 Zaloguj
Zaloguj




Sztuczna inteligencja funkcjonuje w przestrzeni publicznej w sposób nieco nieokreślony. Przypomina to czasy sprzed 8 lat, gdy w Elektronice Praktycznej zaczynaliśmy pisać o Internecie Rzeczy i ciągle pojawiały się pytania o sens IoT, bo przecież komunikacja bezprzewodowa pomiędzy urządzeniami była możliwa i wcześniej. Dopiero po latach nadeszło powszechne zrozumienie IoT jako trendu, który opisuje pewne cechy niemal wszystkich nowoczesnych urządzeń elektronicznych. Idea Internetu Rzeczy spowodowała powstanie ogromnej liczby nowych rozwiązań, które wcześniej nie miały sensu bytu.
AI jako nowy trend
Ze sztuczną inteligencją jest podoba sytuacja, choć mamy tu zasadniczą różnicę. O ile w przypadku IoT nikt nie miał zbytnio wyobrażenia, czym taki Internet Rzeczy miałby być, to w odniesieniu do AI wizji mamy bardzo wiele, prezentowanych od lat w książkach, filmach i serialach science-fiction. Rzecz w tym, że wizje te bardzo odbiegają od obecnych, praktycznych zastosowań sztucznej inteligencji. Wręcz można się często spotkać z opinią, że tworzone algorytmy i urządzenia wcale nie są inteligentne, bo nie mają cech ludzkich ani zdolności do rozumienia kwestii, do których nie zostały przygotowane. Rzeczywiście – wśród rozwiązań, które wykroczyły poza świat nauki nie mamy jeszcze przykładów urządzeń, sprawiających wrażenie inteligentnych po ludzku.
Takiej ogólnej, sprawnej, sztucznej inteligencji jeszcze nie opracowano. Ale nie oznacza to, że praktyczne rozwiązania klasy AI nie są użyteczne. Wręcz przeciwnie – są niezwykle pomocne w codziennym życiu i często nawet nie zdajemy sobie sprawy z faktu, że opierają swoje działanie o (specjalistyczną) sztuczną inteligencję. Bo to, czy dana aplikacja korzysta z AI można dosyć łatwo określić znając jej architekturę.
Od strony twórców rozwiązań, zastosowanie AI polega na pozostawieniu pewnego, choćby małego fragmentu aplikacji algorytmowi, którego parametry nie są dobierane przez eksperta. Zamiast tego, stosując odpowiednie metody, można skorzystać z wybranego, względnie generycznego (choć odpowiednio dostosowanego) modelu, którego szczegóły działania dobierane są w procesie uczenia maszynowego. Zdejmuje to z inżyniera czy naukowca problem samodzielnego zrozumienia wszystkich zależności w dziedzinie, której dotyczy realizowany projekt, a które byłyby potrzebne do zaprogramowania klasycznego algorytmu działania systemu. Pracę tę wykonują odpowiednio wydajne komputery, które same poszukują powtarzających się wzorców i innych zależności, by następnie wywnioskować w jaki sposób podobierać konkretne kryteria, na podstawie których będzie można uzyskiwać wyniki i decyzje, wartościowe z punktu widzenia użytkownika. I co ciekawe, sposobów na przygotowanie takiej aplikacji jest całkiem wiele.
Sztuczna inteligencja a uczenie maszynowe
Obok samej sztucznej inteligencji często pojawia się hasło uczenia maszynowego. Bywa, że oba te pojęcia są używane zamiennie, co jest w pewnym zakresie błędem, ale niezupełnie. Sztuczna inteligencja jest pojęciem nieco szerszym i w istotnym stopniu odnosi się nie tylko do praktyki inżynierskiej, ale i do wizji naukowej czy nawet społecznej. Sztuczną inteligencją można właściwie nazwać wszystko, co wydaje się w jakiś sposób inteligentne, a nie powstało w wyniku działań sił natury (biologii). Tymczasem do uczenia maszynowego zaliczamy zestaw całkiem konkretnych metod i algorytmów, które na różne sposoby pozwalają zbudować modele matematyczne, robiące wrażenie inteligentnych.
