować co najmniej do 100 kHz. Takie założenie może mieć pewne znaczenie dla doboru elementów wzmacniacza. Idziemy po linii najmniejszego oporu, zastosujemy wzmacniacz operacyjny, pytanie tylko jaki? Spodziewając się niewielkiego sygnału z mikrofonu, musimy przyjąć stosunkowo duże wzmocnienie wzmacniacza. Załóżmy, że powinno być ono równe 100 V/V (40 dB). Istnieje wysokie prawdopodobieństwo, że przy tak dużym wzmocnieniu nie wszystkie wzmacniacze operacyjne poradzą sobie z przeniesieniem sygnału w paśmie do 100 kHz. Upewnijmy się o tym, zanim wyciągniemy elementy z szuflady. Zobaczmy w symulatorze LTspice, czy popularny i tani wzmacniacz LM324 sprawdzi się w takiej aplikacji. Rysujemy prosty wzmacniacz o wzmocnieniu 100 V/V (rysunek 5).
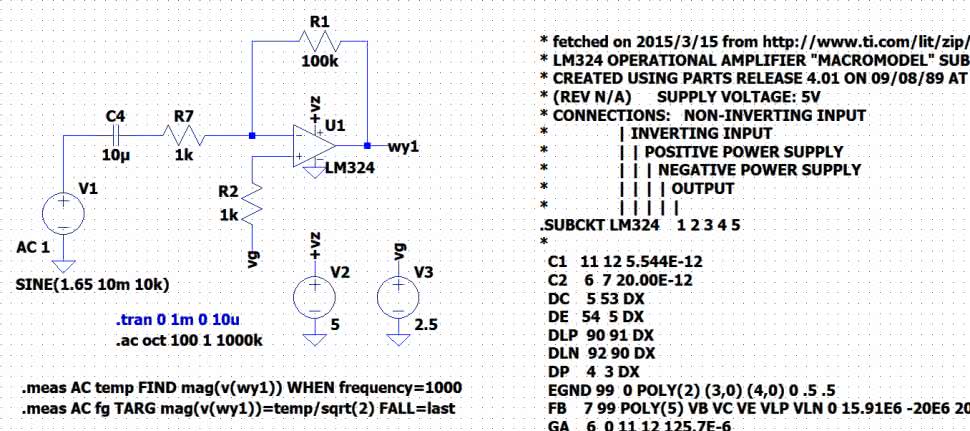
Standardowa biblioteka symulatora LTspice nie zawiera modelu tego układu, ale bez trudu można go znaleźć w Internecie. W symulacji zastosowano dwie komendy obliczające górną częstotliwość przy spadku wzmocnienia o 3 decybele w stosunku do wzmocnienia dla 1 kHz.
.meas AC temp FIND mag(v(wy1)) WHEN frequency=1000
.meas AC fg TARG mag(v(wy1))=temp/sqrt(2) FALL=last
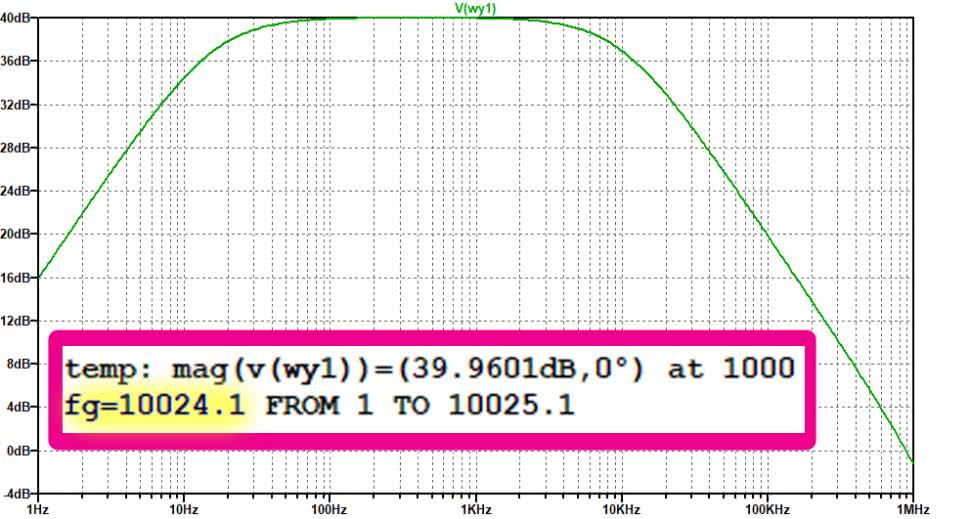
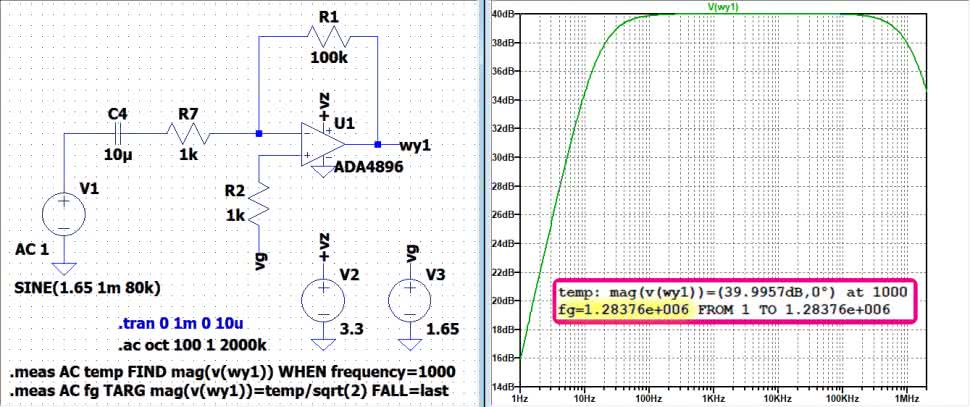
