 Zaloguj
Zaloguj




Współczesny świat jest przepełniony elektroniką napędzaną systemami wbudowanymi. Rozwiązania tego typu stały się nieodzownym elementem naszego życia i posługujemy się nimi, nawet o tym nie myśląc np. kupując bilet w parkomacie czy wypłacając gotówkę w bankomacie, ale korzystamy z nich także wtedy, gdy przechodzimy przez przejście dla pieszych albo słuchamy wskazówek nawigacji w samochodzie.
Dzięki dużej wydajności układów mamy możliwość implementacji różnego rodzaju skomplikowanych algorytmów wykonujących złożone operacje matematyczne. Jednak postęp technologiczny przyczynia się nie tylko do wzrostu wydajności układów. Sprawia też, że stają się miniaturowe i energooszczędne, co pozwala na ich szersze zastosowania oraz szybki rozwój takich dziedzin jak IoT.
Mechanizm Machine Learning jest elementem sztucznej inteligencji i oznacza algorytmy „uczące się”, czyli takie, które poprawiają własne działanie poprzez doświadczanie. Początki uczenia maszynowego sięgają lat 50...60., czego przykładem może być projekt programu Arthura Samuela do szkolenia zawodników szachowych [1]. Dużym sukcesem był program TD-Gammon autorstwa Gerald Tesauro [2] opracowany w latach 90., ponieważ przyczynił się do przyśpieszenia rozwoju tej dziedziny. Program ten uczył się strategii rozgrywki, grając w ponad milion gier i osiągnął poziom potrafiący konkurować z mistrzami świata w grze Backgammon.
Wraz z rozwojem wcześniej omawianych technologii zaczęło przybywać rozwiązań pozwalających rozwijać projekty związane z uczeniem maszynowym. Powstają nowe chipy specjalizowane dla sztucznej inteligencji. Należą do nich mikrokontrolery z mniejszymi zasobami pamięciowymi i mniejszą ilością pobieranej energii w porównaniu do procesorów graficznych czy FPGA. Ponadto przybywa narzędzi programowych pozwalających w łatwiejszy i zoptymalizowany sposób implementować algorytmy uczenia maszynowego. Popularne frameworki uczenia maszynowego, takie jak: Keras, TensorFlow czy ONNX, mają wsparcie ze strony producenta mikrokontrolerów STM32 (STM32Cube.AI). Przyjrzyjmy się teraz kilku dostępnym i godnym uwagi rozwiązaniom z dziedziny AI.
FPGA dla AI
Aktualnie dostępne na rynku układy FPGA okazują się świetnym rozwiązaniem dla problemów sztucznej inteligencji. Układy FPGA są konfigurowalnymi urządzeniami sprzętowymi – oznacza to, że można dokonywać optymalizacji pod kątem określonych typów architektur, takich jak np. splotowe sieci neuronowe. Pozwalają ograniczyć pobór prądu przy jednoczesnym zwiększeniu wydajności pod względem wydajności obliczeniowej i szybkości transferu danych. Programowalność w połączeniu z możliwością rekonfiguracji daje im przewagę nad procesorami graficznymi przy wdrażaniu algorytmów AI/ML. Rozwiązania uczenia maszynowego wymagają zapewnienia szybkich operacji wejścia/wyjścia, dużych zasobów obliczeniowych i również odpowiednią hierarchię pamięci.

Przykładem skrojonego na miarę potrzeb AI/ML układu FPGA mogą być układy z rodziny Speedster7t firmy Achronix (rysunek 1), które zostały zaprojektowane w celu przyśpieszenia aplikacji uczenia maszynowego. Mają one wysokowydajne układy SerDes (serializery i deserializery), interfejsy pamięci o dużych przepustowościach, specjalizowane procesory uczenia maszynowego oraz bardzo szybkie porty PCIe 5. generacji. To sprawia, że układy powinny poradzić sobie z takimi zadaniami, jak:
- pozyskiwanie dużej ilości danych z szybkich i licznych źródeł wejściowych,
- przechowywanie pobranych danych wraz z modelami DNN (Graph Neural Network – głębokie sieci neuronowe) oraz częściowymi wynikami z obliczeń z każdej warstwy,
- przechowywanie gotowych obliczeń oraz dystrybucje do zasobów na chipie, aby szybko dokonywać obliczania warstwy,
- ostatecznie – prezentacja gotowych wyników.
Zestawienie najważniejszych rozwiązań zastosowanych w układach z rodziny Speedster7t zestawiono w tabeli 1.
Kolejnym układem FPGA, który został zoptymalizowany do wykonywania zadań AI, jest Intel Stratix 10 NX (rysunek 2). Specjalne bloki obliczeniowe zapewniają przyśpieszone rozwiązania obliczeniowe sztucznej inteligencji. Układ zawiera nowy typ zoptymalizowanego bloku AI o nazwie AI Tensor Block, który jest dostosowany do typowych mnożeń macierz-macierz lub wektor-macierz stosowanych w obliczeniach AI, z możliwościami zaprojektowanymi do wydajnej pracy zarówno dla małych, jak i dużych rozmiarów macierzy. Pojedynczy blok tensora AI osiąga wydajność 143 INT8 TOPS lub 286 INT4 TOPS.
