 Zaloguj
Zaloguj




Naturalnie samodzielne wykonanie dobrego sejfu nie jest takie łatwe, ale wynika to przede wszystkim z trudności precyzyjnego dopracowania mechaniki. Porządny sejf musi mieć mocny zamek, grube ścianki i brak luk, które umożliwiłyby jego niepowołane otwarcie lub uniemożliwiłyby skorzystanie przez odpowiednie osoby.
Działanie sejfu

Fotografia 1. Moduł Raspberry Pi camera, podłączony do Raspberry Pi
Prezentowany projekt został wykonany przez Tony DiColę i składa się z pudełka i komputera wraz z modułem kamery, a także elementu wykonawczego - np. serwomechanizmu, który rygluje zamek pokrywy pudełka. W pudełku umieszczony jest też pakiet baterii, które służą do zasilania napędu zamka, podczas gdy z założenia, sam komputer zasilany jest z zewnętrznego zasilacza.
Oznacza to, że do otwarcia pudełka konieczne jest podłączenie go do prądu, co jest trochę bez sensu w przypadku urządzeń przenośnych, ale modyfikacja projektu tak, by zawierał dodatkowe, przenośne, ładowalne źródło napięcia dla komputera nie jest trudna. Poza tym taką samą konstrukcję pod względem elektroniki i oprogramowania, można by było umieścić w futrynie drzwi, pomijając problem zasilania.
Działanie sejfu jest bardzo proste. Użytkownik chcąc otworzyć pudełko, bierze je w ręce i ustawia tak, by obiektyw skierowany był w stronę twarzy człowieka, a następnie naciska wbudowany przycisk. Komputer robi zdjęcie człowieka z użyciem kamery i zaczyna je analizować.
Jeśli na zdjęciu znaleziona zostanie twarz i będzie ona wystarczająco podobna do twarzy wzorcowej, uruchomiony zostanie serwonapęd, by odryglować zamek. W przeciwnym przypadku zamek pozostanie na swojej pozycji i będzie można spróbować wykonać ponowne zdjęcie. Jeśli zamek będzie otwarty, naciśnięcie przycisku spowoduje zaryglowanie.
Trzeba przy tym zaznaczyć, że projekt został przygotowany tak, by działał dla jednej twarzy, której zdjęcia przygotowano i poddano do treningu dla algorytmu rozpoznawania twarzy.
Potrzebne komponenty:
|
Potrzebne elementy i narzędzia

Fotografia 2. Serwonapęd Tower Pro SG92R
Do realizacji omawianego projektu nie potrzeba dużej ilości sprzętu. Wystarczy odpowiednio duże pudełko, najlepiej z materiału nieprzewodzącego prądu i takiego, w którym można nawiercić otwory. W nim umieszczamy komputer Raspberry Pi w dowolnej wersji, ale z modułem Raspberry Pi Camera (fotografia 1) o wartości około 30 dolarów.
W projekcie autor zastosował miniaturowy serwonapęd Tower Pro SG92R (fotografia 2), kosztujący 6 dolarów, którego moment siły to 0,16 Nm, a wymiary to 23×11×29 mm. Alternatywnie można użyć solenoidu do zamka (fotografia 3), który - jeśli konstrukcja pudełka jest odpowiednia - może być nawet wygodniejszy w zastosowaniu.
Potrzebny będzie też monostabilny przycisk, 10-kiloomowy rezystor podciągający dla przycisku, 5-woltowy zasilacz USB oraz pakiet 4 baterii 1,5-woltowych, najlepiej w formacie AA, którym zasilany będzie serwonapęd. Oczywiście potrzebny będzie klej i różne elementy montażowe oraz sam rygiel, który można będzie przyczepić do serwonapędu, a także przewody do podłączenia wszystkich elementów. Przydatna może okazać się też uniwersalna płytka, która ułatwi wykonywanie połączeń.
Montaż
W pudełku nawiercamy otwory: na kamerę, przycisk i na podłączenie zasilania do komputera. Może się okazać konieczne wykonanie kolejnych otworów, by przy przyczepić pozostałe elementy we wnętrzu pudełka. Warto tak rozmieścić elementy, by moduł z kamerą znajdował się blisko samego komputera.
