 Zaloguj
Zaloguj




W tej części kursu będzie dużo teorii. Problemy, jakie będziemy dzisiaj poruszać, są niezwykle ważne, a wręcz fundamentalne. Brak znajomości tych zagadnień może prowadzić do bardzo irytujących błędów, które mogą być bardzo trudne do wykrycia i naprawienia. Jednak bądź dobrej myśli! Niedługo stwierdzisz, że to wcale nie jest takie trudne i nauczysz się zręcznie omijać pułapki.
Glitch
Zacznijmy od prostego eksperymentu, który uświadomi nam pewien problem, którym obarczony jest każdy układ kombinacyjny. Zastanówmy się nad banalnym schematem, który pokazano na rysunku 1.
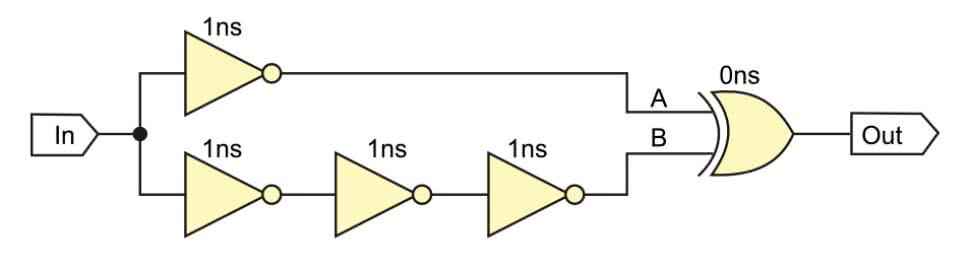
Na schemacie są tylko cztery bramki NOT i jedna bramka XOR. Ich tablice prawdy dla przypomnienia pokazano w tabelach 1 i 2. Układ ma tylko jedno wejście, oznaczone jako In oraz jedno wyjście Out.
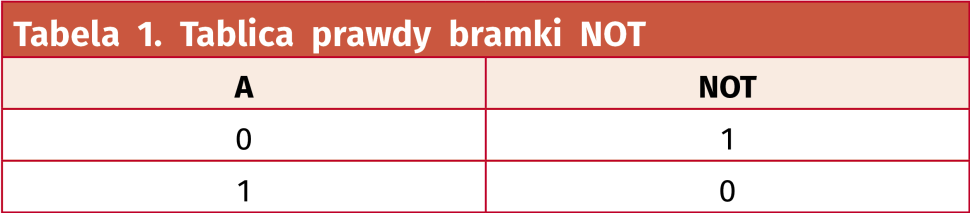
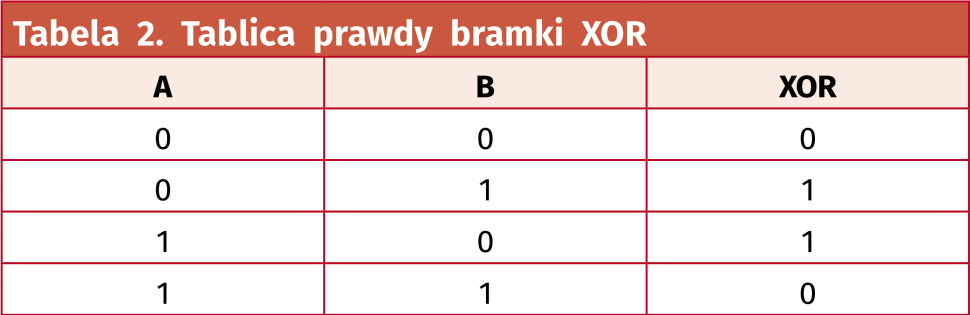
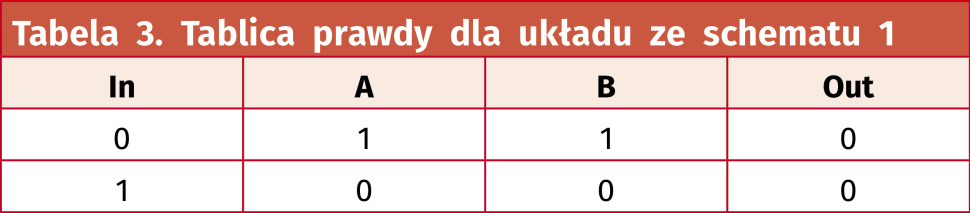
Spróbujmy teraz stworzyć tablicę prawdy dla całego układu. Jest tylko jedno wejście, które może przyjmować stan 1 lub 0, więc musimy przeanalizować tylko dwie możliwości, jakie mogą wystąpić na wejściu In. W tablicy uwzględnimy także punkty pośrednie A i B, które są wejściami bramki XOR. Wynik tej symulacji zaprezentowano w tabeli 3. Okazuje się, że obojętnie jaki stan jest doprowadzony do wejścia In, to na wyjściu Out zawsze jest stan niski.
W naszej prostej symulacji nie uwzględniliśmy bardzo ważnego czynnika – czasu propagacji. Jest to czas, jaki mija pomiędzy ustaleniem się stanu na wejściu układu, a ustaleniem się stanu jego wyjścia. Załóżmy, że bramki NOT mają czas propagacji równy 1 nanosekundzie, a bramka XOR niech ma zerowy czas propagacji (dla wygody) – czasy propagacji bramek podano na rysunku 1 nad symbolami bramek. Aby przeprowadzić symulację czasową, już nie wystarczy prosta tabelka. Potrzebujemy wykres, jaki znajduje się na rysunku 2. Naszą sekwencją testową, którą byśmy umieścili w testbenchu pisząc kod w Verilogu, niech będzie jedynie przełączenie się sygnału In ze stanu 0 na 1, a następnie niech ten sygnał pozostaje bez zmian, aż do końca symulacji.
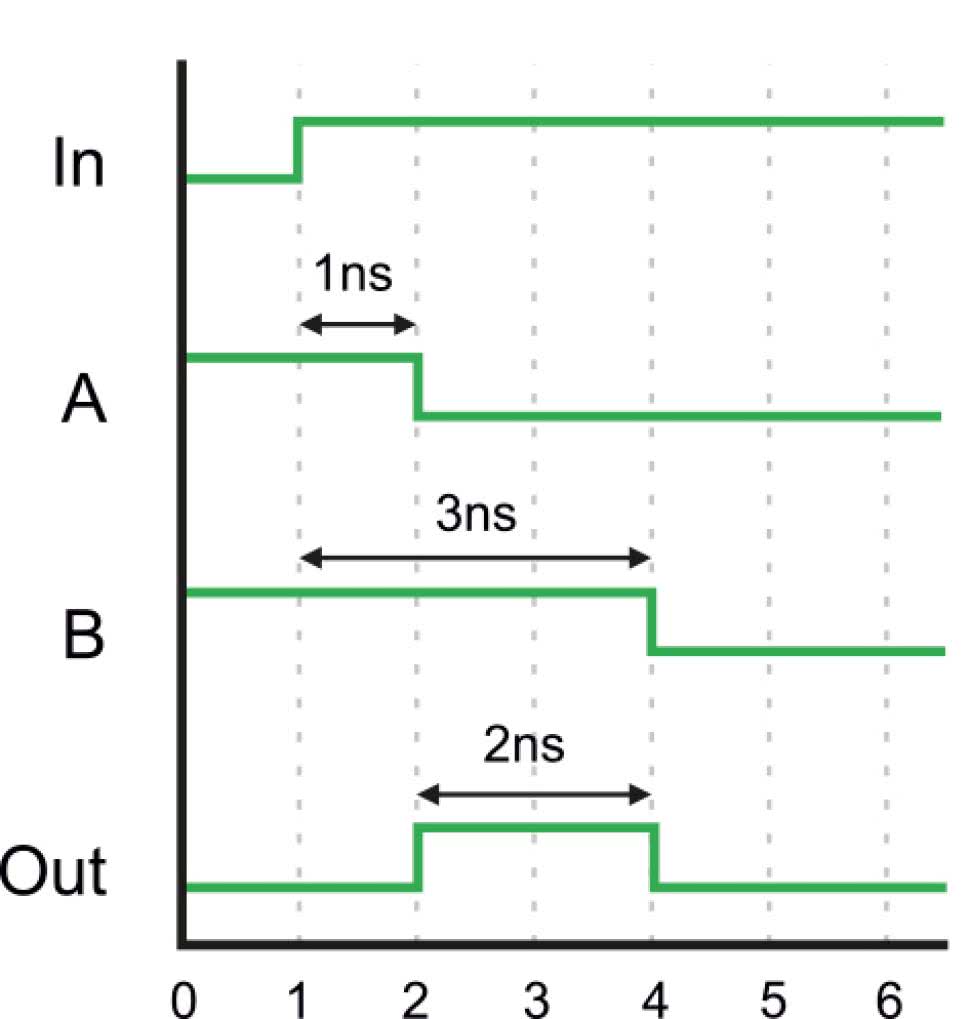
Sprawdźmy, co będzie działo się w punkcie A. Sygnał przechodzi przez jedną bramkę NOT, więc zostanie zanegowany. Jednak ta bramka ma czas propagacji 1 ns, więc efekt negacji zobaczymy po upływie 1 ns. W punkcie B mamy podobną sytuację, lecz sygnał musi przejść przez trzy bramki NOT, więc stan tego punktu ustali się po upływie 3 ns. Co się dzieje wtedy z bramką XOR? Zwróć uwagę, że przez czas 2 nanosekund na wejściu A jest stan niski, a na wejściu B jest stan wysoki. Zgodnie z tabelą 2, w takiej sytuacji wyjście bramki XOR powinno ustawić się w stan wysoki! Dopiero, kiedy łańcuch bramek NOT przetworzy zmianę sygnału, to na obu wejściach A i B ustali się stan niski. Wyjście bramki XOR przełączy się ponownie w stan niski po upływie 3 ns od zmiany stanu wejścia In (gdybyśmy chcieli uwzględnić czas propagacji bramki XOR, wtedy wykres Out należałoby przesunąć w prawo o czas propagacji tej bramki).