Można więc powiedzieć, że uczenie maszynowe to część całej, dużej dziedziny sztucznej inteligencji, odpowiadająca za budowanie modeli, ale taka klasyfikacja budzi kontrowersje. Problem w tym, że niektóre z metod uczenia maszynowego są na tyle nieskomplikowane, że ciężko je z czystym sercem nazwać sztuczną inteligencją. Dotyczy to przede wszystkim prostych statystyk, bardzo łatwych w implementacji, a nierzadko dających rewelacyjne rezultaty.
Na czym polega uczenie maszynowe?
Tak jak zostało to wspomniane nieco wyżej, na uczenie maszynowe składa się szereg metod, czy też algorytmów postępowania, które prowadzą do uzyskania rezultatu w postaci modelu realizującego określone funkcje. Co ważne, na początku takiego procesu mamy zbiory danych. Są one podstawą do przygotowania algorytmu, tak jak przeanalizowane wytyczne są podstawą do budowy klasycznych programów komputerowych czy obwodów elektronicznych. Można wręcz powiedzieć, że dane zastępują wytyczne i kreują ostateczny kształt modelu, przy mniejszej lub większej pomocy ze strony inżyniera budującego model.
Różne rodzaje uczenia maszynowego
Klasyczne uczenie maszynowe można podzielić na dwie kategorie: z nadzorem i bez nadzoru. Uczenie z nadzorem polega na wstępnym wskazaniu wytycznych, czyli np. celu klasyfikacji. Zresztą właśnie klasyfikacja może być świetnym przykładem zadania, jakie można powierzyć sztucznej inteligencji. Przykładowo, możemy zebrać szereg danych z czujników danego systemu i jednocześnie nazwać kilka stanów pracy tego systemu, które nas interesują. Podając zestawy danych wraz z przypisanymi im stanami pracy systemu i stosując któryś z algorytmów klasyfikacji (a więc klasycznego uczenia maszynowego nadzorowanego), jesteśmy w stanie uzyskać mechanizm, który pozwoli nam na całkiem poprawne klasyfikowanie kolejnych zestawów danych z czujników z takich systemów, tj. automatyczne przypisywanie im którychś ze zdefiniowanych wcześniej etykiet.
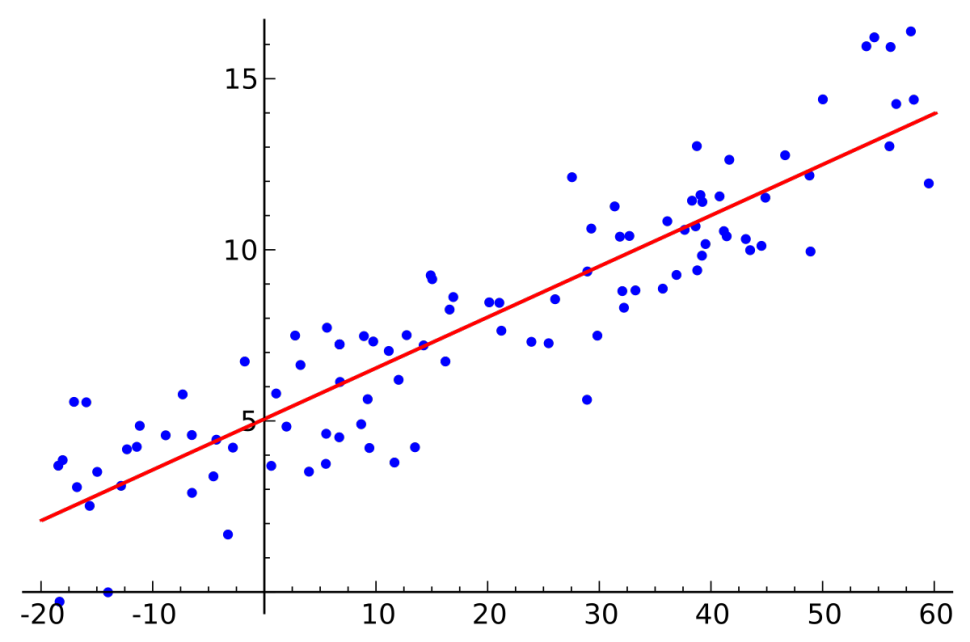
Drugim rodzajem uczenia z nadzorem jest regresja, czyli dążenie do uzyskania modelu (najczęściej wielomianowego lub ew. liniowego), na podstawie którego będzie można, w oparciu o jedne wartości wejściowe, z małym uchybem obliczać wartości wyjściowe (rysunek 1).