Zasilanie serwonapędu podłączamy do pakietu baterii, aby nie przeciążać linii zasilania komputera. Linię sterującą serwonapędu podłączamy do pinu GPIO 18. Przycisk do GPIO 25 z użyciem rezystora podciągającego napięcie do 3,3 V, podawanego na jednym z wyprowadzeń Raspberry Pi.
Potrzebne oprogramowanie

Fotografia 3. Zamek z solenoidem
Sprawa oprogramowania jest w tym przypadku dosyć skomplikowana. Wynika to z faktu, że do rozpoznawania obrazów stosujemy bibliotekę OpenCV, ale moduł odpowiedzialny za rozpoznawanie twarzy dostępny jest dopiero od wersji 2.4, podczas gdy w repozytoriach Raspbiana znajduje się OpenCV tylko w wersji 2.3.
Oznacza to, że konieczne będzie samodzielne skompilowanie źródeł na wybraną platformę. Oprócz tego użyjemy Pythona i jego pakietów. W tym celu instalujemy menedżer pakietów Pythona PIP, korzystając z polecenia APT:
sudo apt-get install python-pip
Instalujemy też pakiet python-dev oraz dwa moduły pythona: picamera, odpowiedzialny za obsługę kamery i rpio, który pozwala na sterowanie wyprowadzeniami GPIO z obsługą serwonapędów przez PWM:
sudo apt-get install python-dev
sudo pip install picamera
sudo pip install rpio
Przejdźmy teraz do kompilacji bibliotek OpenCV. Aktualna najnowsza stabilna wersja bibliotek OpenCV dla Linuksa to 3.0.0 (http://goo.gl/4nbi68). Jednakże wystarczy użycie dowolnej wersji 2.4.x (http://goo.gl/EdOsrv). Pobieramy wybraną z nich poleceniem wget, a następnie rozpakowujemy pobrany plik komendą unzip. W celu kompilacji biblioteki OpenCV ze źródeł konieczne jest też zdobycie odpowiednich narzędzi, najlepiej poleceniami:
sudo apt-get update
sudo apt-get install build-essential cmake pkg-config python-dev libgtk2.0-dev libgtk2.0 zlib1g-dev libpng-dev libjpeg-dev libtiff-dev libjasper-dev libavcodec-dev swig unzip
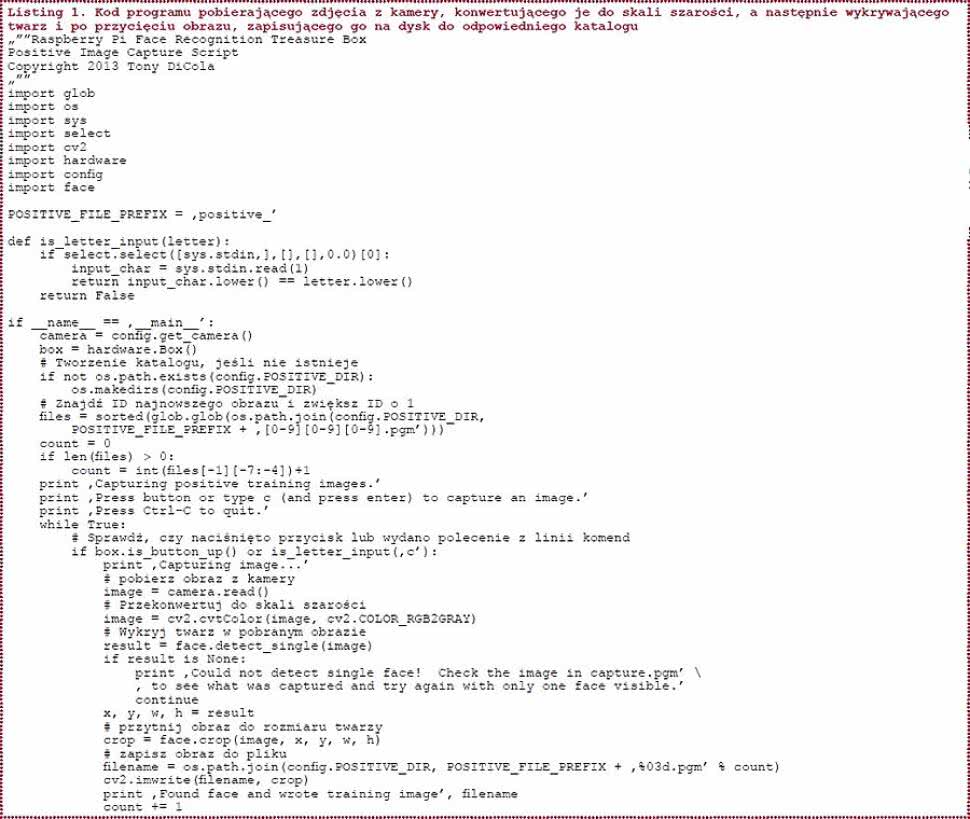
Listing 1. Kod programu pobierającego zdjęcia z kamery, konwertującego je do skali szarości, a następnie wykrywającego twarz i po przycięciu obrazu, zapisującego go na dysk do odpowiedniego katalogu
W celu przygotowania pliku make, który będzie potrzebny do kompilacji, wchodzimy do katalogu z wypakowanym OpenCV i korzystamy z polecenia cmake, stosując pewne dodatkowe parametry, które wyłączą testowanie wydajności. Pozostawienie włączonego testowania wydajności sprawiłoby, że czas kompilacji mógłby być zbyt długi, albo operacja w ogóle by się nie udała, ze względu na ograniczony rozmiar dostępnej pamięci. Dlatego polecenie cmake należy wywołać w następujący sposób:
cmake -DCMAKE_BUILD_TYPE=RELEASE -DCMAKE_INSTALL_PREFIX=/usr/local -DBUILD_PERF_TESTS=OFF -DBUILD_opencv_gpu=OFF -DBUILD_opencv_ocl=OFF
Gdy plik make będzie przygotowany, należy go uruchomić (czas jego pracy wyniesie około 5 godzin), po czym by zainstalować skompilowane OpenCV w systemie, konieczne jest użycie polecenia:
sudo make install.
Szkolenie algorytmu

Listing 2. Program trenujący algorytm rozpoznawania twarzy, w oparciu o zbiór fotografii twarzy, która ma odblokowywać zamek i o zbiór różnych innych zdjęć twarzy
Bardzo ważnym elementem projektu jest trenowanie systemu rozpoznawania twarzy tak, by był w stanie odróżnić pożądanego użytkownika od innych osób. Szkolenie odbywa się poprzez przedstawienie do analizy zarówno przykładów twarzy, które nie mają otwierać sejfu, jak i przykładów jednej twarzy upoważnionego EPużytkownika.
Te pierwsze nazywamy negatywnymi, a drugie - pozytywnymi i umieszczamy je w podkatalogach training/negative i training/positive (odpowiednio). Auto projektu pobrał zdjęcia twarzy obcych ludzi z udostępnionej bezpłatnie bazy twarzy, opracowanej w latach 90. przez AT&T Laboratories Cambridge.
Baza ta dostępna jest pod adresem: http://goo.gl/s4vfUq i może się przydać do innych projektów. Bazę fotografii pozytywnych można stworzyć ładując wcześniej przygotowane zdjęcia lub wykorzystać do tego przygotowane pudełko z kamerą i skrypt capture-positives.py (listing 1). Warto w tym kodzie zwrócić uwagę na użycie funkcji:
- camera.read() - pobierającej obraz z kamery,
- cv2.cvtColor() - konwertującej obraz do zadanej palety barw (w tym przypadku odcieni szarości),
- face.detect_single() - wykrywającej twarz na zadanym obrazie,
- face.crop() - przycinającej obraz do wymiarów twarzy,
- cv2.imwrite() - zapisującej obraz do pliku.