Wynik symulacji AC został pokazany na rysunku 6. Tragedia. Górna częstotliwość to zaledwie ok. 10 kHz. Taki układ nie nadawałby się nawet do zastosowań stricte akustycznych, a co dopiero do badań ultradźwięków. Sięgamy zatem o kilka poziomów wyżej. Do badań zastosujemy układ ADA4896 firmy Analog Devices. Wyniki symulacji są nad wyraz optymistyczne (rysunek 7). Górna częstotliwość jest równa aż 1,28 MHz. Trudno spodziewać się uzyskania takich parametrów w układzie zmontowanym na breadboardzie, ale z dużym prawdopodobieństwem układ powinien sprawdzić się w praktyce. Przystępujemy więc do pomiarów. Może być ciekawie.
Oglądamy dźwięki, których nie słyszymy
Pora na prezentację wyników. Przykłady potwierdzają, że otaczająca nas rzeczywistość jest zgoła odmienna od naszych wyobrażeń. Do eksperymentów został użyty zestaw Analog Discovery 2. Dostępny w nim zasilacz zasila nasz wzmacniacz, a także mikrofon.
Ze względu na ograniczenia narzucone przez mikrofon cały układ jest zasilany napięciem 3,3 V. Przebiegi czasowe są oglądane na oscyloskopie, ale nie będą nas interesować. Dużo więcej informacji dostarczą wykresy w dziedzinie częstotliwości uzyskane w oknie FFT.
Dla lepszego zobrazowania widma sygnału na wykresach został nałożony kolorem czerwonym szum otoczenia. W trakcie pomiarów nie dało się całkowicie wyeliminować wszystkich niepożądanych dźwięków. Dla lepszego uwypuklenia sygnałów rejestrowanych w paśmie akustycznym i ultradźwiękowym pasmo akustyczne (do 20 kHz) zostało zaznaczone na wykresach żółtym podkładem.