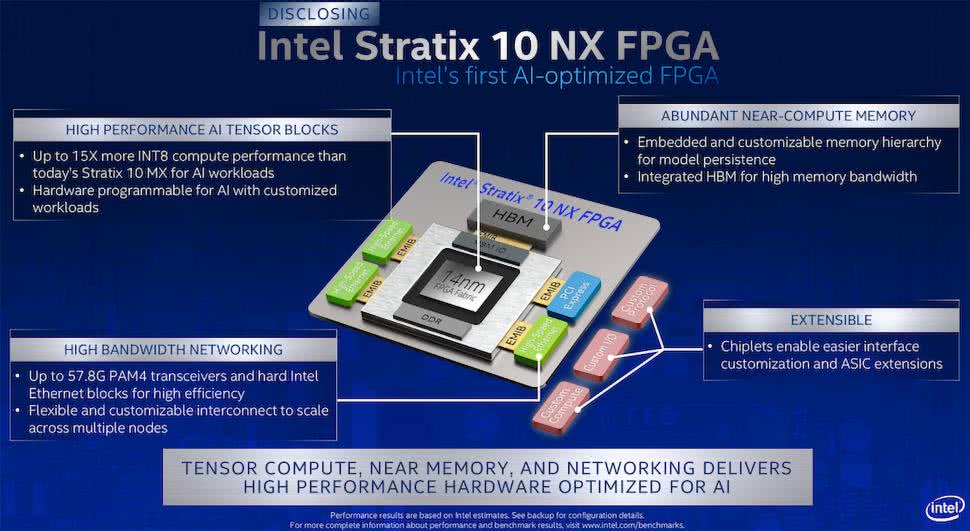
Chip ma transceivery PAM4 działające z przepustowością do 57,8 Gb/s w celu implementacji wielowęzłowych rozwiązań wnioskowania AI, zmniejszając lub eliminując przepustowość jako czynnik ograniczający w projektach wielowęzłowych. Kolejne rozwiązania to m.in. PCIe Gen3 ×16 i 10/25/100G Ethernet MAC/PCS/FEC. Układy wejścia-wyjścia zapewniają skalowalne rozwiązanie łączności i elastyczność w dostosowywaniu się do wymagań rynku. W rankingu PeerSpot na najlepsze FPGA układy te zajmują 4. miejsce i są o jedną pozycję wyżej niż układy Speedster7t, pierwszą pozycję w tym rankingu zajmuje firma Xilinx i jej rozwiązanie programowalnych macierzy bramek.
Numer jeden według PeerSpot to układy układy FPGA serii Xilinx 7. Składają się z one z czterech rodzin FPGA, które spełniają pełen zakres wymagań systemowych, od tanich, niewielkich rozmiarów, wrażliwych na wymagania aplikacji o dużej objętości, aż po zapewniające ultrawysoką przepustowość połączeń oraz pojemność logiczną i możliwości przetwarzania sygnału w najbardziej wymagających aplikacjach wysokiej wydajności (rysunek 3). Choć Xilinx nie ma specjalnie przygotowanej gamy układów FPGA wyspecjalizowanych do zadań uczenia maszynowego i sztucznej inteligencji, to z dużą dozą prawdopodobieństwa damy radę wybrać układ spełniający wymagania naszych aplikacji.

Mikrokontrolery w uczeniu maszynowym
Problematyka uczenia maszynowego przy zastosowaniu układów scalonych, takich jak mikrokontrolery, sprowadza się głównie do wymagań sprzętowych. Złożone algorytmy wymagają dużych mocy obliczeniowych i zazwyczaj przekraczają możliwości przeciętnych mikrokontrolerów, które są zoptymalizowane do wykonywania niezbyt skomplikowanych zadań, ale przy niewielkim zapotrzebowaniu na energię i szybkim czasie reakcji. Projekty uczenia maszynowego bazujące na mikrokontrolerach zmagają się również z problemem ograniczonej pamięci, która jest kluczowym kryterium w AI.
Nie oznacza to jednak, że te energooszczędne układy należy spisać na straty i zapomnieć o wdrażaniu uczenia maszynowego. Mikrokontrolery cechują się stosunkowo niskimi cenami, co, w porównaniu do innych rozwiązań, jest ważnym argumentem przemawiającym za szukaniem rozwiązań. Natomiast małe zużycie energii umożliwia realizację aplikacji zasilanych bateryjnie lub energią pozyskaną z otoczenia, co oznacza ogromną ilość nowych zastosowań. Dlatego powstały narzędzia umożliwiające implementację uproszczonych funkcji i przykładem może być biblioteka STM32Cube.AI, która może konwertować wstępnie wytrenowane algorytmy sztucznej inteligencji (rysunek 4).