Zupełnie inaczej przebiega uczenie bez nadzoru. Przypomina ono pozostawienie dziecka w świecie bez nauczyciela, który mógłby mówić, jakich wyników oczekuje. Typowym przykładem jest grupowanie, które pozwala wykrywać nienazwane wcześniej stany. Można to sobie wyobrazić np. w kontekście działania pełnej czujników, złożonej maszyny przemysłowej. Jeśli nawet nie wiemy, co się może w niej popsuć, algorytm grupowania będzie mógł, w oparciu o podane dane historyczne, wyznaczyć kilka rodzajów, silnie różniących się od siebie usterek, które później będziemy mogli jakoś po swojemu nazwać. Choć może nie jest to idealny przykład, tego typu algorytmy pozwalają łączyć w grupy podobne do siebie sytuacje, których podobieństwa wcale z góry nie widać. To użyteczny zabieg, gdyż pozwala odkryć pewne schematy i połączyć ze sobą różne zdarzenia, prowadząc do wytworzenia nowych kategorii sytuacji, a w konsekwencji np. do opracowania odpowiednich metod postępowania dla poszczególnych z tych kategorii.
Podobnie jak grupowanie jest tak jakby nienadzorowaną wersją klasyfikacji, tak wyszukiwanie wzorców jest nienadzorowaną wersją regresji. Jeśli nie wiemy z góry, co od czego zależy w zbiorze danych, jaki posiadamy, to właśnie za pomocą wyszukiwania wzorców jesteśmy w stanie wykryć zależności, określić je zasadami i planować na ich podstawie dalsze działania.
Warto też wspomnieć o generalizacji, która również zaliczana jest do klasycznego uczenia maszynowego bez nadzoru. Służy do upraszczania zbiorów danych, tak by pozbyć się z nich wartości, które nie mają dużego znaczenia i które tylko zaciemniają obraz. Generalizacja nazywana jest również redukcją liczby wymiarów danych.
Uczenie ze wzmocnieniem
W powyżej opisanych metodach, uczenie maszynowe wymaga posiadania wcześniej przygotowanych zbiorów danych, a często i odpowiedzi, jakie uznalibyśmy za poprawne dla konkretnych pakietów danych. Bywają sytuacje, gdy nie umiemy z góry podać dobrej odpowiedzi, ale za to potrafimy wskazać, czy jest ona lepsza czy gorsza niż poprzednia. Korzystanie z tej wiedzy w trakcie procesu uczenia nazywamy uczeniem ze wzmocnieniem. W trakcie tego sposobu uczenia, model próbuje samodzielnie uzyskać rezultaty, za które jest nagradzany lub karany i w oparciu o nagrody dokonuje następnych zmian swoich parametrów. Tak, jak i w przypadku innych metod uczenia maszynowego, nie mamy pewności, że dysponujemy wszystkimi informacjami, które potrzebne są do precyzyjnego opisania modelu, ale mamy nadzieję, że informacje te będą wystarczające by wytworzyć model względnie dobry. W uczeniu ze wzmocnieniem jest to bardzo typowa sytuacja i algorytm (a właściwie agent, bo tak się nazywa uruchomiony algorytm), stara się maksymalizować pewne kryterium (jakąś miarę), dostępną właśnie w postaci wzmocnień.