Okazuje się, że przez czas dwóch nanosekund wyjście na wyjściu układu jest krótka szpilka, której nie powinno być. Jest to tzw. glitch. Ta krótka szpileczka może powodować bardzo poważne problemy. Gdybyśmy odczytali wyjście Out, zanim ustali się jego stan, to byśmy otrzymali nieprawidłową wartość tego sygnału. Ten nieprawidłowy stan przedostałby się do dalszych bramek, przerzutników, multiplekserów, przez co nasze urządzenie działało by w sposób nieprawidłowy!
Glitch jest zjawiskiem występującym w układach kombinacyjnych. Im bardziej skomplikowany układ, tym więcej ścieżek jest do przeanalizowania i tym więcej różnych glitchy może powstać. W naszym prostym układzie mamy tylko dwie ścieżki. Jak ten problem rozwiązać? Z pomocą przychodzi przerzutnik D.
Przerzutnik D (flip flop)
Ten typ przerzutnika jest koniem pociągowym całej elektroniki cyfrowej. W zasadzie wszystkie przerzutniki jakie mamy w FPGA to w gruncie rzeczy przerzutniki D. Litera D oznacza delay, czyli opóźnienie. Przerzutnik jest najprostszą formą pamięci cyfrowej i ma pojemność jednego bitu. Może przechowywać stan niski lub wysoki przez dowolnie długi czas, tak długo jak oczywiście zasilanie układu jest włączone. Kilka symboli przerzutników D pokazano na rysunku 3.
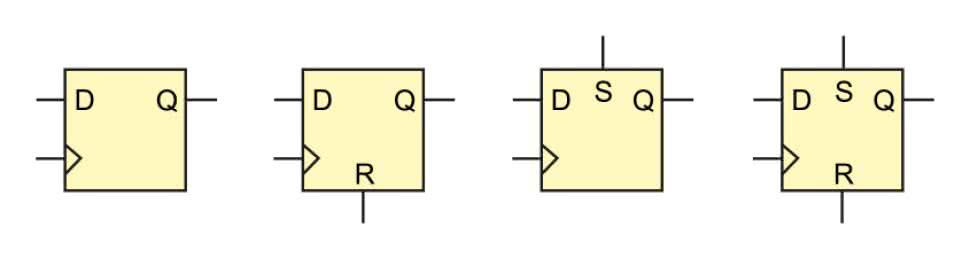
Przerzutnik D ma co najmniej trzy wyprowadzenia:
- D – wejście danych,
- Q – wyjście danych,
- C (oznaczane też znakiem trójkąta) – wejście zegara.
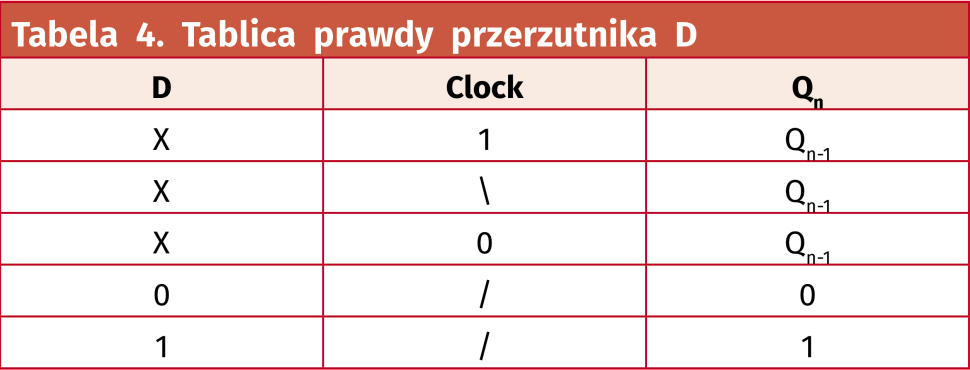
Tablicę prawdy przerzutnika D pokazano w tabeli 4. Przerzutnik jest układem sekwencyjnym. To znaczy, że stan jego wyjścia zależy nie tylko, od obecnego stanu wejść, ale także od stanów, jakie były w przeszłości. Obecny stan wyjścia oznaczamy jako Qn, a stan z poprzedniego cyklu zegarowego oznaczamy symbolem Qn-1. Symbol / oznacza zbocze rosnące, czyli zmianę stanu z 0 na 1, a symbol \ to zbocze opadające, czyli zmianę z 1 na 0. Znak X oznacza, że stan jest nieistotny, obojętnie niski czy wysoki.
Przerzutnik D reaguje jedynie na zbocze rosnące sygnału zegarowego. Wtedy stan wejścia D jest przepisywany na wyjście Q. Kiedy wejście zegarowe przyjmuje stan niski, wysoki lub jest zbocze opadające, to stan wejścia D może się dowolnie zmieniać, a wyjście Q pozostaje cały czas niezmienione. Oprócz tego można spotkać dodatkowe wyprowadzenia:
- S – wejście asynchroniczne set, ustawiające natychmiast wyjście Q w stan wysoki bez względu na stan pozostałych pinów,
- R – wejście asynchroniczne reset, ustawiające natychmiast wyjście Q w stan niski bez względu na stan pozostałych pinów,
- !Q, Q z kreską na górze – zanegowane wyjście.
Jednoczesne ustawienie wejść S i R w stan wysoki jest niedozwolone. Wejścia S i R są najczęściej używane podczas inicjalizacji stanu przerzutnika po włączeniu zasilania lub zresetowaniu układu.
Dochodzimy do wniosku, że skoro przerzutnik D kopiuje stan wejścia na wyjście tylko w momencie zbocza zegara, to możemy go zastosować jako „izolator” pomiędzy blokami logiki kombinacyjnej. Usprawnijmy więc schemat, dodając do niego przerzutniki D, jak jak pokazano to na rysunku 4. Za wejściem oraz przed wyjściem zostały dodane dwa przerzutniki D, które taktowane są tym samym sygnałem zegarowym. Przerzutniki powinny mieć także wspólny sygnał resetujący, ale dla uproszczenia go pominięto. Przerzutnik przy wejściu In będziemy nazywać przerzutnikiem nadającym, a ten przy wyjściu Out będzie przerzutnikiem odbierającym.
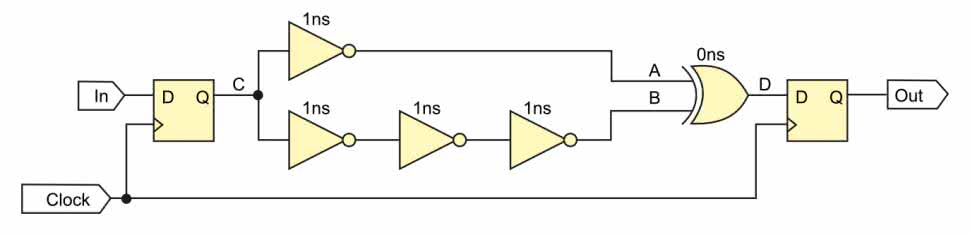
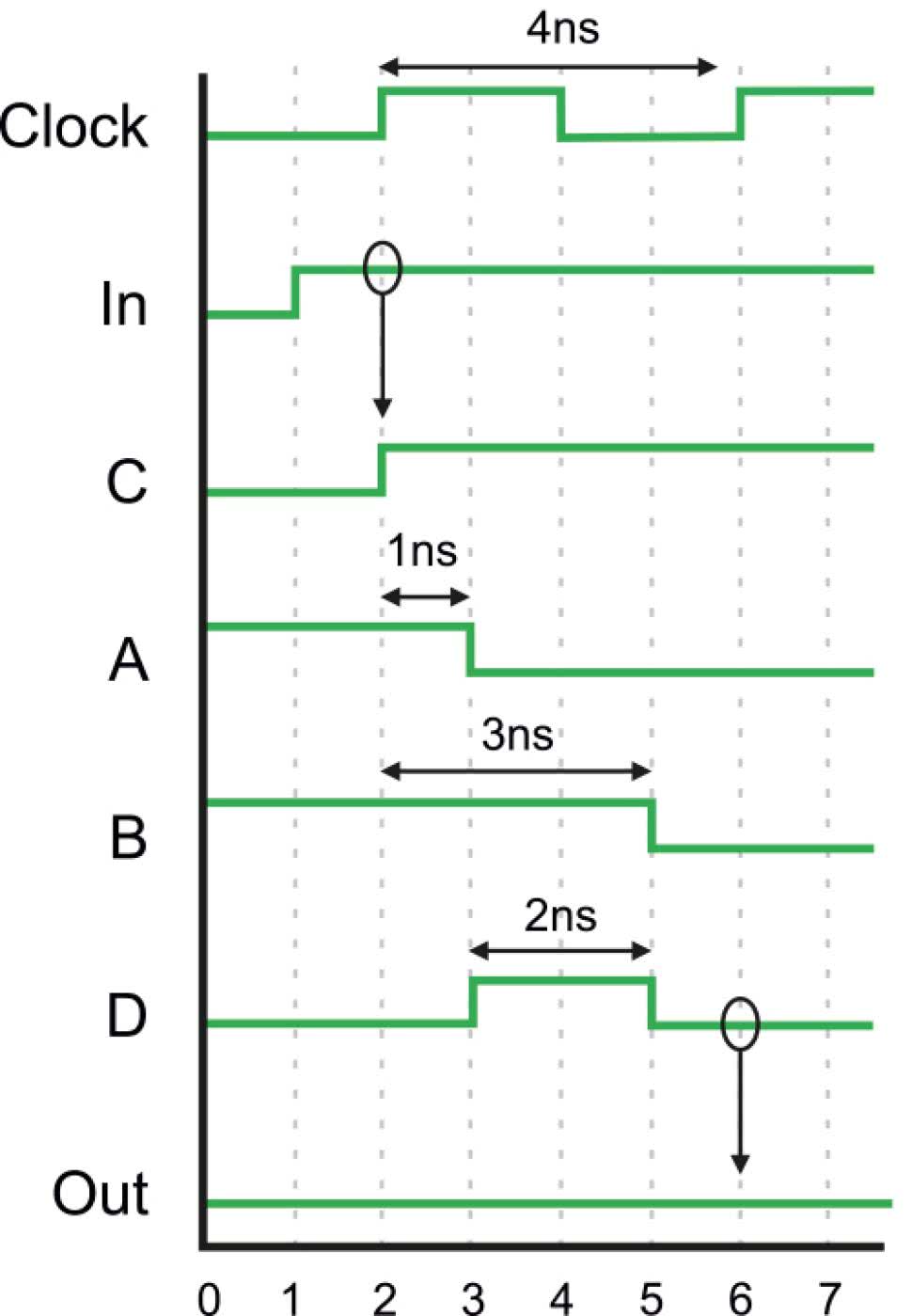
Prześledźmy teraz przebiegi poprawionego układu, które pokazano na rysunku 6. Dla uproszczenia przyjmujemy, że przerzutniki mają zerowe opóźnienie. Podobnie jak wcześniej, sygnał wejściowy In zmienia swój stan z niskiego na wysoki, co widać w pierwszej nanosekundzie symulacji. Następnie, w drugiej nanosekundzie, mamy zbocze rosnące sygnału zegarowego (odstęp między zboczami sygnałów In oraz Clock jest celowy – będzie to wyjaśnione w dalszej części artykułu). Zbocze rosnące sygnału zegarowego powoduje, że przerzutnik nadający kopiuje stan swojego wejścia na wyjście. Z tego powodu stan w punkcie C zmienia się z niskiego na wysoki, a następnie bramki zaczynają przetwarzać sygnał z wyjścia przerzutnika nadającego. Przez kolejne kilka nanosekund wszystko dzieje się tak samo jak w poprzednim przykładzie.