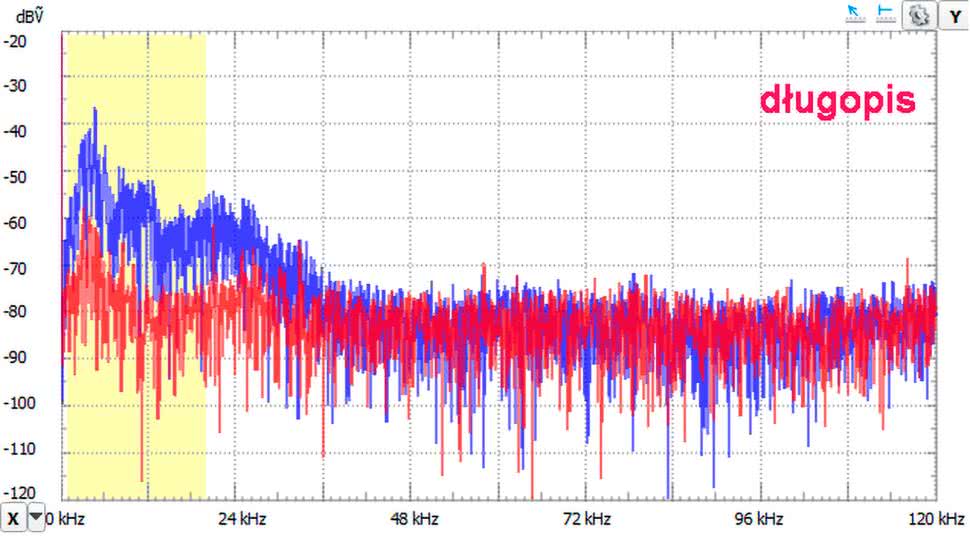
Na początek gwizdek zrobiony z długopisu. Długopis ze schowanym wkładem przytykamy do ust i delikatnie w niego dmuchamy. Trzeba pewnej wprawy, aby wydobyć w miarę czysty dźwięk, ale po kilku próbach można tę umiejętność nabyć. Tu dużego zaskoczenia nie ma (rysunek 8). Widzimy 4 wyraźne prążki widma w zakresie słyszalnym i jakąś harmoniczną w paśmie ultradźwiękowym (ok. 24,4 kHz). Wrażenia subiektywne potwierdzają te wyniki. Słyszymy w miarę czysty dźwięk, którego na pewno nie można nazwać szumem.
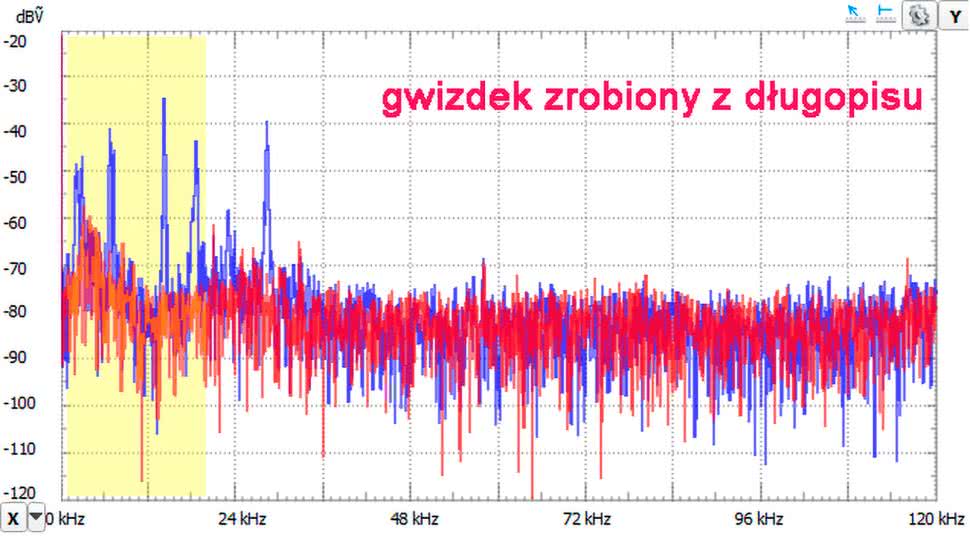
Na koniec zabawy z długopisem typu Zenith kilka razy jeszcze pstryknąłem przyciskiem do chowania wkładu. Okazuje się, że wydobywany przy tej operacji dźwięk już bardziej przypomina szum o paśmie dochodzącym do 36 kHz (rysunek 9).