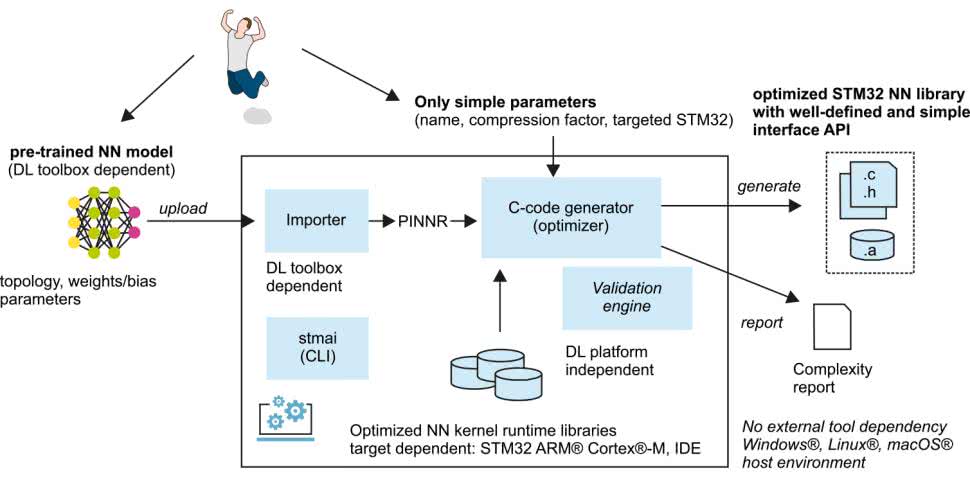
Zastosowanie takiego podejścia wymaga przygotowania modelu za pomocą takich narzędzi jak Keras czy Tensor Flow Lite lub innych mogących generować modele w standardzie ONNX. Tak zaimportowane modele są optymalizowane pod względem użycia pamięci RAM i ROM. Późniejszym etapem jest użycie gotowych bibliotek na wybranym mikrokontrolerze (rysunek 5).
STM32Cube.AI jest częścią ekosystemu STM32Cube i obsługuje modele z głównych platform AI. Dla osób, które mają umiejętności projektowania AI i opracowały wstępnie predefiniowane własne modele ANN (Artificial Neural Networks), STM32Cube.AI zawiera również wiele przykładowych aplikacji. Dostępne są narzędzia do debugowania i zintegrowane biblioteki, aby szybko rozpocząć pracę z projektami AI na układach STM32.
Rozwój techniki sieci neuronowych sprawił, że AI przestało ograniczać się jedynie do superkomputerów. TinyML jest szybko rozwijającą się dziedziną sztucznej inteligencji dotyczącą głównie przetwarzania sieci głębokich bezpośrednio na urządzeniach wbudowanych, o niewielkich zasobach. Przykładowo, Seeeduino Xiao (rysunek 6) spełnia wymagania dotyczące wdrożenia technologi ultra TinyML. Moduł ten charakteryzuje się niewielkimi wymiarami 23,5×17,5 mm i wyposażony został w mikrokontroler SAMD21 ARM Cortex M0+ 32-bit 48 MHz z 256 kB flash oraz 32 kB SRAM. Takie zestawienie w zupełności wystarcza do zrealizowania projektów związanych ze sztuczną inteligencją bazującą na TinyML.
SoC z Linux w sztucznej inteligencji
Układy typu SoC (System on Chip) w połączeniu z systemem operacyjnym Linux dostarczają wielu możliwości związanych z uczeniem maszynowym. Układy SoC zawierają różne urządzenia peryferyjne i komponenty obliczeniowe w układzie scalonym, które mogą zapewnić dużą wydajność obliczeniową związaną z przetwarzaniem danych. W niektórych przypadkach uważane są za doskonałe rozwiązanie do wdrażania aplikacji ML w systemach wbudowanych. Powodem tego są zaawansowane możliwości, jakie oferują tego typu układy oraz fakt, że coraz częściej są wyposażane w specjalne jednostki wyspecjalizowane do wykonywania zadań uczenia maszynowego. Ponadto bardzo często pracują pod obsługą systemu Linux, który ma liczną bazę bibliotek wspomagających AI/ML. Linux również umożliwia uruchamianie skryptów napisanych w języku Python, który jest niewątpliwym liderem wśród narzędzi do analizy danych, jak również problemów natury sztucznej inteligencji i uczenia się maszyn.
Wiele amatorskich projektów oraz prototypów aplikacji profesjonalnych realizuje się na popularnej płytce Raspberry Pi z systemem Linux. Dzięki dobrej dostępności do oprogramowania dla systemu Linux można relatywnie szybko projektować urządzenia służące np. do inteligentnego przetwarzania obrazów, korzystając z biblioteki OpenCV. Firma XILIX wyszła naprzeciw potrzebom takich rozwiązań i opracowała architekturę Zynq.
