 Zaloguj
Zaloguj




Autorzy programu LTspice zaimplementowali w nim funkcję mc(wartość nominalna, tolerancja), która miała stanowić narzędzie pozwalające uzyskiwać wyniki symulacji uwzględniające rozrzut wartości elementów wynikający z ich tolerancji. Praktycy wiedzą doskonale, że gdy zbudują na przykład dwa wzmacniacze, używając elementów o takich samych wartościach nominalnych, to w zasadzie jest pewne, że nie uzyskają identycznych parametrów, takich jak wzmocnienie, pasmo itp. Powodem jest naturalny rozrzut parametrów każdego fizycznego elementu zastosowanego w układzie.
Jak działa funkcja mc?
Funkcja mc (skrót od powszechnie stosowanej w różnych symulacjach metody o wdzięcznej nazwie Monte Carlo) generuje wartość losową z przedziału
od
wartość nominalna – tolerancja * wartość nominalna,
do
wartość nominalna + tolerancja * wartość nominalna.
Przeprowadzając w jednej sesji wiele symulacji, co jest możliwe przy użyciu komendy .step param run, uzyskujemy zbiór wyników dla losowo zmieniających się parametrów elementów badanego układu. Na przykład jeśli na schemacie zostanie umieszczona komenda .step param run 1 100 1, to jedno naciśnięcie przycisku „Run” spowoduje wykonanie 100 symulacji, w których parametry elementów opisane funkcją mc będą za każdym razem zmieniane losowo. Z taką symulacją jest związany parametr RUN. W tym przypadku zmienia się on od 1 do 100 z krokiem równym 1.

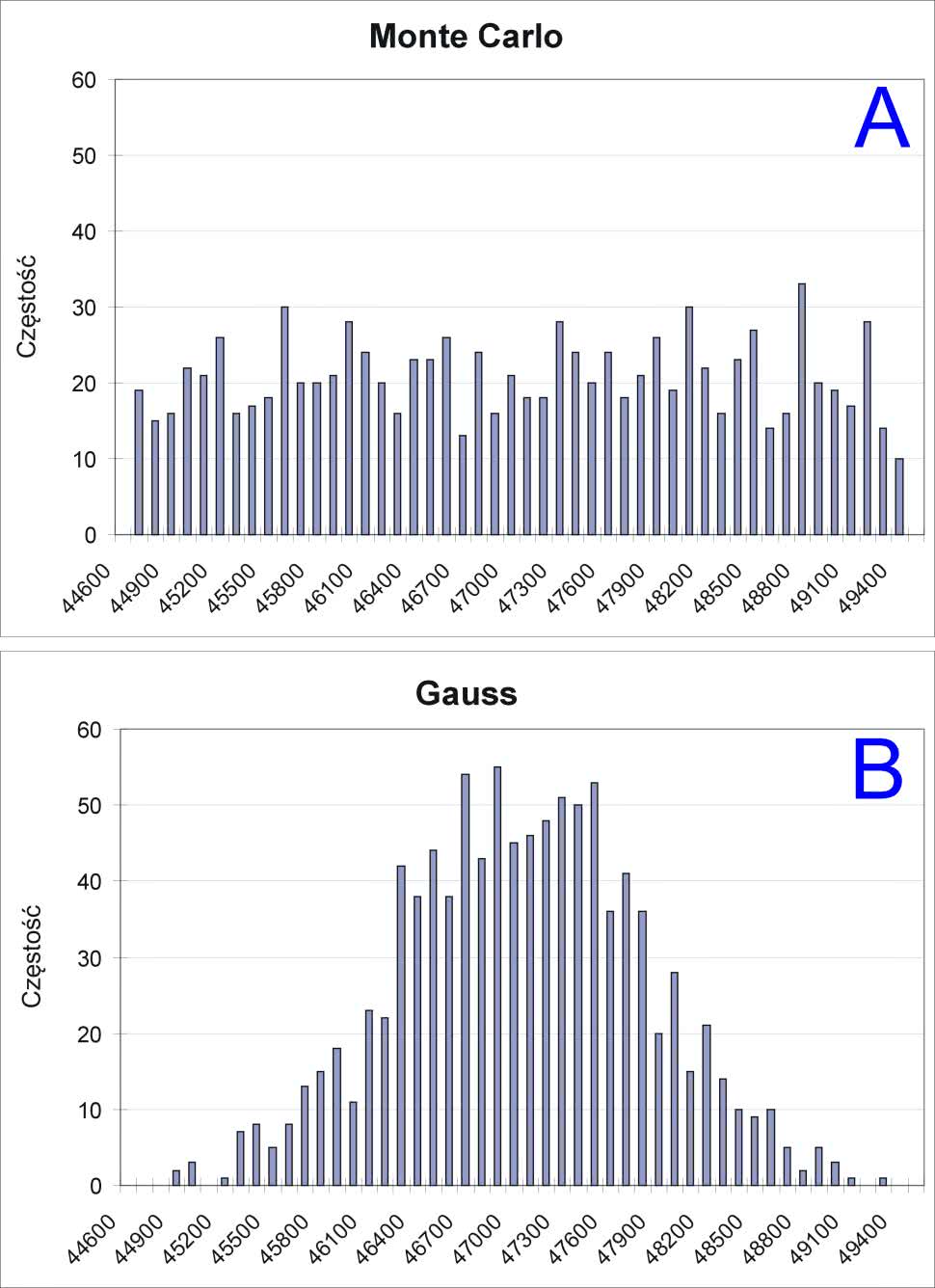
Funkcja mc korzysta z wewnętrznego generatora liczb losowych (pseudolosowych) o rozkładzie równomiernym. W każdym razie można tak z grubsza o nim powiedzieć. Jak to działa? Przekonajmy się na prostym przykładzie. Na rysunku 1 pokazano prosty układ, który zastosujemy do pomiaru rezystancji. Składa się ze źródła napięciowego i dołączonego do niego rezystora 47 kV o tolerancji 5%. Rezystancja jest więc zadana parametrycznie: {mc(47k,0.05)}. Wykonamy pomiary 300 takich rezystorów. W tym celu w oknie edytora schematów LTspice umieszczamy polecenie .step param run 1 300 1. Aby możliwy był pomiar rezystancji, należy kliknąć prawym przyciskiem myszki na tytuł okna wykresu i wpisać wyrażenie: V(wy)/I(R1). Uruchamiając symulację „DC op point” (.op), uzyskamy wykres wyników 300 pomiarów rezystancji. Widzimy, jak one się zmieniają, ale na razie nie możemy nic powiedzieć o statystyce tych zmian. Będzie to możliwe na podstawie analizy wyników w Excelu. Klikamy więc na okno wykresu i uruchamiamy polecenie File Export data as tekst. Następnie wskazujemy folder docelowy (przycisk „Browse”), nadajemy nazwę plikowi, np. pomiar_rezystancji.txt i w oknie „Select Traces to Export” wskazujemy pozycję V(wy)/I(R1). Teraz wystarczy uruchomić Excel, zamknąć wszystkie arkusze i z okna menedżera plików przeciągnąć nasz zapisany plik do Excela. Zostaje w nim otwarty arkusz z wynikami naszej symulacji. Nas będzie interesować tylko kolumna B zawierająca wartości 300 zmierzonych w programie LTspice rezystancji.