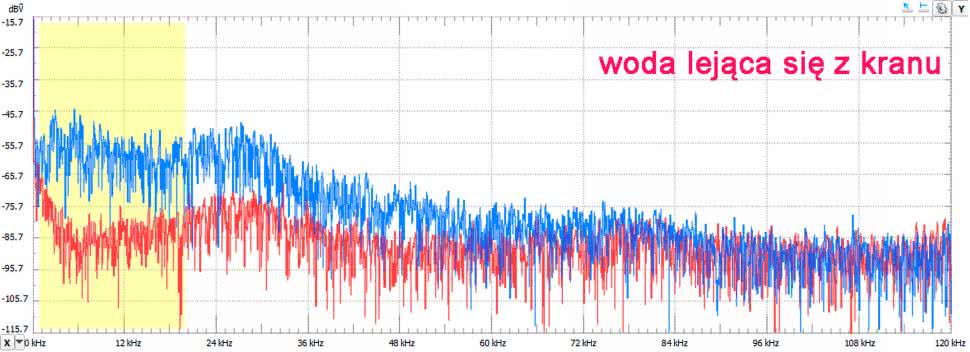
Czas na kawę. Przechodzimy do kuchni. Nalewamy wodę do czajnika. Woda lejąca się z kranu generuje dźwięki do ponad 60 kHz, chociaż przy końcu pasma są one już na bardzo obniżonym poziomie. Poziom w zakresie do 30 kHz jest natomiast w przybliżeniu równy poziomowi z pasma słyszalnego (rysunek 10).
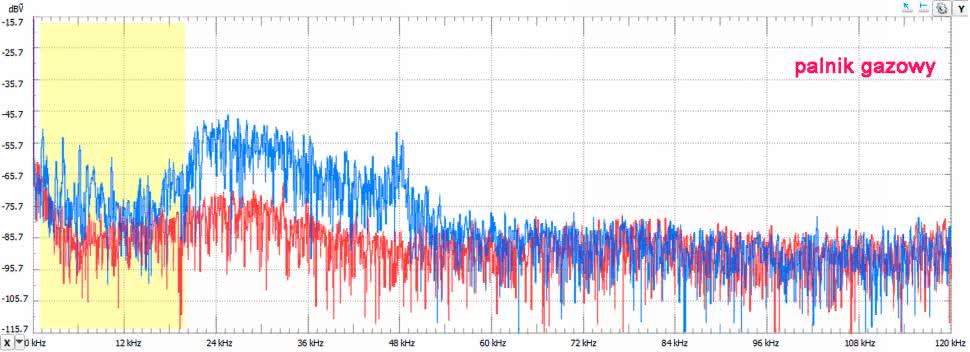
Woda już nalana do czajnika. Zapalamy gaz w kuchence. I tu się zaczyna. Okazuje się, że charakterystyczny syk palnika, który słyszymy, to dopiero początek jego aktywności. Najwięcej „hałasu” palnik robi w zakresie od 20 kHz do ok. 54 kHz (rysunek 11). Co na to koty i psy? Ciekawe, czy te zwierzęta tak jak ludzie cierpią również na szumy w uszach?
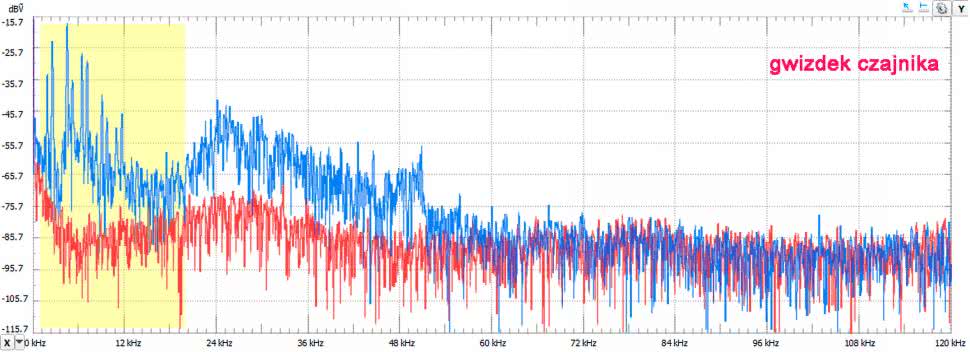
Tymczasem woda już się zagotowała. Odezwał się gwizdek czajnika (rysunek 12). Jak można się było spodziewać, na widmo palnika nałożyły się składowe z pasma akustycznego, które doskonale słyszymy. Dźwięki te mają przecież nakłonić nas do wyłączenia gazu.