Sieci neuronowe
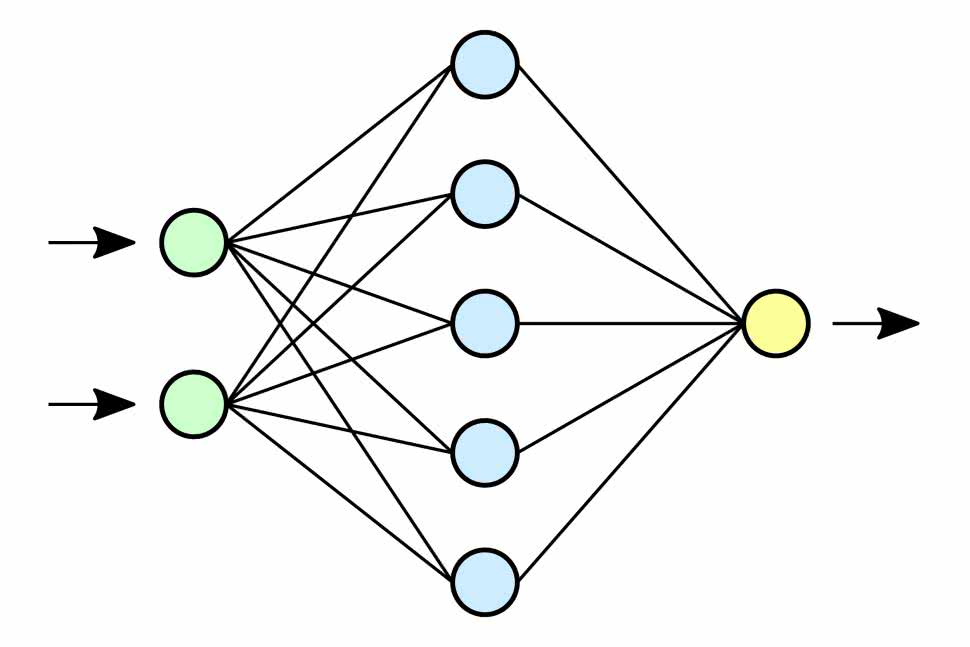
Kolejnym hasłem, jakie pojawia się w kontekście sztucznej inteligencji jest sieć neuronowa. Sieci neuronowe mogą być uczone na różne z powyższych sposobów, celem uzyskania modeli realizujących praktycznie dowolne zadania (rysunek 2). To, jak taka sieć jest zbudowana, tj. jakie neurony zastosowano, jakiego rodzaju połączenia pomiędzy neuronami i jakiego rodzaju dane i sposób trenowania są dopuszczalne, określa podtyp sieci. Wbrew względnie powszechnym przekonaniom, aby zrealizować algorytm sztucznej inteligencji wcale nie trzeba korzystać z sieci neuronowych. Wiele algorytmów opiera się o użycie zupełnie innych metod, często bazujących na statystyce.
Nic poza kreatywnością i umiejętnościami twórcy nie stoi na przeszkodzie by próbować połączyć kilka z metod uczenia maszynowego. Jest to zresztą podejście, które nierzadko pozwala uzyskiwać najlepsze rezultaty. Przykładowo, sięgnięcie po którąś z metod klasyfikacji celem wstępnego pogrupowania danych lub zastosowanie metody generalizacji, by uprościć zbiory, może znacząco ułatwić dalsze trenowanie algorytmu, a nawet jego implementację w finalnym rozwiązaniu.