Sygnał na wyjściu bramki XOR widzimy w punkcie D. Jest tam obecny ten sam glitch, co w pierwszym przykładzie. Jednak glitch nie przedostaje się do wyjścia Out, ponieważ między nim, a wyjściem bramki XOR jest przerzutnik D. Stan bramki XOR trafia na wyjście układu dopiero w szóstej nanosekundzie, kiedy mamy kolejne zbocze rosnące sygnału zegarowego, co zaznaczono strzałką – jednak nie widzimy żadnej różnicy na linii Out, ponieważ stan niski jest zamieniany na stan niski. Wszak nasz układ ma zawsze dawać stan niski, niezależnie od tego, co znajduje się na jego wejściu.
Możemy dojść do wniosku, że zastosowanie przerzutników D w gruncie rzeczy nie rozwiązuje problemu, ale go ukrywa. Mimo to, umieszczanie przerzutnika D za blokiem logiki kombinacyjnej pozwala lepiej zapanować nad tym, co się dzieje w naszym projekcie. Dzięki temu rozwiązaniu, wszystkie bloki kombinacyjne dostają „nowe dane” wraz ze zboczem zegara i muszą zdążyć je przetworzyć przed kolejnym zboczem sygnału zegarowego.
Zastanówmy się nad maksymalną częstotliwością zegara, jaki można zastosować w naszym układzie. Mamy dwie ścieżki o czasach propagacji 1 ns oraz 3 ns. Interesuje nas czas propagacji najdłuższej ścieżki. Musimy do niego dodać także czas setup time przerzutnika (o tym będzie za chwilę). Załóżmy, że setup time to 1 ns, czyli razem blok kombinacyjny z przerzutnikiem potrzebuje 4 ns na przetworzenie sygnału. Odwrotność z 4 ns to 1/4∙109 czyli 250 MHz. To właśnie jest maksymalna częstotliwość sygnału zegarowego, jaką można zastosować w tym układzie. Gdybyśmy zastosowali zegar o częstotliwości większej niż 250 MHz, to wtedy przerzutnik wyjściowy dokonałby skopiowania stanu wcześniej, zanim bramki ustalą stany swoich wyjść. W takiej sytuacji przerzutnik skopiowałby glitch i na wyjściu Out byśmy zobaczyli stan wysoki, co byłoby niepoprawne.
Metastabilność
Wyjście przerzutnika może być w stanie niskim lub wysokim albo może wyłamać się poza zerojedynkową konwencję. Wtedy mamy problem metastabilności. Stan metastabilny polega na tym, że przerzutnik „nie może się zdecydować” czy chce być w stanie niskim czy wysokim. Zobaczmy rysunek 6 – pokazuje on wielokrotne, nałożone na siebie, przebiegi napięcia na wyjściu przerzutnika. Przerzutnik miał zmienić swój stan z 0 na 1, jednak wpada w stan metastabilny. Przez pewien krótki (ale zmienny!) czas, napięcie na jego wyjściu jest zbliżone do połowy napięcia zasilania. Następnie przerzutnik przechodzi do stanu niskiego lub wysokiego. Problem pogarsza to, że stan, w jakim ustali się jego wyjście to kwestia czysto losowa. Nie da się tego w żaden sposób przewidzieć.
Metastabilność powoduje dwa problemy:
- Jeżeli stan wyjścia ustali się nieprawidłowo, to elementy odbierające sygnał z przerzutnika dostaną nieprawidłowe dane i prześlą je dalej, do kolejnych elementów układu;
- Jeżeli stan wyjścia ustali się prawidłowo, to elementy odbierające sygnał z przerzutnika otrzymają go później niż powinny. Może się okazać, że z tego powodu logika kombinacyjna nie zdąży przetworzyć sygnałów przed nadejściem zbocza zegara, a w rezultacie błędne dane zostaną przesłane do kolejnych elementów.
Przerzutnik ma dwa kluczowe parametry czasowe:
- Setup time Ts (czas ustalenia) – jest to okres czasu przed zboczem zegara, w którym sygnał na wejściu nie może się zmieniać;
- Hold time Th (czas utrzymania) – jest to okres czasu po zboczu zegara, w którym sygnał na wejściu nie może się zmieniać.
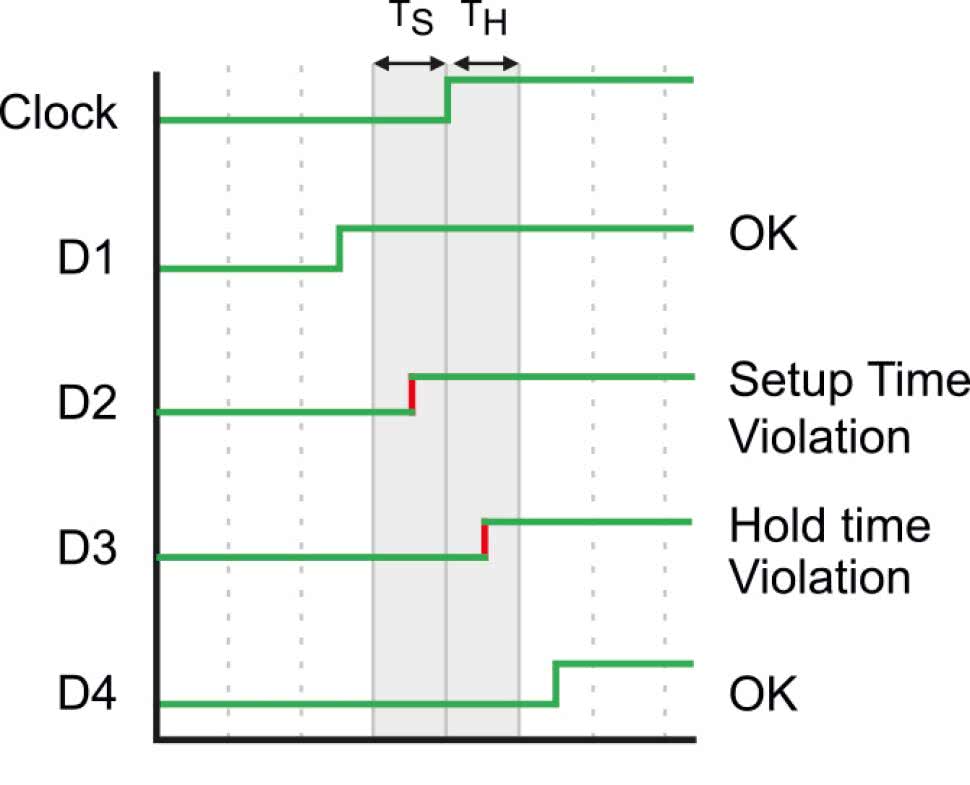
W ramach tych dwóch czasów zabroniona jest jakakolwiek zmiana na wejściu przerzutnika. To znaczy, że stan na wejściu musi się ustalić odpowiednio wcześniej przed zboczem zegara i musi pozostać stabilny jeszcze przez jakiś czas. Jeżeli w czasie setup lub hold nastąpi zmiana sygnału wejściowego to będziemy mieć błąd setup time violation lub hold time violation, a w rezultacie przerzutnik może wpaść w stan metastabilny. Na rysunku 7 pokazano przykłady prawidłowych i nieprawidłowych zmian na wejściu danych przerzutnika.