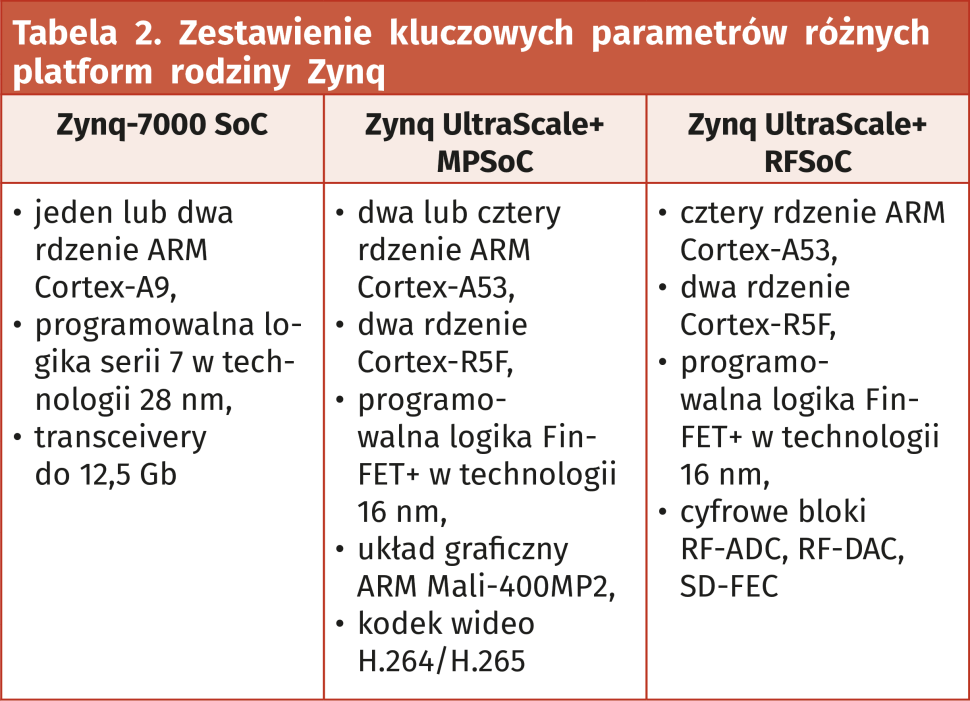
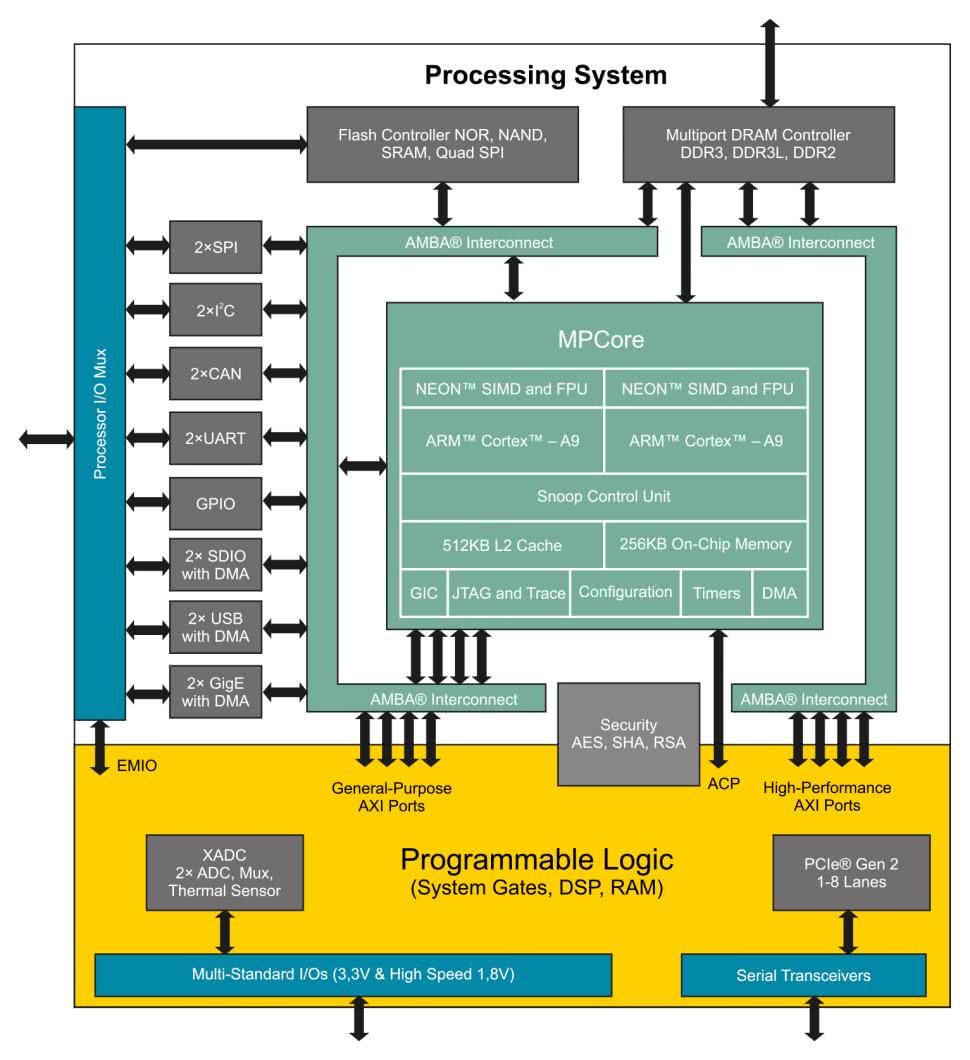
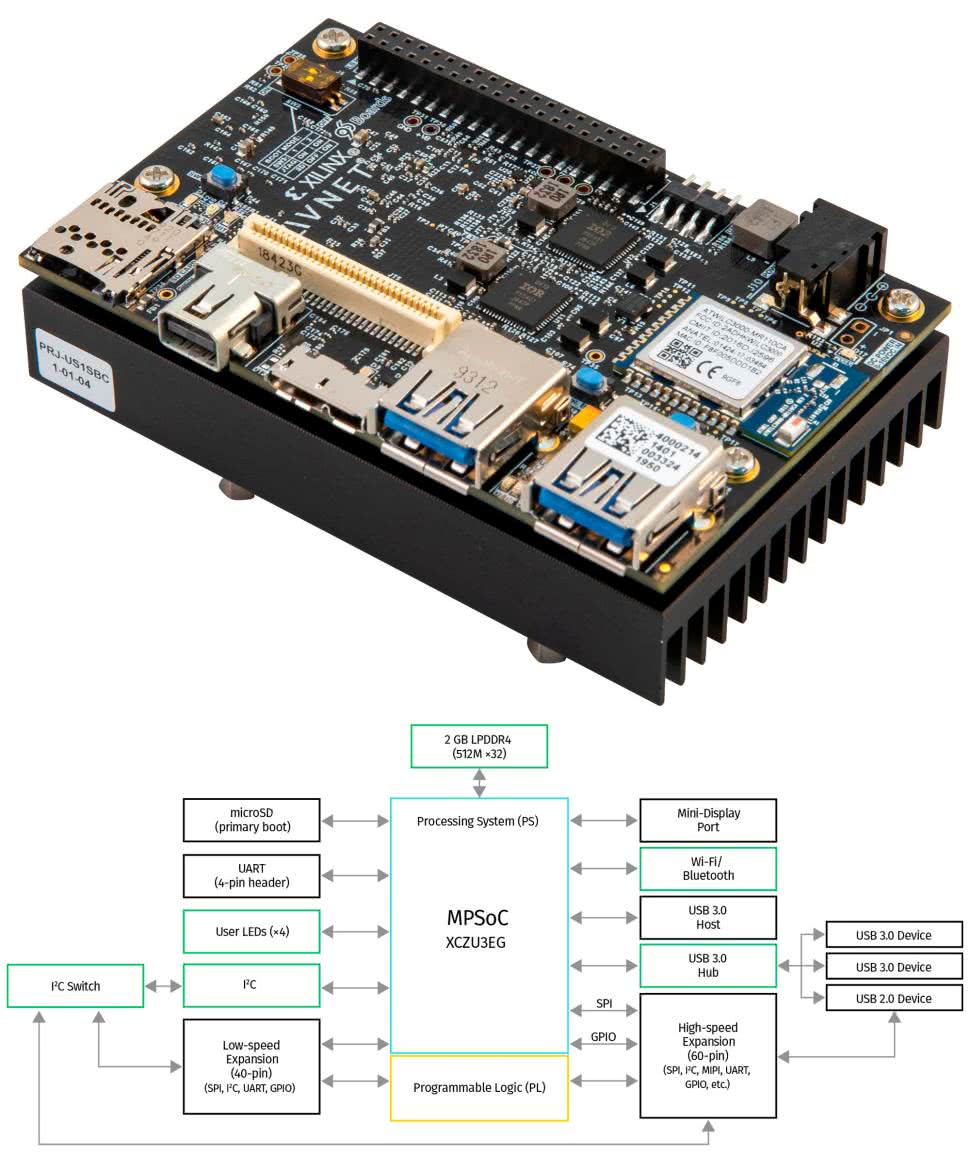
Zynq jest w pełni programowalnym SoC, który łączy FPGA z tradycyjnym procesorem ARM Cortex (rysunek 6). Połączenie o wysokiej przepustowości oraz małych opóźnieniach między różnymi elementami architektury Zynq zapewnia interfejs bazujący na standardzie Advanced eXtensible Interface. Proces projektowania architektury Zynq ma kilka wspólnych kroków z układem FPGA. Najważniejszym etapem jest określenie specyfikacji i wymagań systemu, gdzie poszczególne zadania są przydzielane do realizacji w logice programowalnej (PL) lub w systemie przetwarzania (PS). Ten etap jest ważny, ponieważ wydajność całego systemu będzie zależała od zadań, które zostaną przydzielone do realizacji w najbardziej odpowiedniej technologii: sprzętowej lub programowej. Firma Xilinx przygotowała specjalne układy dla potrzeb Machine Learning zawierające architekturę Zynq – dostępne platformy to: Zynq-7000 SoC, Zynq UltraScale+ MPSoC, Zynq UltraScale+ RFSoC (tabela 2). Do szybkiego rozpoczęcia prac z architekturą Zynq UltraScale+ warto użyć gotowej płytki uruchomieniowej Ultra96-V2 od AVNET (rysunek 7).