Ponieważ mają one mało czytelny zapis naukowy, można go zmienić na ogólny. Można również usunąć pierwszy wiersz zawierający nagłówki kolumn. Nie będą nam potrzebne. W polu D1 wpisujemy polecenie =min(b1:b300), które pokaże nam minimalną zmierzoną rezystancję. Podobnie w polu D2 podglądamy rezystancję maksymalną (=max(b1:b300)). Możemy już przystąpić do analizy statystycznej. W tym celu sporządzimy histogram pokazujący rozrzut wartości. W kolumnie F umieszczamy zakres zbioru. Są to liczby zmieniające się od 44600 do 49400, co 100, a więc w przybliżeniu od rezystancji minimalnej do maksymalnej. Z menu „Narzędzia” wybieramy „Analiza danych Histogram”, podając zakres komórek od B1 do B300, które zawierają zmierzone w symulatorze rezystancje. Zaznaczamy również opcję „Wykres wyjściowy”. Arkusz znajdzie się w materiałach dodatkowych do artykułu w pliku rezystory_sym_pom.xls. Wyniki tej analizy pokazano na rysunku 2.
Przy zastosowanej liczbie pomiarów rozkład jest rozmyty, ale z pewną rezerwą można go nazwać równomiernym. Dla przypomnienia, dla rozkładu równomiernego częstości występowania poszczególnych wartości powinny być teoretycznie równe, a w praktyce zbliżone do siebie. Wyniki analizy dla 3000 rezystorów zaprezentowano na rysunku 3. Ten rozkład ma wygląd znacznie bardziej podobny do rozkładu równomiernego. Na obu wykresach zaznaczono czerwonym słupkiem wartość nominalną.

Opisane doświadczenie doskonale pokazuje jakość generatora pseudolosowego użytego w symulatorze LTspice. Pytanie jednak, czy ono dobrze oddaje rzeczywistość? – na czym nam oczywiście bardzo zależy. I tu rodzi się pewna wątpliwość, gdyż rzeczywisty rozkład rezystancji rezystorów wybranych losowo z koszyka jest zupełnie inny. Jak Czytelnicy zapewne wiedzą, jest to rozkład tzw. normalny. Taki rozkład charakteryzuje się tym, że najliczniejsze są elementy o wartościach zbliżonych do nominalnych. Liczność ta zmniejsza się w miarę oddalania się od nominału symetrycznie w jedną i drugą stronę. Charakter tych zmian określa dobrze wszystkim znana, choćby ze słyszenia, krzywa Gaussa (rysunek 4).
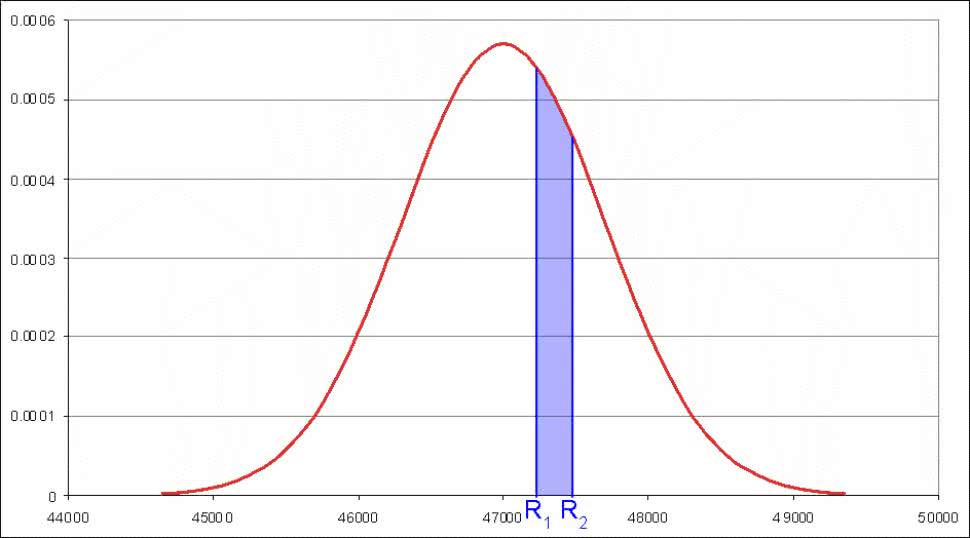
Nie będziemy tu wnikać w jej matematyczny zapis, byłby to temat trochę za ciężki na wakacyjną porę. Można tylko powiedzieć, że reprezentowana jest na niej gęstość prawdopodobieństwa pewnej zmiennej losowej, którą w naszym przypadku jest rezystancja rezystora wyciągniętego losowo z koszyka. Oznacza to, że prawdopodobieństwo np. wyciągnięcia rezystora o rezystancji z przedziału od R1 do R2 (rysunek 4) jest równe całce pod zakreślonym obszarem krzywej Gaussa. Pole od –∞ do +∞ jest oczywiście równe 1 jako prawdopodobieństwo całkowite (mówiąc uszczypliwie, tylko w wojsku może przekraczać ono wartość 1). Spokojnie, nie będziemy tego liczyć, wróćmy natomiast do świata realnego.
Zobaczmy, jak to jest w praktyce.