W poprzednim przykładzie założyliśmy, że przerzutnik działa natychmiast i reaguje na zmiany sygnałów wejściowych w zerowym czasie. Przerzutnik ma także czas propagacji, podobnie jak elementy kombinacyjne. Czas propagacji przerzutnika liczy się od zbocza zegara do ustalenia się stanu na wyjściu przerzutnika i oznacza się TCQ. Możemy pokusić się teraz o podanie wzoru, pozwalającego obliczyć maksymalną częstotliwość sygnału zegarowego:
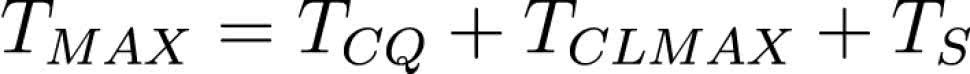
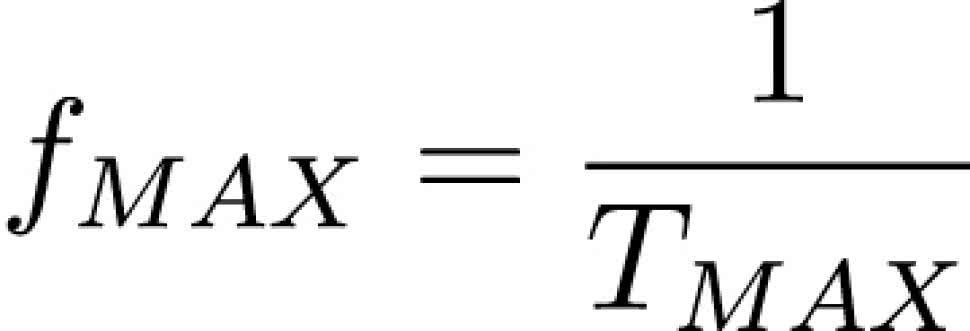
gdzie:
- TMAX – czas przetwarzania danych przez najdłuższą ścieżkę kombinacyjną,
- TCQ – czas propagacji przerzutnika nadającego, liczony od zbocza zegara do ustalenia się danych na wyjściu przerzutnika,
- TCLMAX – czas propagacji najdłuższej ścieżki w logice kombinacyjnej pomiędzy przerzutnikiem nadającym i odbierającym,
- TS – setup time przerzutnika odbierającego,
- fMAX – maksymalna częstotliwość sygnału zegarowego.
Jednak dla bezpieczeństwa należy stosować zegar o częstotliwości trochę mniejszej niż maksymalna.
Dochodzimy ostatecznie do wniosku, że maksymalna częstotliwość zegara zależy od czasu propagacji w najbardziej rozbudowanym bloku logiki kombinacyjnej, czasu propagacji przerzutnika oraz jego setup time. Kiedy częstotliwość zegara jest zbyt duża, dostaniemy błąd setup time violation.
Kiedy zatem może wystąpić hold time violation? Ten problem wydaje się mniej oczywisty. Aby tego błędu nie było, musi zostać spełniony warunek:
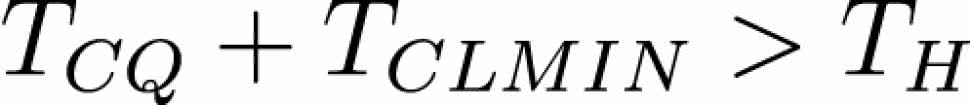
gdzie:
- TCQ – czas propagacji przerzutnika nadającego, liczony od zbocza zegara do ustalenia się danych na wyjściu przerzutnika,
- TCLMIN – czas propagacji najkrótszej ścieżki w logice kombinacyjnej pomiędzy przerzutnikiem nadającym i odbierającym,
- TH – hold time przerzutnika odbierającego.
TCQ oraz TH to parametry przerzutnika i nie mamy na nie żadnego wpływu. Jedynie mamy wpływ na czas propagacji między przerzutnikami. Okazuje się, że nie może on być zbyt długi, bo będzie setup time violation, ale nie może być też zbyt krótki, bo wtedy dostaniemy hold time violation!
W jakiej sytuacji taki błąd może mieć miejsce? Najlepszym przykładem są rejestry przesuwające, czyli łańcuszek przerzutników, gdzie wyjście jednego jest bezpośrednio połączone z wejściem kolejnego. W takiej sytuacji nie ma żadnych bramek między przerzutnikami, więc czas TCLMIN to jedynie czas ładowania pojemności pasożytniczej, która występuje między linią łączącą przerzutniki i masą. Ten czas jest bardzo mały.
Czy zatem w FPGA nie możemy robić rejestrów przesuwających? Możemy! Na szczęście Lattice Diamond w taki sposób tworzy rejestry przesuwające, żeby nie było tego problemu. Problem hold time violation jest bardziej istotny dla projektantów układów scalonych niż dla użytkowników FPGA.
Slack
Kolejnym terminem, jaki musimy poznać jest slack. Jest to zapas czasu, jaki pozostaje przed kolejnym zboczem zegara. Mierzymy go od ustalenia się stanu na wyjściu ostatniej bramki logiki kombinacyjnej, które jest połączone z wejściem przerzutnika odbierającego do wystąpienia zbocza sygnału zegarowego. Slack to czas, w którym nie dzieje się nic. Przerzutnik ma już na swoim wejściu gotowe dane, które się nie zmieniają, więc pozostaje już tylko czekać na zbocze sygnału zegarowego.
Im większy slack, tym lepiej, ale z drugiej strony – jeżeli slack jest bardzo duży to znaczy, że moglibyśmy zastosować szybszy zegar lub kupić wolniejszy układ FPGA (czyli tańszy). Jeżeli slack jest ujemny to znaczy, że zegar jest zbyt szybki. Układ kombinacyjny i/lub przerzutnik nie są w stanie przetworzyć danych przed nadejściem kolejnego zbocza zegara. Jeżeli slack jest zerowy, to jesteśmy na ostrzu noża. Teoretycznie układ powinien działać, ale rozsądnie byłoby mieć jakiś zapas czasu, ponieważ czas propagacji zmienia się w zależności od temperatury i napięcia zasilania.
Skew
Efekt skew polega na tym, że zbocze sygnału zegarowego nie występuje dokładnie w tej samej chwili we wszystkich przerzutnikach. Mogłoby się okazać, że przerzutnik nadający otrzymuje zbocze zegara szybciej niż przerzutnik odbierający lub odwrotnie. Przerzutniki leżące bliżej nadajnika otrzymują sygnał trochę wcześniej niż te, które leżą na drugim końcu struktury krzemowej. Z tego powodu sygnały zegarowe muszą być prowadzone z użyciem globalnych sieci zegarowych. W MachXO2 nazywają się one Primary Clock i mamy do dyspozycji osiem takich sieci. Są to specjalne linie zaprojektowane w taki sposób, aby zminimalizować skew. Syntezator automatycznie rozpoznaje sygnały zegarowe i umieszcza je w Primary Clock Networks.
Dokładnie ten sam problem dotyczy sygnału resetującego. Do prowadzenia sygnałów zerujących służy High Fanout Network i do dyspozycji mamy również osiem takich sieci.
W tym momencie musimy wspomnieć, że jeżeli sygnał zegarowy lub resetujący mają pochodzić spoza FPGA (np. z generatora kwarcowego), to trzeba je doprowadzić do ściśle określonych pinów. Są to piny PCLKxy, gdzie x oznacza bank GPIO, a y to numer wejścia zegarowego. Pinout każdego układu FPGA znajdziesz na stronie [1].
Dobrą praktyką jest, by we wszystkich blokach sekwencyjnych always @(posedge Clock, negedge Reset) stosować ten sam sygnał zegarowy i ten sam sygnał resetujący. Na liście czułości bloku always nie powinno się umieszczać sygnałów, które prowadzone są z użyciem uniwersalnych zasobów logicznych, ponieważ mają one zdecydowanie dłuższy czas propagacji niż sieci globalne, a co gorsza, efekt skew wtedy może być duży.
Jitter
Jitter to fluktuacja częstotliwości sygnału zegarowego. Częstotliwość zegara, jaką zwykle podajemy, to częstotliwość średnia. W rzeczywistości ta częstotliwość nieznacznie się zmienia i czasami jest trochę mniejsza lub trochę większa. Jest to jeden z powodów dlaczego należy zachować pewien margines bezpieczeństwa, pomiędzy maksymalną częstotliwością, podawaną przez Diamond, a nominalną częstotliwością zastosowanego generatora sygnału zegarowego.
Duży jitter mają generatory tylu RC, które są wbudowane w układy scalone – przykładem takiego jest generator OSCH wbudowany wewnątrz MachXO2. Jeżeli zależy nam na stabilnym sygnale zegarowym to dobrym wyborem będzie zastosowanie scalonego generatora kwarcowego.
Synchronizator
Istnieje takie pojęcie jak domena zegarowa. Jest to zbiór przerzutników taktowanych tym samym sygnałem zegarowym. We wszystkich dotychczasowych przykładach (za wyjątkiem odcinka o dzielnikach częstotliwości) korzystaliśmy tylko z jednego zegara. Czyli mieliśmy jedną domenę zegarową.
Domena zegarowa wcale nie musi ograniczać się tylko do wnętrzności układu FPGA. Wyświetlacz multipleksowany i klawiatura matrycowa, które omawialiśmy w poprzednich odcinkach, również działały w tej samej domenie zegarowej, co wszystkie pozostałe komponenty wewnątrz FPGA. Gdyby zaistniała potrzeba przesyłania sygnałów pomiędzy elementami w dwóch różnych domenach zegarowych, trzeba zastosować pomiędzy nimi synchronizator. W przeciwnym wypadku mogłoby dojść do naruszenia setup time i hold time.
Szczególnym przypadkiem są elementy takie jak przyciski, enkodery, sensory czy wejścia sterowane przez inne układy scalone. Są to wejścia, na których sygnały zmieniają się asynchronicznie i trzeba je najpierw zsynchronizować z zegarem. Jednym ze sposobów jest zastosowanie synchronizatora, którego kod pokazano na listingu 1. Możesz go zasymulować w symulatorze EDA Playground pod adresem [2]. Taki synchronizator może zostać zastosowany w celu synchronizowania sygnałów, pochodzących z domen taktowanych zegarem o mniejszej częstotliwości niż docelowa domena. Może być stosowany również do synchronizowania sygnałów, pochodzących z elementów całkowicie asynchronicznych.