Dodatkowym atutem przy stosowaniu technologii firmy Xilinx jest opracowane przez firmę i udostępnione specjalne SDK (Software Development Toolkit) przeznaczone do implementacji sztucznej inteligencji w projektach bazujących na wspomnianych układach – Xilinx AI SDK.
Xilinx AI SDK
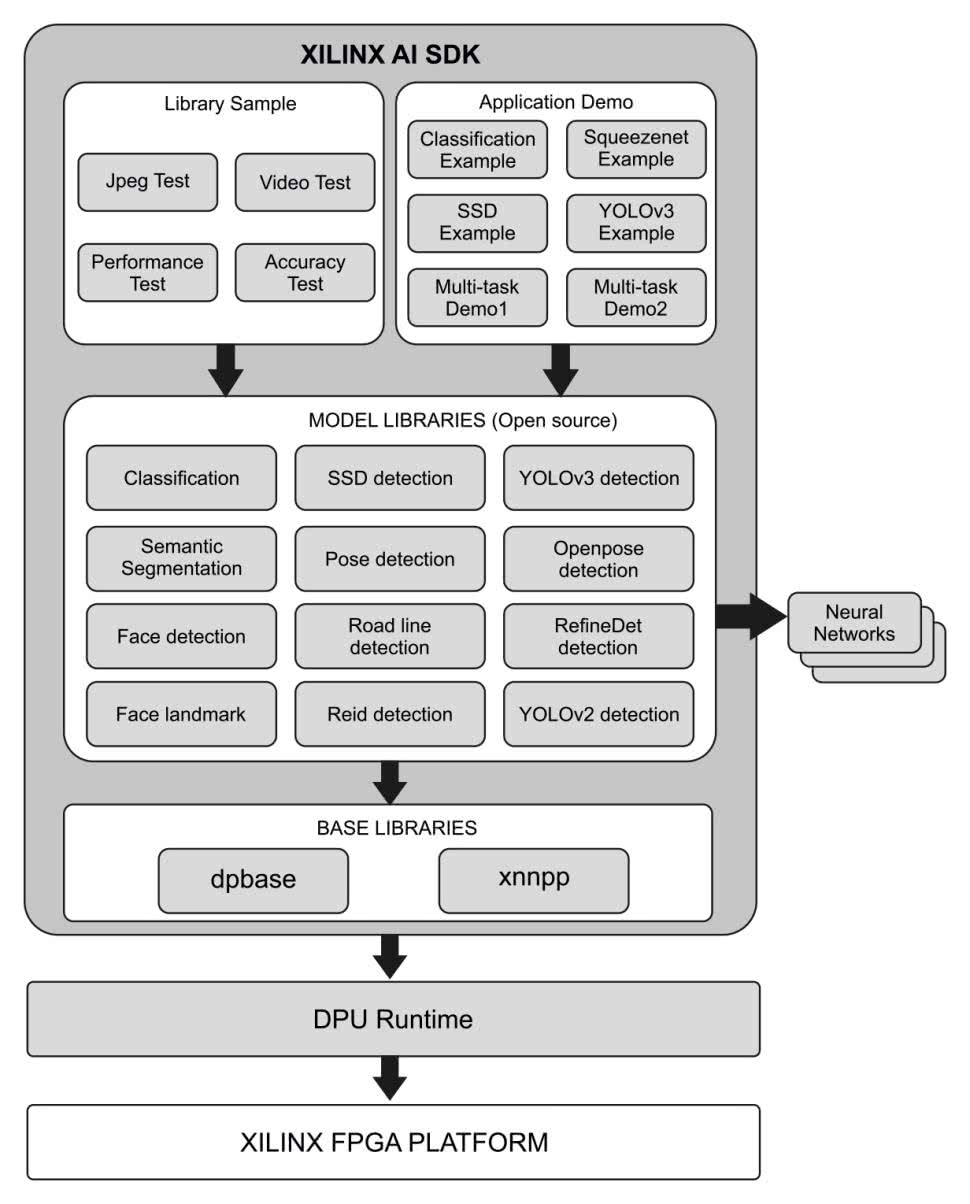
Pakiet oprogramowania Xilinx AI SDK jest zestawem bibliotek oraz interfejsów API (rysunek 8). Został opracowanych w celach wydajnego i zoptymalizowanego wykorzystania zasobów nawet w przypadku osób słabo znających zagadnienia z zakresu uczenia maszynowego czy układów FPGA. Zestaw narzędzi pozwala programistom skupić się na rozwoju ich aplikacji, nie wymagając często trudnych dla nich zadań polegających na konfiguracji logiki programowalnej. Zawiera liczną bazę bibliotek, m.in. przykładowe biblioteki analizy plików Jpeg, wideo oraz aplikacje demonstracyjne możliwe do uruchomienia w celach testowych. Biblioteki modeli zawierają wiele implementacji modeli sztucznej inteligencji, model detekcji twarzy, wykrywanie linii na jezdni i wiele innych (rysunek 8).