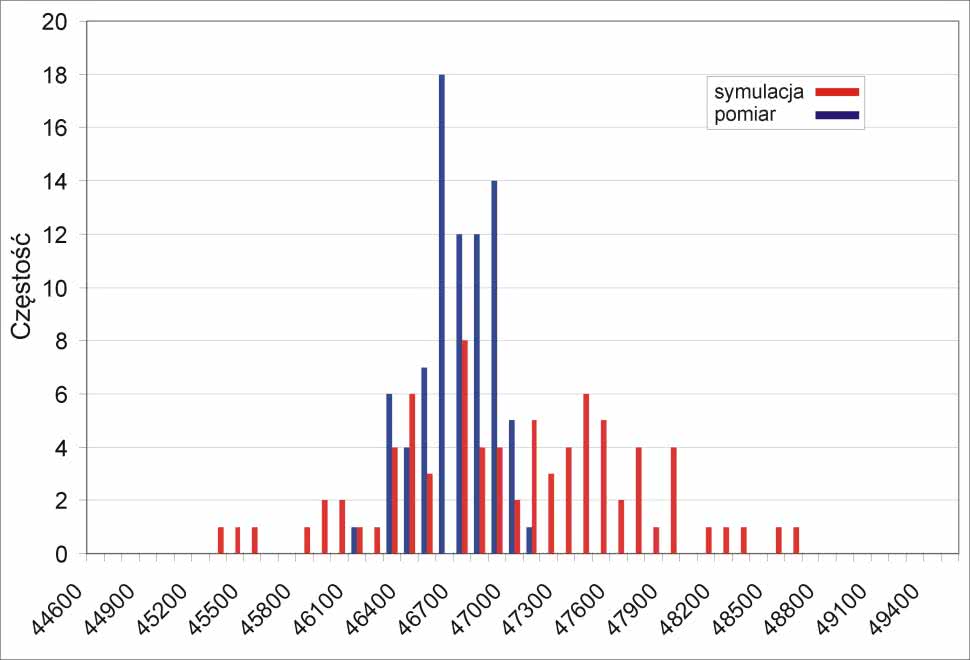
Wyciągnąłem z koszyka 80 sztuk 5-procentowych rezystorów 47 kV (tyle miałem pod ręką) i zmierzyłem ich rezystancje miernikiem Tektronix DMM914 o deklarowanej przez producenta dokładności ±(0,8%+10). Dalsze czynności były podobne do tych z symulacji, z tym że dane były już prawdziwe, ale niestety było ich znacznie mniej. Wyniki rozkładu rzeczywistych rezystancji pokazano na rysunku 5.
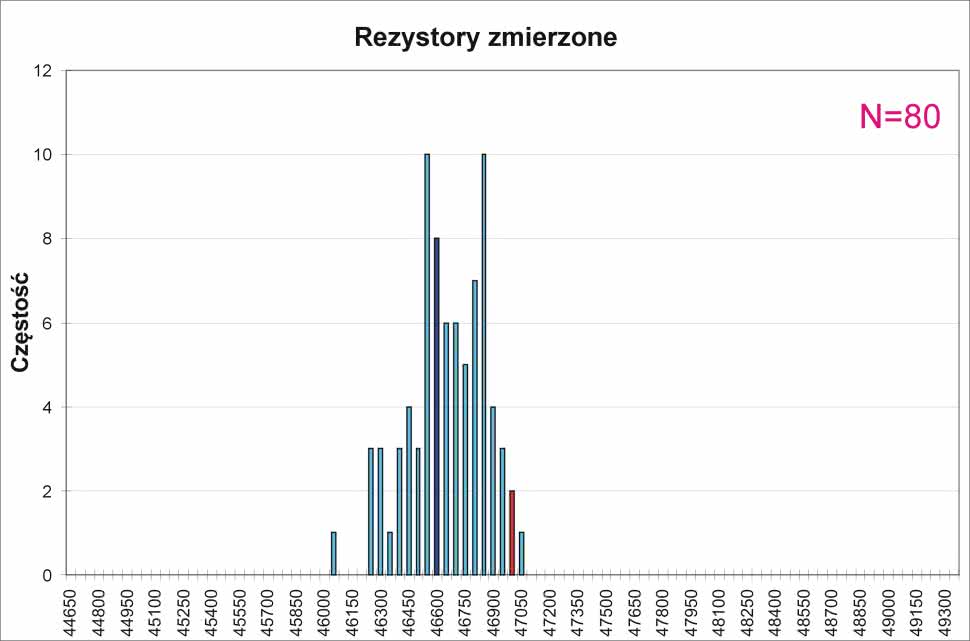
Na tej podstawie można wyciągnąć kilka wniosków. Po pierwsze, rozkład, mimo stosunkowo niewielkiej liczby danych, znacznie bardziej przypomina rozkład normalny niż rozkład równomierny. Po drugie, widoczne jest wyraźne przesunięcie rezystancji średniej od nominalnej, wynoszące 368 V. Jest to wprawdzie wartość prawie dokładnie równa dokładności miernika użytego do pomiaru rezystancji (±376,1 V), ale był on testowany też na rezystorach 1-procentowych i te pomiary wykazały poprawność wskazań. Wynika z tego, że to raczej seria produkcyjna rezystorów poddanych pomiarom charakteryzowała się wspomnianą odchyłką. Jest jeszcze trzeci wniosek: rezystory miały mniejszą odchyłkę od wartości nominalnej, niż wynikałaby z tolerancji podawanej przez producenta. W badanej serii odchyłka ta wynosiła –2,11%, +0,02%.
Pozostaje pytanie, co z tym fantem zrobić?
Czy funkcja gauss jest lepsza od mc?
Nie stoimy na straconej pozycji. W programie LTspice jest dostępna inna funkcja, która powinna rozwiązać nasze problemy. Ma ona składnię: gauss(stdv). Żeby ją zrozumieć, musimy jeszcze na chwilę powrócić do rozkładu normalnego i krzywej Gaussa. Rozkład ten jest opisany dwoma parametrami: wartością średnią (m) i odchyleniem standardowym. Odchylenie standardowe, oznaczane grecką literą sigma s, określa, w jakim stopniu wartości zmiennej losowej odbiegają od średniej. Im odchylenie standardowe jest mniejsze, tym krzywa jest węższa, ale też i wyższa (pamiętamy, że pole pod całą krzywą jest równe 1).
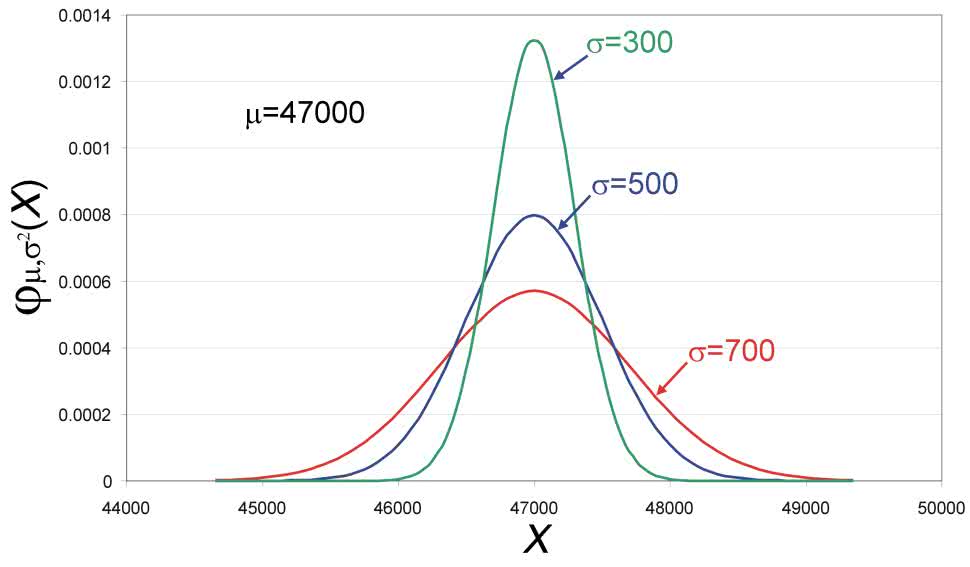
Na rysunku 6 pokazano 3 krzywe reprezentujące gęstość prawdopodobieństwa dla 3 zmiennych losowych o tej samej wartości średniej (47000) i odchyleniach standardowych równych: 300, 500 i 700. Geometryczną interpretacją odchylenia standardowego jest punkt przegięcia krzywizny krzywej Gaussa. Jakie ma to znaczenie praktyczne?