// Plik synchronizer.v
module Synchronizer(
input Clock,
input Reset,
input AsyncIn,
output SyncOut
);
reg [1:0] Buffer; // #1
always @(posedge Clock, negedge Reset) begin
if(!Reset)
Buffer <= 0;
else
Buffer[1:0] <= {Buffer[0], AsyncIn}; // #2
end
assign SyncOut = Buffer[1]; // #3
endmodule
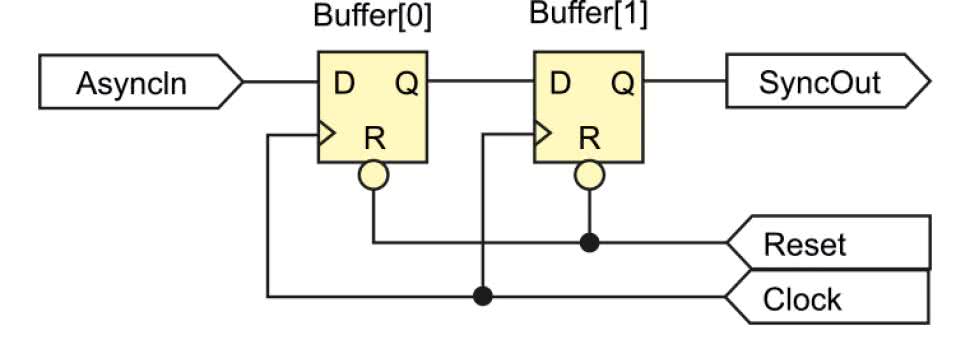
Kluczowym elementem są dwa przerzutniki D, tworzące 2-bitową zmienną Buffer (linia #1). Zmienna ta jest wykorzystywana jako rejestr przesuwający. W linii #2 przesuwamy zerowy bit w miejsce pierwszego bitu, a w miejsce zerowego bitu umieszczany jest stan sygnału wejściowego AsyncIn. Bit pierwszy łączymy z wyjściem SyncOut przy pomocy instrukcji assign (linia #3).
Układ powstały w wyniku syntezy tego kodu pokazano na rysunku 8. Składa się z zaledwie dwóch przerzutników D i nie ma żadnych elementów kombinacyjnych. Wejście przerzutnika Buffer[0] jest podłączone wprost do sygnału, który nie jest zsynchronizowany z zegarem Clock. W związku z tym, na jego wyjściu może wystąpić stan metastabilny. Jednak nie stanowi to problemu, ponieważ jego wyjście jest połączone tylko z kolejnym przerzutnikiem Buffer[1], który jest taktowany tym samym sygnałem zegarowym co przerzutnik zerowy. Nawet jeżeli wystąpi stan metastabilny to nie zostanie przepuszczony dalej, bo odfiltruje go przerzutnik Buffer[1].
Na rysunku 9 pokazano przebiegi powstałe w wyniku symulacji synchronizatora. Na wejściu AsyncIn podawany jest sygnał, który nie jest zsynchronizowany z zegarem. Zbocza tego sygnału wypadają gdzieś w środku taktów zegara. Sygnał SyncOut odpowiada sygnałowi wejściowemu, ale przesuniętemu w taki sposób, by jego zbocza pokrywają się ze zboczami rosnącymi sygnału zegarowego.

Statyczna analiza czasowa
Wystarczy teorii – czas na ćwiczenia praktyczne! Utwórz nowy projekt i jako układ FPGA wybierz MachXO2-1200HC w obudowie TQFP100, a performance grade ustaw na 6. Dokładny part number tego FPGA to LCMXO2-1200HC-6TG100C.
Przeanalizujmy listing 2. Jest to prosty kod, który posłuży nam do zapoznania się z narzędziem do statycznej analizy czasowej. Układ ma 8-bitowe wejście A (linia #1) i 8-bitowe wyjście Y (linia #2). Porty nazwałem pojedynczymi literami, ponieważ omawiany układ nie pełni żadnej sensownej funkcji. W linii #3 tworzymy generator sygnału zegarowego, który już doskonale znamy, ale tym razem ustawiamy najwyższą możliwą częstotliwość, czyli 133 MHz. Następnie tworzymy dwa rejestry 8-bitowe, które będą służyć do synchronizacji wejścia A z domeną zegarową. W linii #6 przepisujemy stan wejścia A do rejestru A_temp, a w linii #7 kopiujemy wartość A_temp do A_sync. Operacje te są zawarte w jednym bloku always. Należy pamiętać, że linie #6 i #7 wykonują się jednocześnie w momencie wystąpienia zbocza rosnącego sygnału zegarowego. Oznacza to, że między zmianą stanu na wejściu A, a pojawianiem się tej zmiany w A_sync, mijają dwa takty zegarowe.
/ Plik top.v
module top(
input Reset,
input [7:0] A, // #1
output [7:0] Y // #2
);
// Generator sygnału zegarowego
wire Clock;
OSCH #(
.NOM_FREQ(“133.00”) // #3
) OSCH_inst(
.STDBY(1’b0),
.OSC(Clock),
.SEDSTDBY()
);
// Synchronizacja wejść
reg [7:0] A_temp; // #4
reg [7:0] A_sync; // #5
always @(posedge Clock, negedge Reset) begin
if(!Reset) begin
A_temp <= 0;
A_sync <= 0;
end else begin
A_temp <= A; // #6
A_sync <= A_temp; // #7
end
end
// Czasochłonna operacja
reg [7:0] Temp; // #8
always @(posedge Clock, negedge Reset) begin
if(!Reset)
Temp <= 0;
else
Temp <= ((((A_sync ^ 8’b10101010) + 8’d123) * 8’d100) * A_sync) + A_sync; // #9
end
assign Y = Temp; // #10
endmodule
Rejestry A_temp i A_sync są syntezowane jako dwie grupy przerzutników D, a w każdej z nich jest 8 przerzutników. Zobacz rysunek 10, który przedstawia schemat powstały po syntezie tego kodu. Pomiędzy A_temp i A_sync może wystąpić stan metastabilny. Jednak nie stanowi to problemu, ponieważ zostanie odfiltrowany przez przerzutniki A_sync i do dalszych elementów układu przechodzą sygnały zsynchronizowane z sygnałem zegarowym.
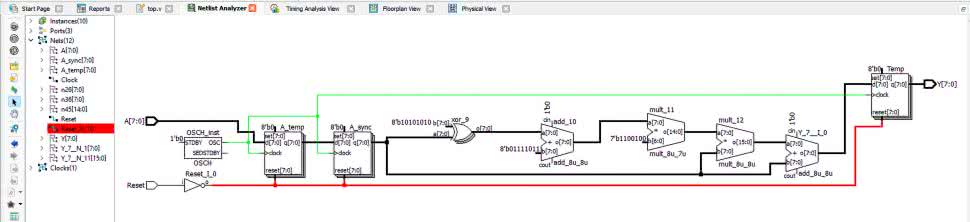
W kolejnym bloku always mamy przykład czasochłonnej operacji. Operacja matematyczna, opisana w linii #9 skutkuje syntezą dużego układu kombinacyjnego. Składa się on z bramek XOR, sumatora dodającego stałą, multiplikatora (mnożarki) mnożącego przez stałą, multiplikatora mnożącej przez zmienną i finalnie sumatora dodającego zmienną. Wszystkie te elementy połączone są szeregowo. Widać je na rysunku 10.
W linii #8 tworzymy 8-bitowy rejestr Temp, który przechowuje wynik operacji, przeprowadzanej w linii #9. Wyjście tego rejestru połączone jest bezpośrednio do wyjścia Y w linii #10 przy pomocy instrukcji assign. Gdybyśmy pominęli ten rejestr i wynik operacji z linii #9 skierowali bezpośrednio do wyjścia, wtedy mogłyby na nim wystąpić różne glitche. Zastosowanie dodatkowego rejestru, synchronizującego wynik bloku kombinacyjnego z zegarem, rozwiązuje ten problem.
Pozostaje nam jeszcze przygotować plik wymagań. W drzewku projektowym klikamy prawym przyciskiem myszy katalog Synthesis Constraint Files, po czym wybieramy Add i New File. Dodajemy plik LDC o dowolnej nazwie. W naszym przykładzie nazwałem go timing.ldc. Po utworzeniu pliku LDC, pokaże się tabela, w której możemy zdefiniować różne wymagania odnośnie zależności czasowych. Wypełniamy pierwszą linię tej tabeli tak, jak pokazano na rysunku 11. Niestety zamiast częstotliwości musimy podać okres zegara, więc na kalkulatorze musimy obliczyć odwrotność z 133∙106. co daje wynik 7,518796 w nanosekundach. Zapisujemy plik i zamykamy go. Przejdź do okienka procesów i zaznacz Place and Route Trace. Następnie kliknij tę pozycję dwukrotnie, aby wykonać wszystkie niezbędne procesy. Nie ma potrzeby generować plików z bitstreamem.