Dzięki zastosowaniu odpowiednich narzędzi możemy zrezygnować z pojedynczej implementacji własnego modelu uczenia maszynowego i optymalizacji związanej ze sprzętem. Przykład detekcji twarzy pochodzący z dokumentacji wprowadzającej do omawianego SDK zawiera raptem 25 linii kodu C++ (listing 1). Do uruchomienia przykładu należy uprzednio pobrać i zainstalować SDK w systemie Linux na urządzeniu pracującym na układach firmy XILINX. Do wykonania tych czynności można posłużyć się dokumentacją dostępną na stronie producenta układów, dostarczającego wspomniane narzędzia.
#include <xilinx/yolov3/yolov3.hpp>
#include <iostream>
#include <map>
#include <string>
#include <opencv2/opencv.hpp>
main ( int argc, char **argv ) {
Mat img = cv::imread(argv[1]);
auto yolo = xilinx::yolov3::YOLOv3::create_ex("yolov3_voc_416", true);
auto results = yolo->run(img);
for(auto &box : results.bboxes){
int label = box.label;
float xmin = box.x * img.cols + 1;
float ymin = box.y * img.rows + 1;
float xmax = xmin + box.width * img.cols;
float ymax = ymin + box.height * img.rows;
if(xmin < 0.) xmin = 1.;
if(ymin < 0.) ymin = 1.;
if(xmax > img.cols) xmax = img.cols;
if(ymax > img.rows) ymax = img.rows;
float confidence = box.score;
cout << "RESULT: " << label << "/t" << xmin << "/t" << ymin << "/t"
<< xmax << "/t" << ymax << "/t" << confidence << "/n";
rectangle(img, Point(xmin, ymin), Point(xmax, ymax), Scalar(0, 255, 0),1, 1, 0);
}
}
TinyML oraz TensorFlow Lite
TinyML to dziedzina sztucznej inteligencji zajmująca się głównie przetwarzaniem sieci głębokich bezpośrednio na urządzeniach wbudowanych. Oznacza to, że operacje i algorytmy uczenia maszynowego realizowane są wewnątrz tych urządzeń. Główną ideą małego uczenia maszynowego jest przeprowadzanie analizy danych na urządzeniu zasilanym bateryjnie i pobieranie przy tym energii rzędu pojedynczych mW. Dzięki rozwojowi TinyML okazuje się, że małe urządzenia stosujące uczenie maszynowe znajdują różnorodne zastosowania i okazują się wystarczająco dobre w nowych rozwiązaniach.
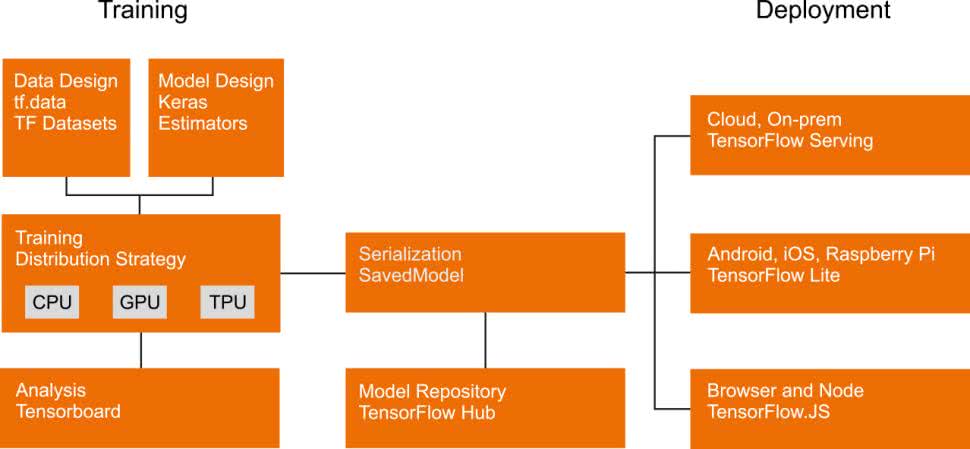
Google opracowało zestaw narzędzi o nazwie TensorFlow (rysunek 9), które umożliwiają realizację uczenia maszynowego, pomagając programistom uruchamiać ich modele m.in. na urządzeniach mobilnych, wbudowanych i brzegowych. Element TensorFlow Lite jest zoptymalizowany pod kątem opóźnień, prywatności, rozmiaru oraz poboru mocy. Umożliwia realizację algorytmów AI na różnych platformach, m.in. na układach SoC, mikrokontrolerach oraz urządzeniach z systemami iOS i Android. Dodatkowo pozwala na obsługę wielu języków programowania, takich jak C++, Python, Objective-C, Swift oraz Java. Dzięki optymalizacji modelu oraz akceleracji sprzętowej zyskujemy wysoką wydajność opracowanego rozwiązania. Dokumentacja dostarcza kompleksowe przykłady implementacji dla typowych zadań uczenia maszynowego, które można adaptować do własnych projektów.