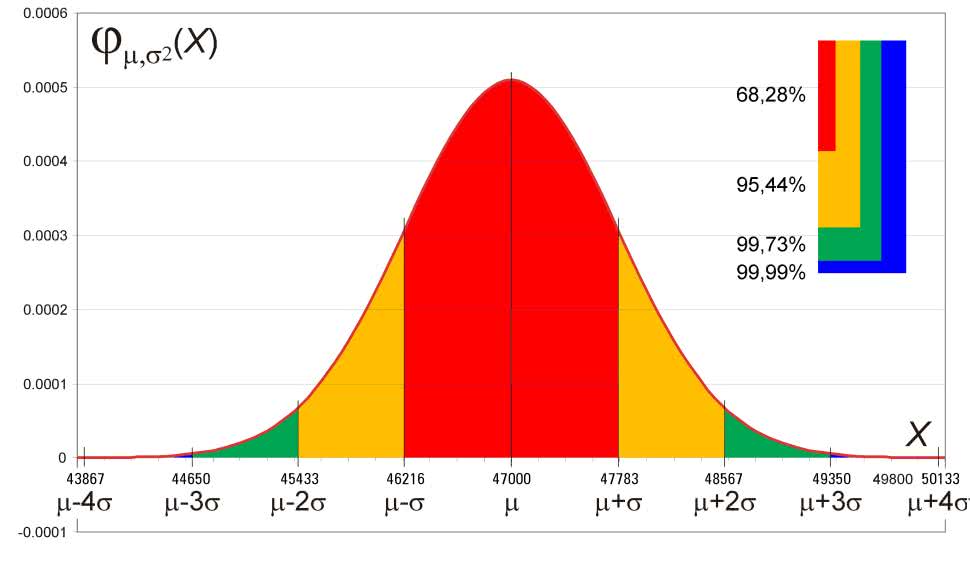
Z matematycznego opisu rozkładu normalnego wynika, jaki procent wszystkich wartości zmiennej losowej mieści się w określonym przedziale (rysunek 7). I tak dla:
-s...m...s jest to 68,88%
-2s...m...2s jest to 95,94%
-3s...m...3s jest to 99,73%
-4s...m...4s jest to 99,99%
Wynika z tego, że dla 5-procentowego rezystora 47 kV odchylenie standardowe przy założeniu, że co najmniej 99,73% wyprodukowanych elementów znajdzie się w przyjętej tolerancji, powinno być równe ok. 783 V. Powstaje tu pytanie, czy producenci biorą pod uwagę statystykę i sprzedają całą serię, ufając, że prawdopodobieństwo trafienia na element spoza gwarantowanej tolerancji jest tak małe, że nie warto sobie nim zawracać głowy, czy jednak mierzą każdy element przed zapakowaniem go do sprzedaży i odrzucają elementy niemieszczące się w tolerancji?
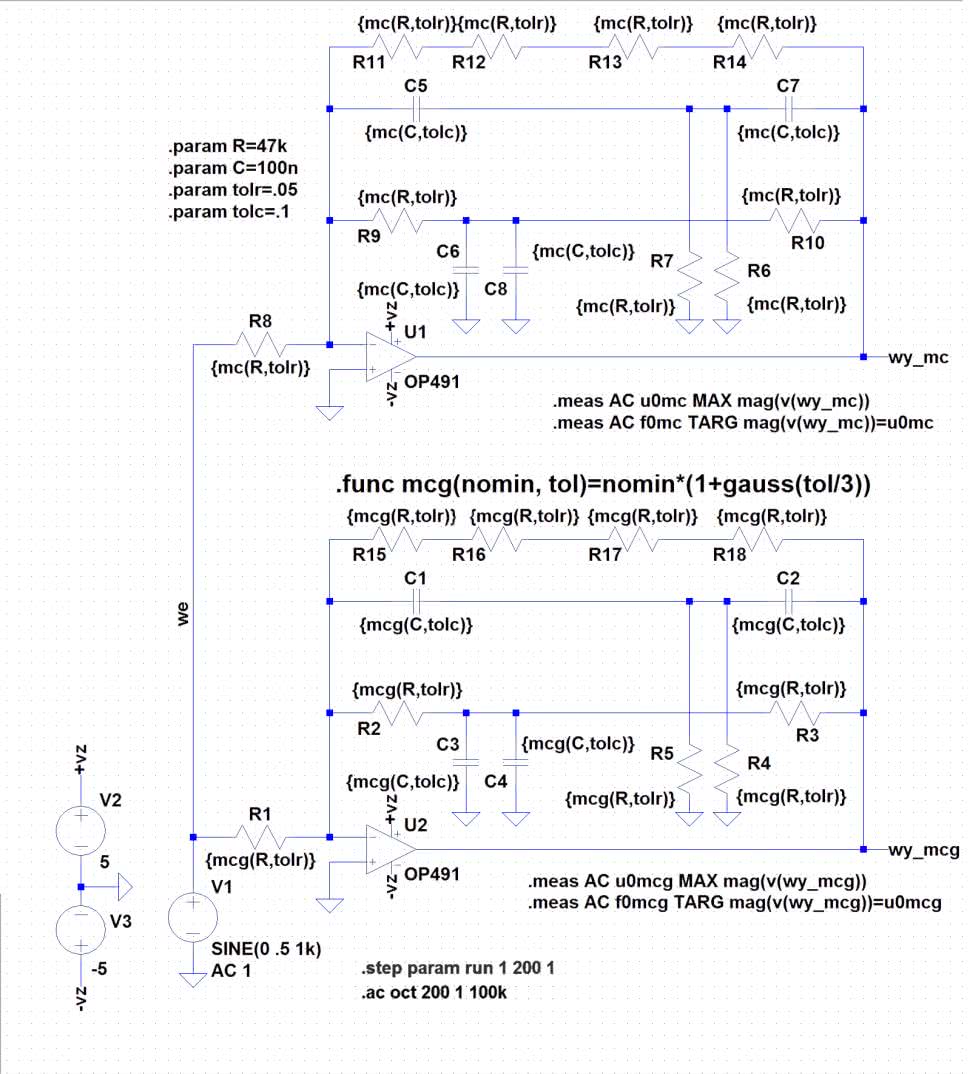
Sprawdźmy teraz funkcję gauss(stdev) w działaniu. Zwraca ona losową odchyłkę plus/minus od znormalizowanej wartości średniej równej zero, wygenerowaną zgodnie z rozkładem normalnym o zadanym parametrycznie odchyleniu standardowym. Zapewne większość Czytelników jeszcze nie wie, o co chodzi, ale przykład rozwieje wszelkie wątpliwości. Funkcja mc(nominał, tolerancja) zwracała gotową daną o losowej wartości (o rozkładzie równomiernym) mieszczącą się w tolerancji, napiszmy więc własną funkcję, która będzie działała podobnie, tylko użyty generator losowy będzie miał rozkład normalny. Naszą funkcję nazwiemy mcg i będzie ona miała takie same argumenty jak funkcja mc. Definicja jest więc następująca:
.func mcg(nomin, tol)=nomin*(1+gauss(tol/3))
Założyliśmy tutaj, że 99,75% wylosowanych wartości zmieści się w tolerancji. Stąd w argumencie funkcji tolerancja jest dzielona przez 3.