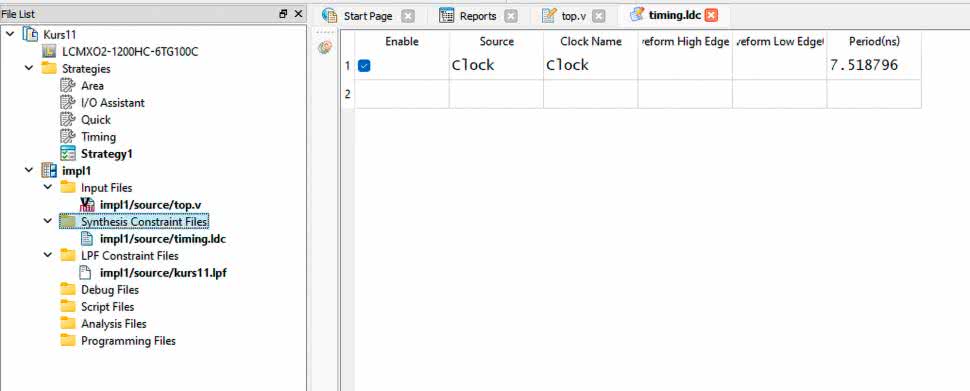
Zwróć uwagę, że tym razem nie przypisujemy wejść i wyjść do fizycznych pinów FPGA w narzędziu Spreadsheet. Nie musimy tego robić. Syntezator sam przypisze piny w taki sposób, aby znaleźć jak najbardziej optymalne rozwiązanie.
Przejdźmy teraz do raportów. Zobacz rysunek 12. Przy raporcie Place & Route pojawił się znak ostrzeżenia. Otwórz raport Place & Route Trace. Czerwonym kolorem zaznaczone są wszystkie wymagania, jakich nie udało się spełnić. W naszym przypadku jest to żądanie, by zegar miał częstotliwość 133 MHz.
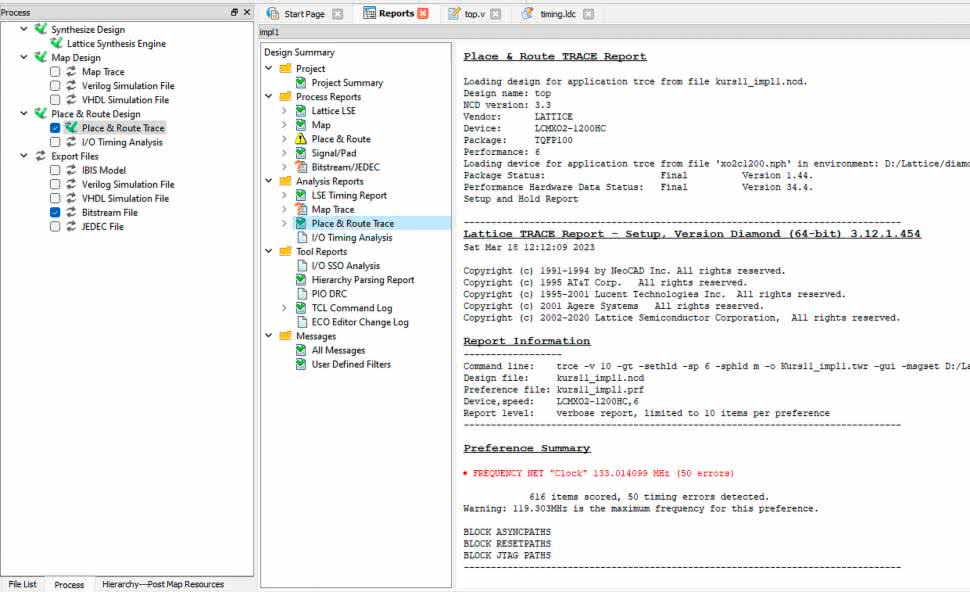
Okazuje się, że w naszym układzie mamy 616 ścieżek kombinacyjnych, ale aż 50 z nich nie jest w stanie spełnić tego wymagania.
W dalszej części raportu mamy wyszczególnione wszystkie ścieżki, które nie spełniły wymogów. Raport jest bardzo rozbudowany i znajdziemy tam informacje nawet o tym, przez które slice’y w strukturze krzemowej biegną poszczególne sygnały. Niestety tak wygenerowany raport przytłacza mnogością szczegółów i jest nieczytelny. Z pomocą przychodzi narzędzie Timing Analysis View, które znajdziesz w menu Tools. Otworzy się okno, które pokazano na rysunku 13.
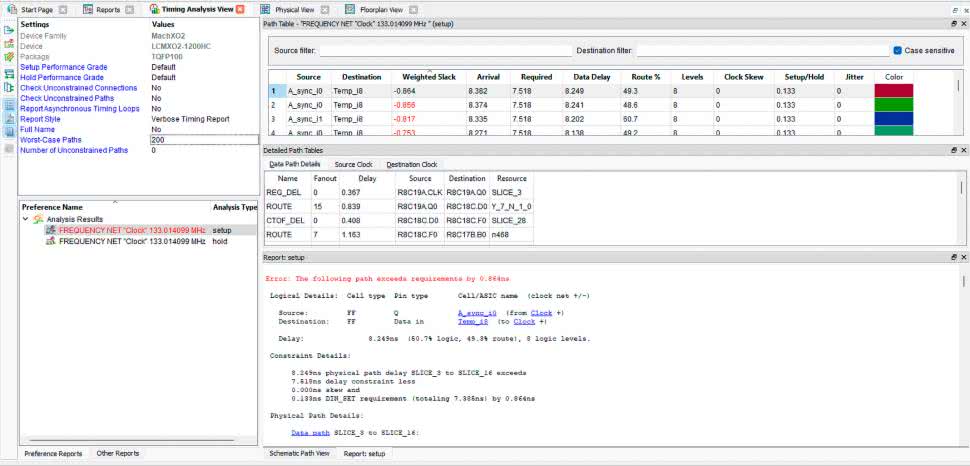
Największa częstotliwość zegara, jaką można zastosować to 119,3 MHz. Wynika to z faktu, że czas propagacji w najwolniejszej ścieżce to 8,328 ns (rysunek 13, kolumna Arrival, pierwszy wiersz). Odwrotność czasu propagacji najwolniejszej ścieżki pozwala obliczyć maksymalną częstotliwość sygnału zegarowego.
W pierwszej kolejności zmodyfikujemy parametr Worst-Case Paths, który domyślnie ustawiony jest na 10. Znajdziesz w lewej górnej części okna. Ten parametr określa liczbę najgorszych ścieżek, które są wyświetlane. Proponuję zmienić go na 200 – wtedy będziemy widzieć wszystkie 50 zbyt wolnych ścieżek, a także 150 ścieżek spełniających wymagania. W lewej dolnej części mamy raporty utworzone dla każdego z wymagań, jakie zostało określone w pliku LDC. Ustawiliśmy tam tylko wymaganie odnośnie częstotliwości sygnału zegarowego, więc program obliczył tylko zależności czasowe dla zegara i sprawdził poprawność setup time i hold time. Raporty zawierające błędy zaznaczone są na czerwono. Kliknij raport FREQUENCY NET „Clock” – setup. W prawej górnej części okna pojawiły się wszystkie przeanalizowane ścieżki w blokach kombinacyjnych. Domyślnie posortowane są według Weighted Slack od najmniejszych do największych. Jeżeli slack jest ujemny, to znaczy, że czas propagacji analizowanej ścieżki jest dłuższy niż okres sygnału zegarowego. Taka sytuacja jest nieprawidłowa i wszystkie ujemne wyniki zaznaczone są kolorem czerwonym.
Interesować nas będą kolumny Source i Destination. Są w nich zawarte nazwy przerzutnika nadającego i odbierającego. Nazwy te pochodzą z naszego kodu w Verilogu, lecz program dokleja do nich różne cyferki, jeżeli są to rejestry wielobitowe. Widzimy, że wszystkie przekroczenia dotyczą sygnałów wychodzących z A_sync i wchodzących do Temp. Nic dziwnego – jest to jedyny blok kombinacyjny w naszym kodzie. Narzędzie Timing Analysis View pozwala nam zlokalizować, gdzie są najdłuższe ścieżki kombinacyjne. To właśnie od nich powinniśmy rozpocząć optymalizację, aby możliwe było spełnienie wymagań czasowych.
Możemy zobaczyć też kilka ciekawych rzeczy. Kliknij prawym przyciskiem myszy na dowolną ścieżkę na liście, a następnie wybierz Show in Physical View. Zostanie pokazana struktura krzemowa z zaznaczonymi różnymi komponentami, jak slice, piny, ścieżki, itp (nie wszystkie są domyślnie włączone – możesz włączać lub wyłączać różne obiekty klikając przyciski w pionowym pasku narzędzi po lewej stronie okna).
Wróć do Timing Analysis View i kliknij tę samą ścieżkę prawym przyciskiem myszy i następnie wybierz Show in Floorplan View. Zobaczymy znów strukturę scaloną, ale narysowaną w sposób bardziej abstrakcyjny i nieco bardziej czytelny. Możemy wyświetlić oba widoki jednocześnie. Kliknij prawym przyciskiem myszy na zakładkę Physical View (na górze) i wybierz Split Tab Group. Okno zostanie podzielone w taki sposób, jak pokazano na rysunku 14.