Sztuczna inteligencja w elektronice
Skoro wiemy już, na czym polega sztuczna inteligencja i co teoretycznie pozwala wykonywać, można się zastanowić, jak wykorzystać ją w praktyce i jakie zastosowania może znaleźć w życiu elektronika. Takich obszarów użycia jest bardzo wiele ze względu na ogromną uniwersalność idei sztucznej inteligencji. W końcu chodzi o zastąpienie pracą maszyny niektórych czynności, wykonywanych przez człowieka, które trudno opisać prostymi zasadami i algorytmami.
Na krańcu sieci
Sztuczną inteligencję spotkamy nie tylko w urządzeniach codziennego użytku, szczególnie tych skomputeryzowanych, pracujących z chmurą. Jest obecna również w niektórych narzędziach, stosowanych przez elektroników oraz może być implementowana w rozwiązaniach przez elektroników tworzonych. Szczególnie interesująca jest idea implementacji algorytmów AI w sprzęcie, tj. niekoniecznie poprzez sprzętowe wykonywanie algorytmów, bez udziału oprogramowania, ale przetwarzanie danych na tzw. krańcu sieci.
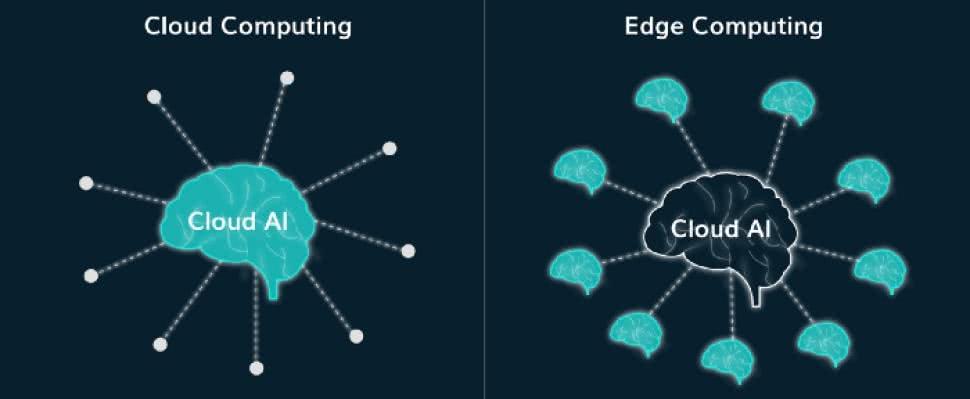
Mowa o wszelkiego rodzaju urządzeniach i ich komponentach, które stały się na tyle wydajne, że są w stanie wykonywać zaprogramowane algorytmy sztucznej inteligencji bez potrzeby przesyłania danych do sieci i korzystania z mocy obliczeniowej dostępnej w chmurze (rysunek 3). Jeszcze kilka lat temu, taka architektura była nie do pomyślenia. Teraz staje się coraz bardziej popularna, szczególnie w dobie Internetu Rzeczy, który promuje rozwiązania o małym poborze mocy, w których komunikacja z siecią sprowadza się do przesyłania małych paczek danych.
Metoda postępowania
Co ciekawe, budowanie takich sieci nadal wymaga chmury lub całkiem potężnego komputera, który posłuży do przetworzenia danych i wytrenowania algorytmu. Istnieją dostawcy rozwiązań tego typu, którzy ułatwiają wdrażanie sztucznej inteligencji na krawędziach sieci. Zazwyczaj procedura przebiega następująco:
- Użytkownik zbiera dane, które mają posłużyć szkoleniu sieci.
- Dane dzielone są na odpowiednie zbiory trenujące i testowe oraz ewentualnie na zbiór danych do weryfikacji, czy algorytm się nie przetrenował w żaden sposób.
- Dane wprowadzane są do systemu komputerowego, w którym następuje projektowanie – czy to sieci neuronowej, czy też jakiegoś innego algorytmu AI. Twórca (elektronik/specjalista od sztucznej inteligencji) kreuje całkowicie wirtualny model, aż do momentu uzyskania odpowiednio sprawnego rozwiązania.