Gdybyśmy chcieli mieć większą pewność, w mianowniku powinna się znaleźć większa liczba, np. dla tol/4, zgodnie z podanymi wcześniej wnioskami, 99,99% wylosowanych wartości zmieści się w tolerancji. Schemat układu pomiarowego i wyniki wirtualnego pomiaru rezystancji 1000 rezystorów przedstawiono na rysunku 8. Pozostała jeszcze analiza statystyczna z zastosowaniem Excela. Przeprowadzamy ją dokładnie tak samo jak poprzednio, a wyniki są widoczne na rysunku 9.
Dla porządku warto jeszcze zestawić porównanie rozrzutu rezystancji 80 rzeczywistych rezystorów z analogiczną symulacją przeprowadzoną z użyciem funkcji mcg, a więc przyjmującą bliższy naturze rozkład normalny, nie równomierny (rysunek 10).
Opisane metody stworzono po to, by było możliwe szacowanie zachowania się danego urządzenia np. elektronicznego (bo są to metody stosowane nie tylko w elektronice) w pewnych przypadkach, które można uznać za skrajne. Wcześniej badaliśmy rozrzut rezystancji rezystorów, ale dużo bardziej interesujące będzie np. sprawdzenie zachowania się wzmacniacza zbudowanego z użyciem takich rezystorów, uwzględniające ponadto i inne parametry, takie jak temperatura, wahania napięcia zasilającego, współczynniki wzmocnienia prądowego tranzystorów czy wzmocnienia wzmacniaczy operacyjnych. Sprawdźmy, jak opisane metody sprawdzą się w takim zastosowaniu.
Symulacja wzmacniacza z filtrem TT w pętli sprzężenia zwrotnego
Tym razem naszym zadaniem jest symulacja wzmacniacza pokazanego na rysunku 11, a następnie praktyczna weryfikacja jego parametrów w pomiarach układu rzeczywistego. W układzie zastosowano pasmowozaporowy filtr selektywny typu „podwójne T” umieszczony w pętli ujemnego sprzężenia zwrotnego. Oznacza to, że uzyskamy wzmacniacz, o którym można powiedzieć, że jest w pewnym sensie selektywny o częstotliwości równej 1/(2*p*R*C). Dla elementów R=47 kV i C=100 nF środkowa częstotliwość wzmacniana f0 jest równa 33,9 Hz.
To „w pewnym sensie” wynika z faktu, że dla prądu stałego i niskich częstotliwości wzmocnienie nie jest równe 0, czego oczekiwalibyśmy od wzmacniacza selektywnego.
Ze względu na duże wzmocnienie dla częstotliwości mostka TT i możliwość przesterowania wzmacniacza świadomie popsujemy jego parametry, dołączając równolegle do mostka rezystor, a właściwie 4 rezystory 47 kV. Są to te same rezystory, które były wcześniej mierzone. Uzyskujemy w ten sposób dwie korzyści: zmniejszamy wzmocnienie i możliwość przesterowania, dodajemy 4 elementy decydujące o końcowych parametrach wzmacniacza. Dodanie rezystorów spowoduje również nieznaczne przesunięcie f0, ale w tym przypadku nie interesuje nas wartość bezwzględna f0, a rozrzut tego parametru wynikający z tolerancji zastosowanych elementów (rezystorów i kondensatorów). Zakładamy użycie rezystorów 5-procentowych i kondensatorów 10-procentowych.
Rozpatrywany układ jest zbudowany na wzmacniaczu operacyjnym OP491. Jak widać na rysunku 11, w naszym wirtualnym świecie narysowaliśmy dwa identyczne wzmacniacze, każdy z nich będzie jednak inaczej symulowany. Górny układ poddamy symulacji metodą Monte Carlo, w dolnym zaś zastosujemy naszą własną funkcję mcg, która, jak wiemy, używa rozkładu normalnego liczb losowych. W jednej sesji wykonamy 200 przebiegów, mierząc w każdym z nich i zapisując częstotliwość f0 odpowiadającą maksymalnemu wzmocnieniu. Naszym zadaniem będzie następnie określenie za pomocą Excela wartości minimalnej i maksymalnej dla każdej metody oraz wyznaczenie histogramów rozrzutu f0.
Do wyznaczenia częstotliwości f0 w każdym pomiarze, dla górnego układu, definiujemy polecenia:
.meas AC u0mc MAX mag(v(wy_mc))
.meas AC f0mc TARG mag(v(wy_mc))=u0mc
W pierwszej linii znajdowane jest i zapisywane w zmiennej u0mc maksymalne napięcie wyjściowe w całym przebiegu analizy częstotliwościowej.