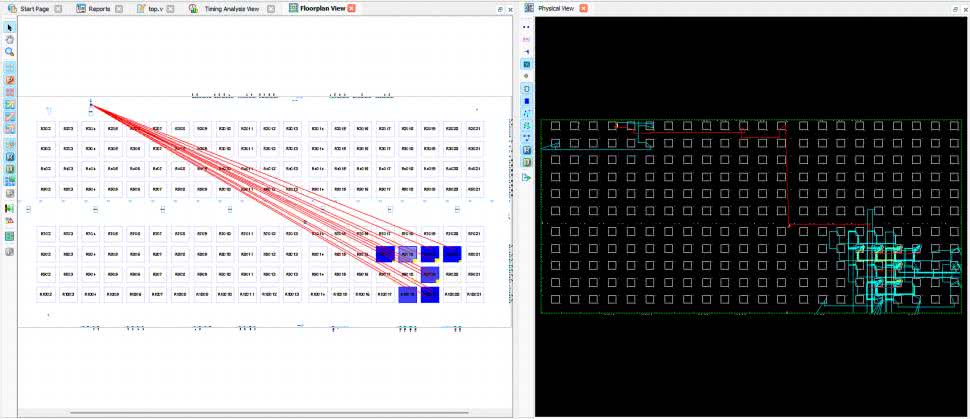
Każdy element, który klikniesz na jednym widoku, będzie automatycznie podświetlony też na drugim. Kliknij na tło w Physical View, a następnie naciśnij CTRL-F. Pokaże się okienko umożliwiające wyszukiwanie różnych obiektów. W polu Find what wpisz „Clock”, a w Find type ustaw „Net” i następnie kliknij Select All. Zostaną podświetlone wszystkie połączenia, które zostały wykorzystane do rozprowadzenia sygnału zegarowego Clock. Wychodzi on z generatora OSCH i jest rozprowadzany do wszystkich przerzutników. Na rysunku 14 sygnał zegarowy został zaznaczony na czerwono. Narzędzia te dają dość duże możliwości analizowania wewnętrznych zasobów na strukturze układu FPGA. Możemy tam znaleźć wszystkie sprzętowe peryferia, takie jak OSCH, PUR, TSALL, bloki pamięci EBR i całą masę innych rzeczy, które dopiero poznamy w przyszłości. Gorąco zachęcam, by pobawić się tymi narzędziami i poprzeglądać sobie wnętrzności układu FPGA. Można zobaczyć, co siedzi wewnątrz każdego używanego elementu. W tym celu należy go kliknąć prawym przyciskiem myszy i wybrać Logic Block View.
Wróćmy jednak do optymalizacji czasowej. Musimy w jakiś sposób rozbić duży blok kombinacyjny, który znajduje się pomiędzy rejestrami A_sync i Temp. Jedną z możliwości jest pipelining.
Pipelining
Jest to metoda polegająca na dzieleniu dużego bloku kombinacyjnego na kilka mniejszych, rozdzielonych przerzutnikami D. Dzięki temu, że bloki kombinacyjne stają się mniejsze, to ich czas propagacji jest krótszy. W rezultacie możemy zwiększyć częstotliwość sygnału zegarowego.
Spróbujmy przekształcić kod z listingu 2, aby jego funkcjonalność pozostała dokładnie taka sama, lecz z podziałem na mniejsze bloki kombinacyjne. Zobacz kod przedstawiony na listingu 3.
// Plik top.v
module top(
input Reset,
input [7:0] A,
output [7:0] Y
);
// Generator sygnału zegarowego
wire Clock;
OSCH #(
.NOM_FREQ(“133.00”)
) OSCH_inst(
.STDBY(1’b0),
.OSC(Clock),
.SEDSTDBY()
);
// Synchronizacja wejść
reg [7:0] A_temp;
reg [7:0] A_sync;
always @(posedge Clock, negedge Reset) begin
if(!Reset) begin
A_temp <= 0;
A_sync <= 0;
end else begin
A_temp <= A;
A_sync <= A_temp;
end
end
// Pipelinig
reg [7:0] Temp1; // #1
reg [7:0] Temp2;
reg [7:0] Temp3;
reg [7:0] Temp4;
reg [7:0] Temp5;
always @(posedge Clock, negedge Reset) begin
if(!Reset) begin
Temp1 <= 0;
Temp2 <= 0;
Temp3 <= 0;
Temp4 <= 0;
Temp5 <= 0;
end else begin
Temp1 <= A_sync ^ 8’b10101010; // #2
Temp2 <= Temp1 + 8’d123;
Temp3 <= Temp2 * 8’d100;
Temp4 <= Temp3 * A_sync;
Temp5 <= Temp4 + A_sync;
end
end
assign Y = Temp5;
endmodule
Operacja z linii #9 listingu 2 składa się z pięciu operacji składowych. Z tego powodu na listingu 3 w linii #1 i kolejnych przygotowujemy pięć rejestrów 8-bitowych. W linii #2 oraz kolejnych mamy wszystkie operacje, jakie dotychczas były wykonywane w jednym bloku kombinacyjnym. Jednak tym razem wynik każdej operacji zapisywany jest do kolejnego rejestru, który staje się argumentem kolejnej operacji.
Uruchom syntezę, a następnie otwórz Netlist Analyzer. Schemat powstały w wyniku syntezy pokazano na rysunku 15. Widzimy, że pomiędzy sumatorami i mnożarkami pojawiły się bloki przerzutników D, taktowane tym samym sygnałem zegarowym i wykorzystujące ten sam sygnał resetujący. Otwórz raport Place & Route Trace. Tym razem zobaczymy komunikat „167.870MHz is the maximum frequency for this preference”. Wymaganie co do częstotliwości zegara równej 133 MHz zostało spełnione.

Zobaczmy co tym razem pokaże narzędzie Timing Analysis View. Na liście 200 ścieżek z najdłuższym czasem propagacji znajdują się głównie dwa rodzaje sygnałów. Są to:
- Biegnące od rejestru Temp3 do Temp4,
- Biegnące od A_sync do Temp4.
Okazuje się, że odpowiedzialna za to jest operacja mnożenia dwóch zmiennych Temp3 i A_sync. Gdybyśmy chcieli zoptymalizować tę operację, można by się pokusić o wykorzystanie gotowych bloków DSP, które przyspieszają operacje matematyczne. Możesz je znaleźć w programie IP Express, które omawialiśmy w 5 odcinku kursu.
Porównajmy zapotrzebowanie na zasoby w przypadku obu implementacji. Wyniki pokazano w tabeli 5. Zwiększyliśmy częstotliwość sygnału zegarowego, jednak ma to swoją cenę. Kod w wersji z pipeliningiem potrzebuje dwukrotnie więcej przerzutników. Jest też inna kwestia, o której nie wolno zapomnieć.
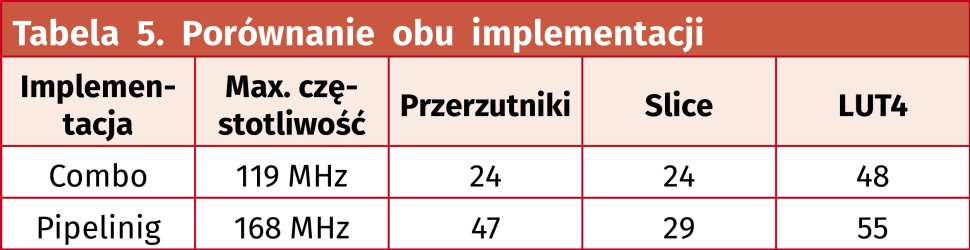
W pierwszej wersji operacja matematyczna wykonywała się w jednym cyklu zegarowym przy maksymalnej częstotliwości 119 MHz. Druga wersja, co prawda może działać z częstotliwością 168 MHz, ale potrzebuje pięciu cykli zegarowych. Jeżeli przeliczymy to na sumaryczny czas operacji, to operacja z pierwszego kodu zajmie 8,4 ns, a z zastosowaniem pipeliningu będziemy musieli poczekać 29,8 ns.
Czy to znaczy, że spowolniliśmy nasz projekt? Wszystko zależy od punktu widzenia, bowiem układ FPGA jest tak szybki, jak jego najwolniejszy blok kombinacyjny. Gdyby najważniejszym założeniem projektowym było jak najszybsze wykonywanie tej operacji matematycznej to kod bez pipeliningu byłby właściwym rozwiązaniem. Jednak mogłoby się zdarzyć, że operacja matematyczna, omawiana w naszych przykładach, jest tylko mało istotną, poboczną operacją, która obniża nam częstotliwość zegara. W efekcie przez nią wszystkie inne układy muszą być taktowane takim zegarem, aby długi blok kombinacyjny dał radę przetworzyć sygnały w jednym takcie zegara. W takiej sytuacji rozbicie dużego bloku kombinacyjnego na kilka mniejszych, ale wykonywanych w kilku taktach zegara, pozwoli przyspieszyć inne, bardziej istotne funkcjonalności.
Można na to spojrzeć jeszcze z innej strony. Pipelining ma świetne zastosowanie wszędzie tam, gdzie dane na wejściu zmieniają się z każdym taktem zegara. Przykładem takiej sytuacji, jest lista instrukcji programu, które są odczytywane z pamięci i przetwarzane przez procesor. Jest to sprawa dość skomplikowana, więc często jest dzielona na kilka prostszych operacji. Pipelining w procesorach polega na tym, że instrukcja jest pobierana z pamięci w czasie, kiedy poprzednia instrukcja jest jeszcze w trakcie wykonywania. Można także dodać kilka etapów pośrednich. Więcej na ten temat możesz przeczytać pod adresem [3].
Reset synchroniczny czy asynchroniczny?
Wróćmy jeszcze do resetowania przerzutników. Sposób, w jaki ustawiamy wartość początkową przerzutników, ma również wpływ na czas propagacji i tym samym na maksymalną częstotliwość sygnału zegarowego.
Weźmy pod lupę listing 4. Jest to przykład banalnego kodu. Blok always reaguje na zbocze rosnące zegara i wtedy do przerzutnika D wpisywany jest wynik, podawany przez bramkę AND. Oprócz tego, blok always reaguje także na zbocze opadające sygnału Reset i wtedy natychmiast ustawia wyjście w stan niski. Przerzutnik pozostaje w stanie niskim i ignoruje sygnał zegarowy tak długo, jak reset jest aktywny.
always @(posedge Clock, negedge Reset) begin
if(!Reset)
Y <= 0;
else
Y <= A & B;
end
W wyniku syntezy otrzymujemy zaledwie dwa elementy – przerzutnik i bramkę AND. Zobacz rysunek 16.