- Gotowy model załadowany jest do urządzenia sprzętowego w postaci skompilowanego kodu, realizującego potrzebne funkcje.
Powyższa procedura sprawia, że większość pracy, związanej z przygotowaniem algorytmu, odbywa się zupełnie w oderwaniu od sprzętu i docelowego mikrokontrolera czy też innego układu aplikacyjnego. Ważne jedynie, by docelowy układ był odpowiednio wydajny do realizacji ustalonego algorytmu. Obliczenia oparte o sieci neuronowe często wymagają niemałej mocy obliczeniowej, ale na szczęście na rynku jest już dosyć dużo firm, które dostarczają układy z obwodami wspomagającymi wykonywanie algorytmów sztucznej inteligencji.
Przykłady zastosowań
Jednym z ciekawszych, z punktu widzenia elektroników, zastosowań AI jest wspomaganie projektowania układów scalonych. Typowy, nowoczesny układ scalony jest podzielony na wiele bloków, co oznacza, że ma konstrukcję modułową. Wśród modułów można wyróżnić np. bloki pamięci, jednostki obliczeniowe i układy interfejsowe. Projektant sam wybiera ile jakich bloków chciałby umieścić w tworzonym produkcie – wymaga to odpowiedniej wiedzy i zrozumienia tematu, ale jest zadaniem względnie prostym, często silnie zależnym bardziej od decyzji biznesowych i marketingowych niż inżynierskich.
Cała trudność pojawia się na etapie przekładania takiego schematu na tzw. layout, a więc rozplanowanie rozmieszczenia poszczególnych elementów. Od ich umieszczenia zależy wydajność i wiele innych parametrów powstającego podzespołu. W praktyce to właśnie od tego etapu zależy czy dany element scalony będzie konkurencyjny i sprawnie działający. Zadanie jest na tyle trudne, że pomimo dziesięcioleci badań, spełnienie wieloaspektowych kryteriów projektowych i technologicznych wymaga bardzo długiej pracy ze strony projektanta. Kluczowa jest nie tylko liczba modułów, ale ich rozmiary i parametry elektryczne, co przy milionach elementów do ułożenia, staje się niezwykle skomplikowane.
To właśnie do takich zadań użyteczna okazuje się sztuczna inteligencja. Odpowiednie wyszkolenie algorytmów powinno pozwolić na przygotowanie mechanizmu samodzielnie układającego bloki i to z dużą sprawnością. Zresztą tego typu zadania już teraz powierza się AI, co ciekawe – np. w celu budowania układów przetwarzających modele sztucznej inteligencji (np. jednostki TPU – Tensor Processing Unit).
Kolejnym przykładem zastosowania sztucznej inteligencji są aplikacje przemysłowe, głównie związane z konserwacją predyktywną. Dużym problemem w przemyśle jest trudność dokładnego przewidzenia momentu wystąpienia awarii instalacji. Ponieważ usterki tego typu powodują wstrzymanie całych linii produkcyjnych, co często skutkuje poważnymi stratami, prace serwisowe planuje się klasycznie – w oparciu o harmonogramy. Zaplanowany przestój jest dużo mniej kosztowny w realizacji niż niespodziewany – można go np. przeprowadzić w nocy lub w weekend, o ile zespół serwisowy jest skłonny pracować w takich godzinach. Rzecz w tym, że aby uniknąć nieprzewidzianych awarii, harmonogramy są planowane z zapasem, tj. tak by czynności serwisowe nastąpiły na pewno zanim maszyna ulegnie uszkodzeniu. W ten sposób naprawy prowadzone są nierzadko na maszynach całkiem sprawnych, tym bardziej jeśli realne obciążenie sprzętu nie było na tak wysokim poziomie, jak pierwotnie zakładano. Tego typu procedury są dalekie od optymalnych, ale trudno jest stworzyć sensowne algorytmy oparte o wiedzę ekspercką, które z odpowiednim wyprzedzeniem pozwalałyby na wykrywanie anomalii i przewidywały popsucie się urządzenia.