W drugiej linii symulator zapisuje w zmiennej f0mc aktualną częstotliwość pomiarową i czyni to aż do momentu, w którym napięcie wyjściowe będzie mniejsze od u0mc. Oznacza to, że w zmiennej f0mc została zapisana częstotliwość napięcia maksymalnego i dalsza modyfikacja tej zmiennej jest już zablokowana (opcja TARG). Analogicznie postępujemy dla wzmacniacza dolnego:
.meas AC u0mcg MAX mag(v(wy_mcg))
.meas AC f0mcg TARG mag(v(wy_mcg))=u0mcg
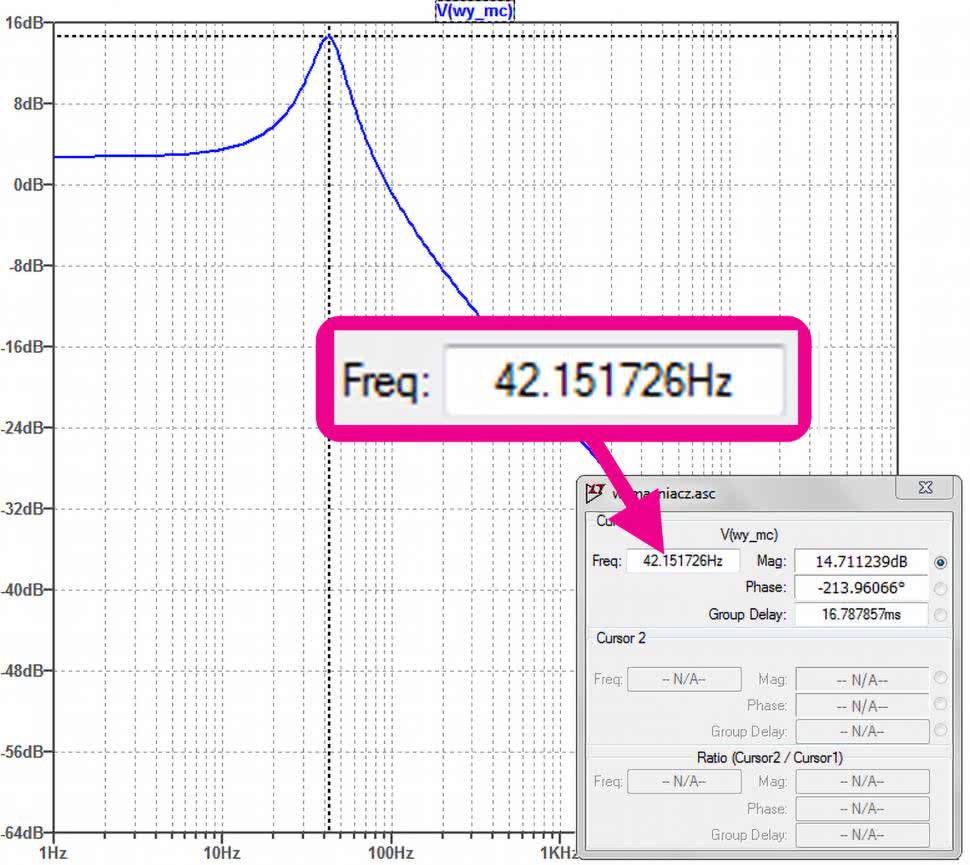
Wszystko gotowe, zatem do dzieła. Najpierw przeprowadzimy jeden pomiar, aby sprawdzić, jak wygląda ogólna charakterystyka częstotliwościowa (rysunek 12). Jak widać, potwierdza ona nasze założenia. Teraz możemy już wykonać pełną symulację składającą się z 200 przebiegów (.step param run 1 200 1). Zawężamy też zakres przemiatania częstotliwości do 10...100 Hz i przyjmujemy 200 pomiarów na oktawę. Uruchamiamy symulację .AC oct 200 1 100.
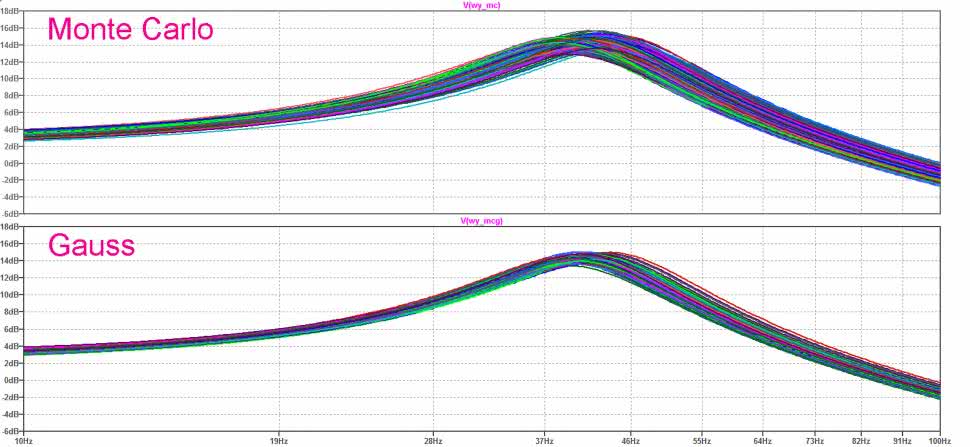
Na rysunku 13 pokazano wyniki. Górny wykres to symulacja Monte Carlo, dolny to gauss. Krzywe są dość rozmyte, więc trudno jest osądzić, który zakres zmian jest większy. Aby sprawdzić te różnice ilościowo, otwieramy okno Viev SPICE Error Log i odszukujemy dane dotyczące f0 dla obu metod (Measurement: f0mcg i Measurement: f0mc). Przenosimy je do Excela np. przez clipboard, a następnie znanymi metodami sporządzamy histogramy i określamy inne parametry, takie jak wartości minimalne, maksymalne, średnie f0 oraz zakres zmian f0 dla obu metod. Wyniki tej analizy są widoczne na rysunku 14. Na ich podstawie można wyciągnąć wniosek, że obie metody wykazały w tym przypadku duże podobieństwo.

Średnia częstotliwość f0 dla metody Monte Carlo (mieszcząca się pomiędzy wartościami skrajnymi) jest równa 41,21 Hz, a pomiar z użyciem funkcji gauss dał wynik 41,26 Hz. Analogiczne rozrzuty tej częstotliwości są równe: 7,27 Hz i 4,71 Hz. Jak można się było spodziewać, uzyskiwane wartości w metodzie Monte Carlo są bardziej równomiernie rozrzucone w całym zakresie, w pomiarach z funkcją gauss są bardziej skupione wokół wartości średniej. Sprawdźmy teraz, jaka jest rzeczywistość.
Pomiar wzmacniacza z mostkiem TT
Pomiar przebiega dokładnie tak, jak symulacja. Wykorzystujemy do tego narzędzie „Network Analyzer” w programie WaveForms. Wzmacniacz zasilamy napięciem +5 V i –5 V. Sygnał wejściowy podajemy z kanału W1 generatora arbitralnego i oglądamy go 1. kanałem oscyloskopowym.
Kanał 2. dołączamy do wyjścia. Tradycyjnie już włączamy podgląd „Time” w analizatorze, aby mieć pewność, że wzmacniacz w czasie pomiaru nie został przesterowany. Napięcie wejściowe o amplitudzie 800 mV powinno być bezpieczne.
Wstępny pomiar potwierdził wyniki symulacji. Zawężamy więc zakres badanych częstotliwości do takiego, jaki był w symulacji, a więc 10...100 Hz.
Za każdym razem będziemy wymieniać rezystory i kondensatory, czeka nas więc sporo pracy…
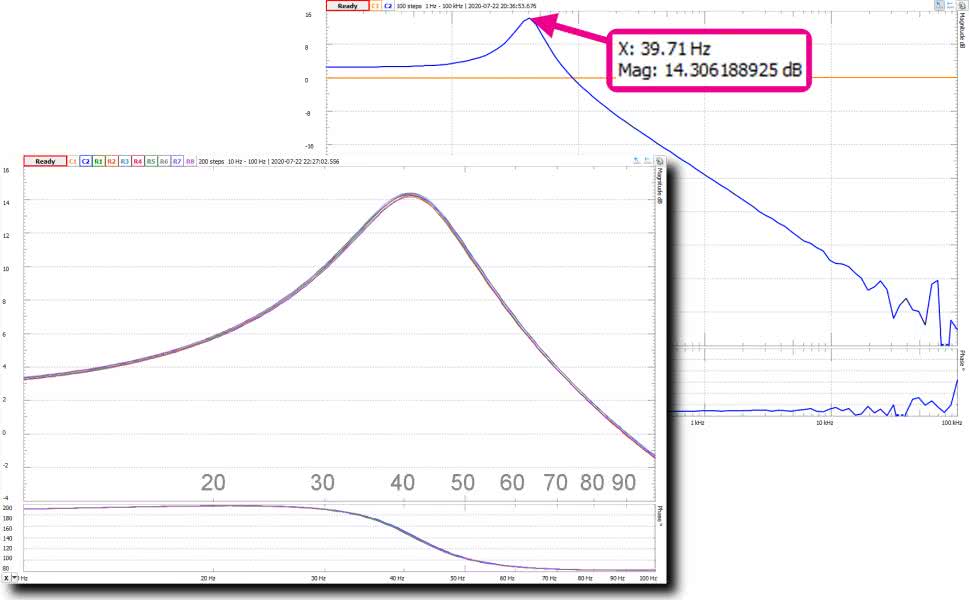
Rezystorów (i czasu) wystarczyło na zmierzenie 9 wzmacniaczy. To trochę mało ze statystycznego punktu widzenia. Czy mogą więc dziwić uzyskane wyniki (rysunek 15)? Okazało się, że rozrzut częstotliwości f0 zmieścił się w 2 krokach przemiatania częstotliwości w czasie pomiaru, a więc nie przekroczył 0,5 Hz (sic!). Różnice wzmocnienia dla częstotliwości f0 zmieściły się natomiast w 0,25 dB. W symulacji otrzymaliśmy ok. 7,27 Hz (4,71 Hz) i 2,81 dB (1,63 dB) dla metod odpowiednio mc i mcg.
Jakie stąd płyną wnioski? Niewątpliwie naszą próbę statystyczną trudno zaliczyć do wiarygodnej – była zdecydowanie za mała, ale przeprowadzenie większej liczby pomiarów ze względów organizacyjnych byłoby raczej trudne. Ale jest też inny wniosek. Pomiary rezystorów wykazały, że w rozpatrywanej serii produkcyjnej elementy miały zdecydowanie lepszą tolerancję niż gwarantowana fabrycznie. Kondensatory również pochodziły z jednej serii produkcyjnej. Być może to właśnie zadecydowało o niespodziewanie zgodnych parametrach mierzonych wzmacniaczy. Na tej podstawie nie należy jednak popadać w nadmierny optymizm, gdyż w innych okolicznościach całkiem możliwe byłoby uzyskanie innych wyników. Pretekstem do głębszego zastanowienia się byłby przypadek, w którym wyniki pomiarów przekroczyłyby przedziały z symulacji.
Worst Case
Po tych wszystkich przeprowadzonych eksperymentach człowiek rozsądnie myślący natychmiast zada sobie pytanie: po co wykonywać dziesiątki, a nawet setki przebiegów symulacji, aby określić skrajne wyniki, które i tak mogą się w symulacji nie zdarzyć, gdyż są generowane losowo?
Przecież znając tolerancje elementów, wiemy, w jakich przedziałach mogą się zmieniać ich wartości. Wystarczy więc nie losować ich, a parametry graniczne wpisać na sztywno i dla nich przeprowadzić symulację. Dodatkową korzyścią będzie wówczas 100-procentowa pewność, że znajdą się one w analizie. Metoda Monte Carlo takiej gwarancji nie daje ze względu na losowanie parametrów. Wartość graniczna po prostu może nie być wylosowana.
Implementację metody Worst Case w programie LTspice zaproponowali Gabino Alonso i Joseph Spenser z Power by Linear Group. Do realizacji tej metody zdefiniujemy dodatkowe funkcje, podobnie jak to czyniliśmy w przypadku funkcji mcg. Pierwsza z nich – wc, mająca składnię:
.func wc(nom, tol, ind) if(run==0,nom,if(binary(ind),
nom*(1-tol),nom*(1+tol)))
oblicza parametr danego elementu z uwzględnieniem odchyłki wynikającej z podanej tolerancji. Funkcja mcg ma więc takie same argumenty jak mc, czyli wartość nominalną (nom) i tolerancję (tol). Ponadto wszystkie elementy, które mają być uwzględnione w obliczeniach najgorszego przypadku, muszą być zaindeksowane. Unikatowy dla każdego elementu indeks jest podawany jako trzeci argument funkcji. Indeksowanie jest przeprowadzone ręcznie, trzeba więc bardzo uważać, aby się nie pomylić. Indeksy nie mogą się powtórzyć i muszą to być kolejne liczby całkowite, począwszy od zera. Rozpisując je binarnie, otrzymujemy tablicę zawierającą zbiór informacji o tym, czy dla danego przebiegu symulacji, podawanego za pośrednictwem zmiennej RUN, ma być obliczana dla danego elementu wartość minimalna (np. dla zera), czy maksymalna (dla jedynki). Dla RUN=0 przyjmowana jest wartość nominalna.
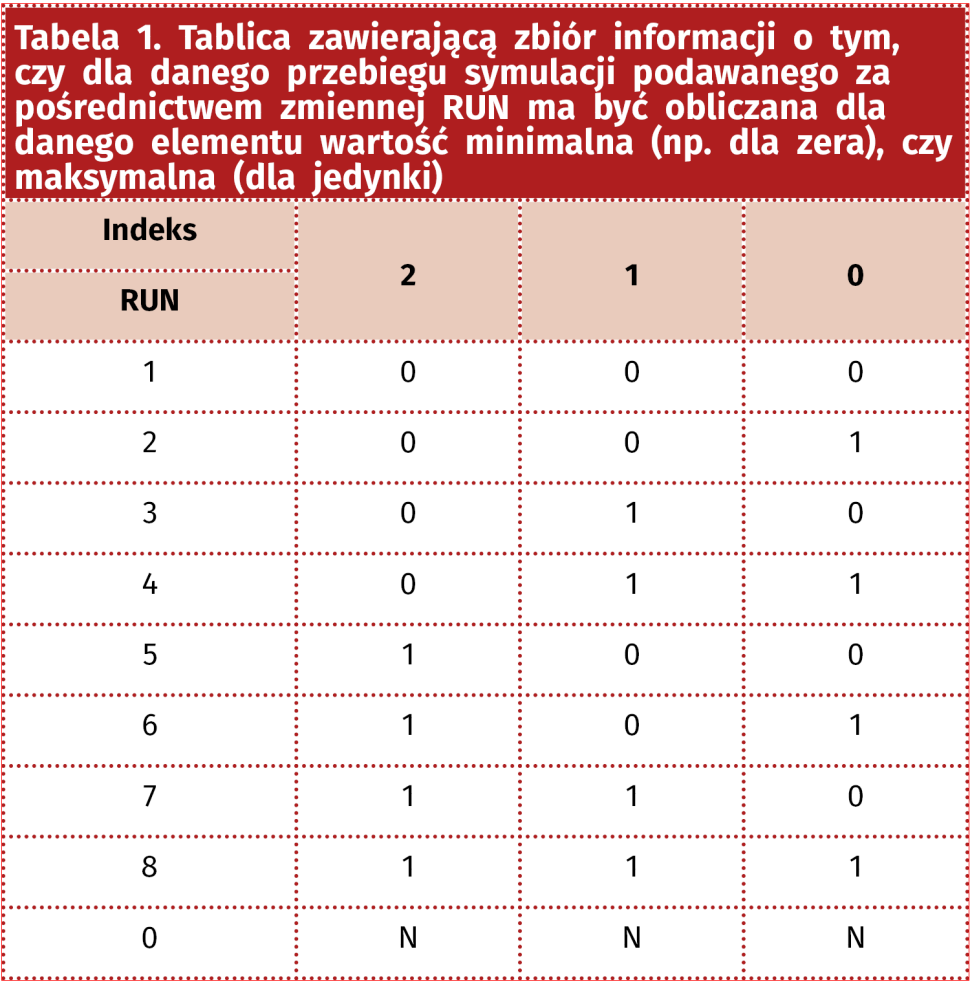
Algorytm można łatwiej zrozumieć, przyglądając się tabeli 1, sporządzonej dla 3 elementów. Przykładowo, dla przebiegu symulacji o numerze 6 element o indeksie 2 przyjmie wartość maksymalną (bo jest 1), element 1 przyjmie wartość minimalną (0), a element o indeksie 0 maksymalną (1). Funkcja binary ma zagnieżdżoną funkcję biblioteczną programu LTspice o nazwie floor(x). Oblicza ona liczbę całkowitą, która jest równa lub mniejsza od argumentu. Wygląda to dość zawile, ale po bliższej analizie zapisów funkcji wszystko powinno być jasne.
Definicja funkcji binary jest następująca:
.func binary(i) floor(run/(2**i))-2*floor(run/(2**(i+1)))
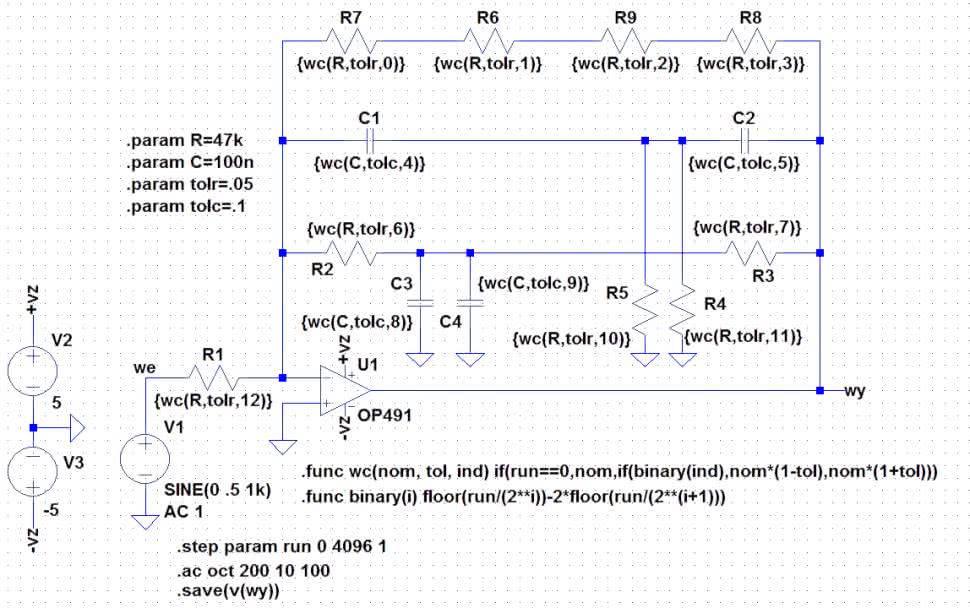
To już w zasadzie wszystko, co należało powiedzieć o metodzie Worst Case. Zmodyfikowany schemat przygotowany do symulacji pokazano na rysunku 16. Liczba przebiegów nie jest w tym przypadku obojętna, i tu zaczynają się problemy. W naszym przykładzie jest 13 elementów, które powinny być uwzględniane w analizie. Konieczna liczba iteracji jest więc równa 213=8192+1 (+1 wynika z uwzględniania wartości nominalnych), czyli 8193. Aby maksymalnie przyspieszyć pracę symulatora, warto skorzystać z polecenia .save(V(wy)). Powoduje ono matrycowanie tylko wskazanego węzła, czyli wyjścia naszego wzmacniacza. Wadą takiego rozwiązanie jest to, że po zakończeniu obliczeń widzimy tylko sygnał ze wskazanego węzła.

Pora jest późna, zapuszczam symulację i idę spać... Rano wyniki są już gotowe (rysunek 17). Okazuje się, że średnia częstotliwość f0 jest równa 41,6 Hz, a różnica między minimalną a maksymalną częstotliwością f0 jest równa aż 12,9 Hz. To 1,68 razy więcej niż w metodzie Monte Carlo i aż 2,3 razy więcej niż w symulacji z funkcją gauss.
Wnioski
Gdybyśmy budowali urządzenie decydujące np. o czyimś życiu, należałoby rozpatrywać najgorszy przypadek. Zauważmy, że metody losowe nawet nie zbliżyły się do najgorszego przypadku. W produkcji, szczególnie wielkoseryjnej, nie można wykluczyć, że użyte elementy spełnią takie kryteria.
Prawdopodobieństwo takiego zdarzenia jest jednak niewielkie. Bardziej życiowo parametry urządzenia oddaje symulacja z funkcją gauss. Gdyby producent oparł się na tych wynikach i określił na ich podstawie parametry urządzenia w specyfikacji technicznej, musiałby się gęsto tłumaczyć z ewentualnych reklamacji zgłaszanych przez użytkowników w przypadku niespełnienia podawanych parametrów. Sytuacja trochę przypomina ubezpieczenia. Towarzystwa ubezpieczeniowe szacują na podstawie obserwacji statystycznych stawki ubezpieczeniowe i kwoty wypłat odszkodowań, zakładając, że określony procent poszkodowanych nie będzie dociekać swoich praw. A jeśli już trafi się jakiś bardzo uparty klient (mający rację, o czym dobrze wiedzą), to zgadzają się na stawiane warunki i nawet nie wysyłają swojego przedstawiciela na ewentualne rozprawy sądowe. To są prawa statystyki. Ich nadużywanie może jednak podważyć reputację firmy.
Jarosław Doliński, EP