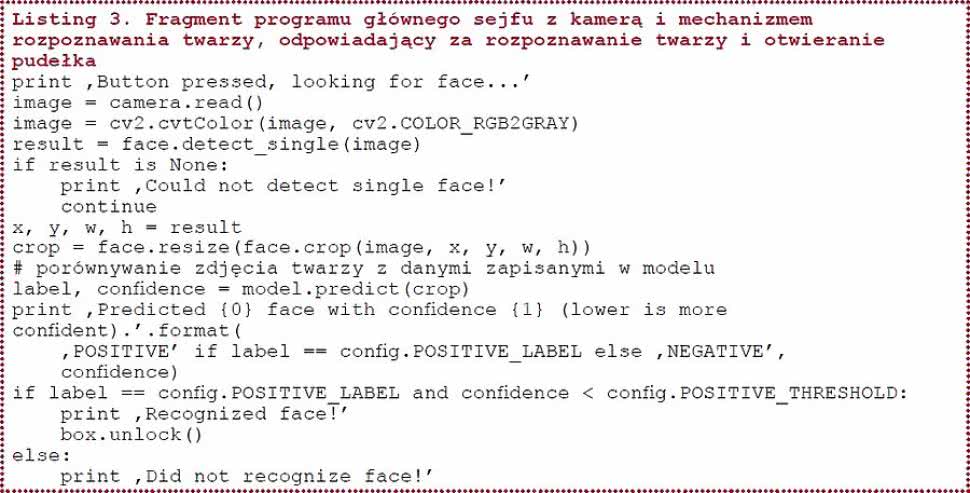
Listing 3. Fragment programu głównego sejfu z kamerą i mechanizmem rozpoznawania twarzy, odpowiadający za rozpoznawanie twarzy i otwieranie pudełka
Część z nich została napisana przez autora na potrzeby projektu, ale jest bardzo uniwersalna i można je z powodzeniem wykorzystać także w innych miejscach. Umiejętność posługiwania się nimi pozwala na robienie zdjęć i zapisywanie ich z wykrywaniem twarzy.
Zdjęcia twarzy powinny być tak przygotowane, by obejmowały ujęcia z różnych kątów, pod którymi ma być ona rozpoznawana. Gdy wszystkie zdjęcia będą zebrane, należy uruchomić program trenujący algorytm. Został on pokazany na listingu 2.
Jego działanie polega na wczytaniu kolejnych plików i tworzeniu modelu (funkcja cv2.createEigenFaceRecognizer()), który następnie jest trenowany (funkcja model.train()), po czym zapisywany do pliku (funkcja model.save()). Na koniec zapisywane są: uśredniony obraz twarzy pozytywnych, obraz cech typowych dla twarzy pozytywnych i obraz cech typowych dla twarzy negatywnych.
Działanie programu

Fotografia 4. Gotowy sejf
Po przeprowadzeniu szkolenia można uruchomić kompletny program. Jego fragment prezentujemy na listingu 3. W kodzie tym istotne jest użycie funkcji model.predict(), która pozwala sprawdzić, czy obraz pasuje do wytrenowanego wcześniej, pozytywnego wzorca.
Zwraca ona nie tylko informację o tym, czy obraz pasuje bardziej do wzorca pozytywnego niż do wzorców negatywnych, ale też z jakim stopniem pewności dokonano porównania. Sejf otwiera się wtedy, gdy stopień pewności jest odpowiednio dobry, tzn. gdy zwracana wartość nie przekracza arbitralnie ustalonej wcześniej wartości granicznej.
Do zaryglowania i odryglowania zamka autor użył poleceń box.lock() i box.unlock(). Polecenia te odnoszą się bezpośrednio do komend przesunięcia serwomechanizmu do zadanych pozycji (funkcja servo.set_servo()).
Podsumowanie i ocena projektu
Zaprezentowany projekt jest bardzo ciekawy, ponieważ pokazuje, jak w prosty sposób zrealizować - wydawałoby się - niełatwe zadanie. Pewną trudność może stanowić konieczność kompilacji bibliotek OpenCV na Raspberry Pi, ale w praktyce, oprócz tego, że jest to czasochłonny proces, nie wymaga wielkich umiejętności i powinien się udać każdemu.
Naturalnie projekt jest niedopracowany, jeśli chodzi o część mechaniczną, gdyż tak zaprojektowane pudełko łatwo otworzyć czy zatrzasnąć, a sam mechanizm rozpoznawania twarzy jest daleki od idealności. Dobrze by było wprowadzić też możliwość rozpoznawania wielu różnych twarzy, tak by nie tylko jeden użytkownik mógł otworzyć sejf.
Marcin Karbowniczek, EP