To właśnie miejsce na zastosowanie sztucznej inteligencji. W czasach, gdy czujniki przemysłowe stały się niedrogie, dokładne i łatwe do połączenia w sieć, można zestawić całkiem zaawansowane układy pomiarowe, których wyniki są następnie analizowane przez złożone algorytmy. Ręczne opracowanie takich algorytmów jest niezwykle trudne i wymaga wiedzy eksperckiej, którą zdobywa się na przestrzeni lat doświadczenia. Co więcej, poszczególne maszyny i ich wersje różnią się od siebie na tyle, że czasem trudno przełożyć wiedzę zdobytą na używaniu jednego urządzenia na praktykę sprawdzającą się w innej sztuce, pracującej np. w innym zakładzie. Sztuczna inteligencja pozwala rozwiązać ten problem. Szybko można zaprojektować algorytm do monitorowania pracy maszyny, nie znając tak naprawdę szczegółów jej specyfiki. Dobór parametrów algorytmu następuje automatycznie. Efektem jest narzędzie, które przewiduje usterki (z odpowiednim marginesem błędu), na żywo oceniając stan maszyny.
Sztuczna inteligencja może być też użyta w procesie produkcji elektroniki. Istnieją firmy, które specjalizują się w monitorowaniu produkcji i montażu płytek drukowanych, zbierając przez długi czas dane, wykorzystywane następnie celem analizy przestrzennej. Dane takie mogą opisywać procesy wytwarzania elektroniki i służyć do uczenia oraz optymalizacji algorytmów sztucznej inteligencji, by modernizować procesy produkcyjne. W nowoczesnych realizacjach tego typu stosuje się modelowanie trójwymiarowe, które daje lepszy wgląd w proces produkcyjny niż modelowanie dwuwymiarowe. Maszyny do inspekcji, obsługujące algorytmy AI, mierzą parametry charakterystyczne komponentów i połączeń lutowniczych w trzech wymiarach. Ważna jest odpowiednio wysoka jakość danych, a więc zastosowanie dobrej jakości, sensownie ustawionych czujników. Za pomocą AI maszyny te potrafią wykrywać np. odkształcenia płytek czy też problemy wynikające ze zbyt bliskiego rozmieszczenia komponentów. Analizie poddawane są zarówno informacje z systemów optycznych, jak i elektrycznych testerów. Algorytmy pozwalają na kategoryzowanie komponentów według liczby wyprowadzeń, typu i innych cech. Efektem działania omawianych maszyn jest zwiększenie uzysku produkcyjnego i poprawienie jakości procesów.
Narzędzia do AI
Zabierając się za wdrożenie sztucznej inteligencji we własnych rozwiązaniach warto wyposażyć się w odpowiednie narzędzia, ułatwiające pracę. Wiele zależy od technologii, z jakiej chcemy skorzystać, ale znaczenie ma też oczywiście sam docelowy typ aplikacji. W ogólności warto zainteresować się gotowymi zestawami elektronicznymi, przygotowanymi przez różnych producentów, które służą właśnie do rozpoczęcia prac i nauki (fotografie 1...4). Warto też podszkolić się z programowania, gdyż nierzadko będzie ono potrzebne by sensownie wdrożyć nowe rozwiązanie z dziedziny sztucznej inteligencji.




Wielu producentów oferuje co prawda gotowe biblioteki, które wystarczy skonfigurować, ale dobrze, jeśli inżynier rozumie, co właściwie dzieje się w tle w jego rozwiązaniu, choć nie można wykluczyć, że w przyszłości wystarczające będzie jedynie graficzne układanie bloków i podawanie zbiorów danych to szkolenia algorytmów.
Zestawy do sztucznej inteligencji bardzo często zawierają komponenty do obrazowania – głównie kamery pracujące w świetle widzialnym, ale czasem też systemy działające w podczerwieni. To dlatego, że bardzo wiele widowiskowych rezultatów udaje się osiągnąć właśnie w ramach systemów wizyjnych. Bez AI trudno było definiować konkretne kryteria, pozwalające na ocenianie obrazu, a tym bardziej na rozpoznawanie szczegółów. Obecnie stało się to znacznie łatwiejsze, a ilości danych, generowane przez takie czujniki obrazów przestały być już przytłaczające dla średniej wielkości mikrokontrolerów.
Do bardzo ciekawych rozwiązań należą też komponenty ze zintegrowanymi akceleratorami sztucznej inteligencji. Google opracowało kiedyś jednostki TPU (Tensor Processing Unit), a następnie jeszcze TPU Edge, przystosowane do pracy na krańcach sieci. Są one przygotowane przede wszystkim do pracy z oprogramowaniem TensorFlow – jednym z bardziej popularnych środowisk do programowania algorytmów uczenia maszynowego (rysunek 4).
Innym, ciekawym urządzeniem do AI jest Intel Neural Compute Stick, dostępny ostatnio w wersji 2 (fotografia 5). Bazuje na układzie Intel Movidius Myriad X Vision i dobrze współpracuje z takimi platformami jak Raspberry Pi. Pozwala na realizowanie głębokiego uczenia i pracę na krawędziach sieci. Producent dostarcza zestaw bibliotek funkcji i wstępnie optymalizowanych programów, a także bogate narzędzia deweloperskie.

Co na to rynek?
Opisane powyżej narzędzia do AI to jedynie niektóre z licznych przykładów, pokazujących znaczący wzrost zainteresowania sztuczną inteligencją na rynku elektroniki. Z wypowiedzi praktyków, jakie docierają do naszej redakcji oraz z rozmów z przedstawicielami firm z branży elektronicznej, jasno wynika, że sztuczna inteligencja staje się coraz bardziej powszechnie implementowanym rozwiązaniem. Nie oznacza to, że wszyscy przestawili się na tworzenie aplikacji sztucznej inteligencji i że inne projekty nie mają już racji bytu. Raczej chodzi o to, że w bardzo dużej części projektów, a szczególnie tych bardziej złożonych i najbardziej obiecujących, uwzględnienie AI jest korzystne i opłacalne.
Jednocześnie wśród kierownictwa firm oraz samych inżynierów panuje obawa o brak kadr i odpowiednich umiejętności, by sztuczną inteligencję wdrażać. Pracownicy, zajmujący się projektowaniem elektroniki nierzadko czują się niewystarczająco wspierani przez swoich pracodawców w zakresie zdobywania wiedzy o AI. Temat sztucznej inteligencji nie jest łatwy, ale po poświęceniu odpowiednio dużej ilości czasu, wiele osób będzie w stanie się z nim zapoznać i zacząć implementować rozwiązania sztucznej inteligencji, czy to samodzielnie, czy w zespołach. Na pewno warto się nim zainteresować, gdyż będą to umiejętności niezwykle przydatne już w niedługiej przyszłości. Co więcej, zapoznanie się z algorytmami AI otwiera umysł na nowe pomysły, które mogą poprowadzić do stworzenia zupełnie nowej klasy rozwiązań i niezwykle innowacyjnych urządzeń. I o ile do stworzenia uniwersalnej sztucznej inteligencji jest nam jeszcze daleko, to obecne możliwości budowania inteligencji specjalizowanej pozwalają z powodzeniem tworzyć ciekawe aplikacje oraz modernizować dotychczasowe konstrukcje, wprowadzając do nich wyjątkowo innowacyjne funkcje.
Marcin Karbowniczek, EP