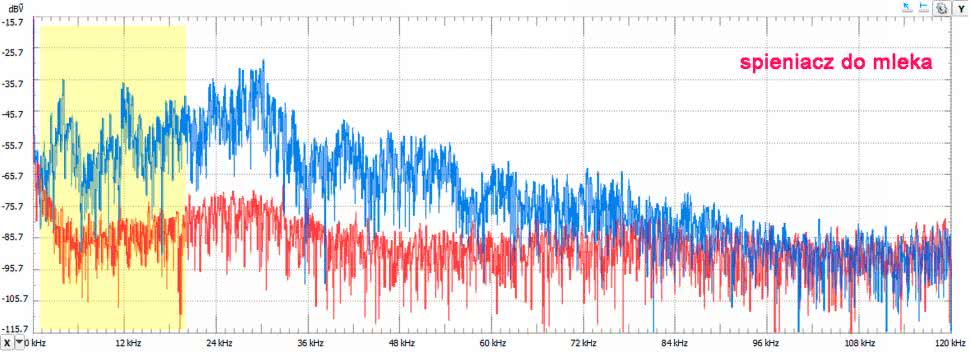
Kawa już zaparzona, pozostaje jeszcze spienić mleczko. Zastosujemy popularny ręczny spieniacz. To małe, niepozorne urządzenie generuje niezły hałas, a to, co słyszymy, to zaledwie niewielki fragment jego możliwości. Maksimum szumu wypada na około 30 kHz, ale sygnał maleje do poziomu szumów otoczenia dopiero w okolicach 93 kHz.
Podobnych eksperymentów można wykonać jeszcze dziesiątki, ale prezentowanie wszystkich nie miałoby większego sensu. Jeśli ktoś z Czytelników ma możliwość wykonania podobnych badań, zachęcam do tego. Niektóre mogą być naprawdę zaskakujące. Do klasycznych przykładów należy: odgłos drapania się po brodzie, szeleszczenia cukierkowym sreberkiem czy odbijaniem pęku kluczy.
Lepiej być człowiekiem czy psem?
Nasze zmysły zostały ukształtowane przez tysiące lat na drodze ewolucji. Żaby są dlatego na ogół zielone, bo gdyby były na przykład czerwone, byłyby lepiej widoczne, a więc bardziej podatne na zjedzenie przez gatunki żywiące się nimi. W ten sposób liczność czerwonych żab byłaby mniejsza w ogólnej populacji w porównaniu z żabami zielonymi. W kolejnych cyklach ewolucji liczba osobników przekazujących gen odpowiedzialny za czerwony kolor ubarwienia byłaby coraz mniejsza, aż do całkowitego wyeliminowania. Ostatecznie pozostałyby tylko żaby zielone, co mniej więcej obserwujemy w przyrodzie. Podobnie jest ze słuchem. Ewolucja wyposażyła poszczególne gatunki żywych istot w słuch, który ułatwiałby ich egzystencję, a może nawet umożliwiał przetrwanie. My, ludzie nie mamy potrzeby słyszenia dźwięków w paśmie ultradźwiękowym, dlatego mamy taki słuch, jaki mamy. Koty, jako zwierzęta z natury łowne, prawdopodobnie potrafią korzystać z faktu, że słyszą do 45 kHz. Pytanie, czy taka cecha jest niezbędna psom, które są gatunkiem niemal całkowicie udomowionym? Nasuwa się również pytanie: po co ludziom zdolność słyszenia dźwięków powyżej 3, 4 kiloherców, skoro sami porozumiewają się w tym zakresie częstotliwości, a polować z maczugą przestali już bardzo, bardzo dawno temu. Audiofile odpowiedzą: taki słuch jest oczywiście potrzebny do słuchania muzyki wysokiej jakości. Trudno się z taką tezą nie zgodzić.
Jarosław Doliński, EP