Dzięki ścisłej integracji Keras z TensorFloworaz szybkiemu wykonywaniu funkcji w języku Python, TensorFlow 2.0 sprawia, że doświadczenie tworzenia aplikacji jest jak najbardziej znajome dla programistów Pythona.
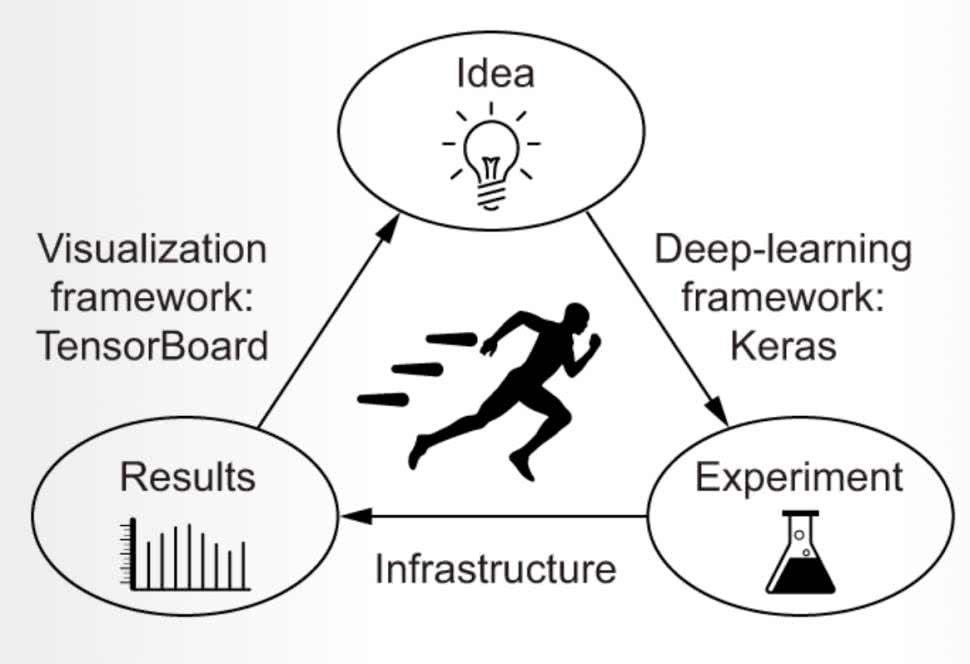
Narzędzie Keras jest wysokopoziomowym API głębokiego uczenia napisanym w Pythonie działającym na platformie TensorFlow. Keras kładzie główny nacisk na możliwość szybkiego eksperymentowania, pozwala to na szybkie przejście z pomysłu do realizacji (rysunek 10). API zapewnia przede wszystkim niezbędne abstrakcje i bloki konstrukcyjne do opracowywania i dostarczania rozwiązań uczenia maszynowego z dużą szybkością iteracji. Keras i TensorFlow są łączone ze sobą, przykładowo API STM32Cube.AI obsługuje wspomniane frameworki, które można implementować w projektach bazujacych na produktach firmy STM32.
Podsumowanie
Edge AI – tak określamy stosowanie uczenia maszynowego i sztucznej inteligencji w urządzeniach wbudowanych. Aktualnie pojawia się coraz więcej narzędzi wspierających prace projektantów i programistów takich systemów oraz już dostępne narzędzia stale się rozwijają. Producenci sprzętu również poprawiają swoje układy uwzględniając rosnące potrzeby wdrażania sztucznej inteligencji. Świadczy to głównie o tym, że istnieje potrzeba i uzasadnienie stosowania technologii uczących w małych i energooszczędnych układach różnego przeznaczenia. Szereg zalet, o jakich wspomniano, to głównie możliwość wprowadzenia oszczędności i zastosowania technologii w miejscach niedostępnych lub trudnych i drogich do wdrożenia rozwiązań sprzętowych, takich jak np. procesory graficzne. Wybór odpowiedniego rodzaju sprzętu uzależniony będzie głównie od potrzeb konkretnego systemu, jego zastosowania oraz końcowego wdrożenia. Obecnie urządzenia takie, jak chociażby AGD, dzięki AI mogą zyskać nowe możliwości, przez co stają się bardziej atrakcyjne dla konsumenta.
Edge AI, oprócz tego, że umożliwia zasilanie bateryjne, ma dodatkowo jedną ważną zaletę: urządzenia mogą wykonywać operacje z dziedziny AI/ML w środowisku izolowanym od dostępu do Internetu. W niektórych aplikacjach może to być cecha decydująca o wybraniu właśnie tej technologii.
Lucjan Bryndza, EP
lucjan.bryndza@boff.pl
[1] https://en.wikipedia.org/wiki/Arthur_Samuel
[2] https://en.wikipedia.org/wiki/TD-Gammon