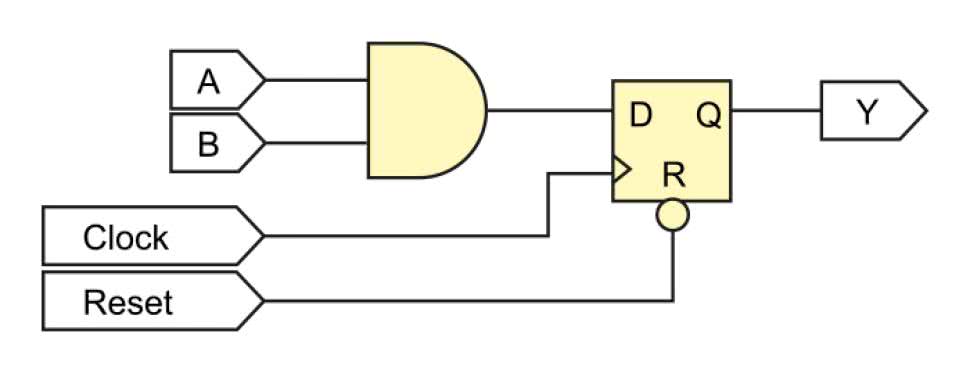
Wyjście bramki AND idzie prosto do wejścia D przerzutnika, a sygnał Reset połączony jest z dedykowanym wejściem zerującym w przerzutniku. Zobaczmy teraz kod z listingu 5. Jedyna różnica polega na tym, że z listy czułości bloku always zniknęło wyrażenie negedge Reset. W takiej sytuacji, przerzutnik wyzeruje się tylko wtedy, kiedy sygnał Reset ma stan niski w momencie wystąpienia zbocza rosnącego sygnały Clock. Pomiędzy zboczami zegara Reset może się zmieniać zupełnie dowolnie i nie będzie to miało wpływu na wyjście układu (oczywiście z zachowaniem hold time i setup time).
always @(posedge Clock) begin
if(!Reset)
Y <= 0;
else
Y <= A & B;
end
Kod wydaje się krótszy i prostszy, ale w rzeczywistości prowadzi do syntezy bardziej złożonego bloku kombinacyjnego! Zobaczmy rysunek 17.
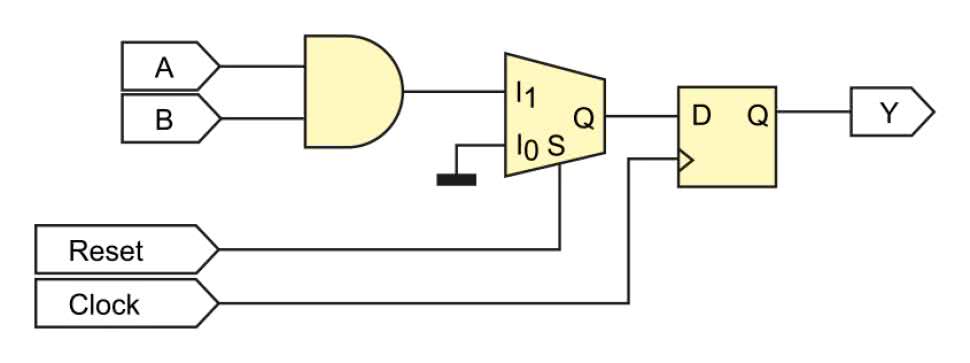
Okazuje się, że pomiędzy bramką AND i przerzutnikiem pojawił się multiplekser! Jest on sterowany sygnałem Reset. Kiedy sygnał resetujący jest w stanie wysokim (czyli podczas normalnej pracy), multiplekser łączy wejście I1 z wyjściem Q. Natomiast kiedy Reset jest w stanie niskim, to multiplekser łączy wejście I0 z wyjściem Q, a z kolei wejście I0 jest na stałe połączone z masą, czyli stanem niskim. W taki sposób stan niski trafia na wejście przerzutnika i jest zapamiętywany w momencie wystąpienia zbocza rosnącego sygnału Clock. Dodatkowy multiplekser ma oczywisty wpływ na czas propagacji. Porównanie osiągów obu rozwiązań pokazano w tabeli 6.

Performance grade w MachXO2
Rodzina układów MachXO2 jest bardzo rozbudowana. Wybierając układ FPGA do naszego projektu, oczywiście musimy kierować się liczbą bloków LUT, jaka nam jest potrzebna, ale także szybkością. Zobacz rysunek 18, gdzie pokazany jest schemat nazewnictwa wszystkich układów z rodziny MachXO2.
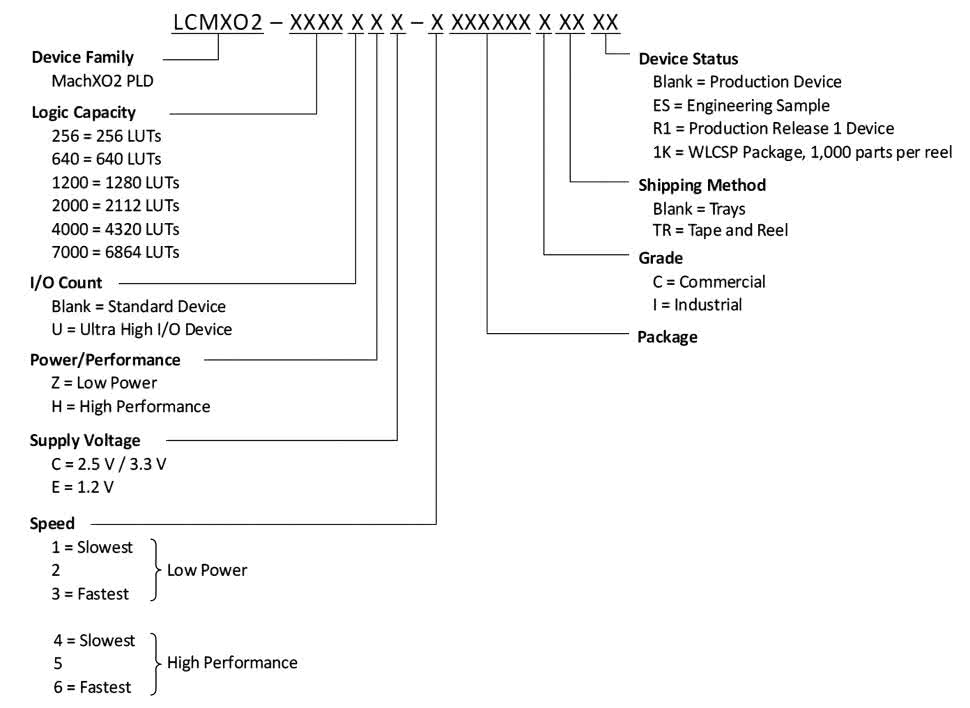
Pierwszy człon nazwy to oznaczenie „LCMXO2”, wspólne dla wszystkich układów rodziny MachXO2. Następnie, po myślniku, podaje się zaokrągloną liczbę elementów LUT, dostępnych w układzie. Dalej mamy dwie literki określające wydajność i zasilanie. Możliwe są trzy kombinacje:
- HC – układy wysokiej wydajności, rdzeń jest zasilany napięciem 3,3 V lub 2,5 V,
- HE – układy wysokiej wydajności, rdzeń jest zasilany napięciem 1,2 V,
- ZE – układy energooszczędne, rdzeń jest zasilany napięciem 1,2 V.
Kolejna cyfra po oznaczeniu wydajności i napięcia zasilania określa szybkość układu. W Lattice Diamond nazywana jest Performance Grade w oknie, gdzie wybiera się układ FPGA stosowany w projekcie. Numer 1 oznacza układy najwolniejsze, a 6 to najszybsze. Dla układów serii ZE dostępne są Performance Grade od 1 do 3. Natomiast dla układów HC i HE możliwe są prędkości od 4 do 6.
Porównanie szybkości poszczególnych FPGA
Firma Lattice podaje w swoich datasheetach maksymalną częstotliwość, obliczoną dla kilku specyficznych aplikacji. W każdym Family Datasheet znajdziemy rozdział o nazwie Typical Building Block Function Performance. W tabeli 7 porównano z jakim zegarem mogą pracować różne układy FPGA firmy Lattice Semiconductor.
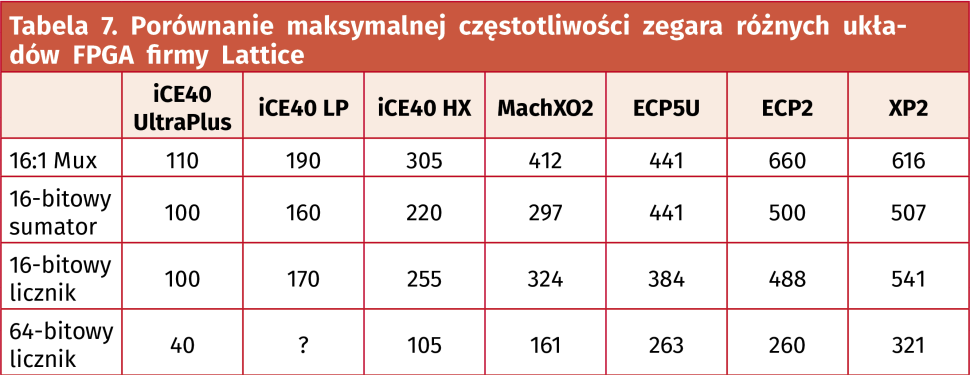
To wszystko na dziś! Pomimo że ten odcinek kursu jest najdłuższy ze wszystkich dotychczasowych, należy go traktować jedynie jako wstęp do tematyki statycznej analizy czasowej. Skupiliśmy się głównie na częstotliwości sygnału zegarowego, ale w pliku wymagań czasowych możemy zdefiniować jeszcze dużo różnych parametrów. Narzędzie do analizy czasowej ma jeszcze mnóstwo opcji, o których nawet nie wspomniałem. W kolejnym odcinku kursu wrócimy do tematu symulacji i poznamy symulator Icarus Verilog.
Dominik Bieczyński
leonow32@gmail.com
Linki:












