 Zaloguj
Zaloguj




Pierwszym przykładem będzie mało przydatna w praktyce, ale idealna, jako przykład startowy sieć realizująca działanie funkcji XOR. Na początku przygotujemy dane szkoleniowe i utworzymy model sieci oraz wytrenujemy jej wagi w pakiecie TensorFlow. Następnie wygenerujemy model TensorFlow lite i na jego podstawie otrzymamy kod dla mikrokontrolera STM32.
Uczymy sieć
Do trenowania sieci zastosujemy środowisko Google Colab [1]. Możemy tam tworzyć notatniki i uruchamiać je w chmurze. Dzięki temu mamy już zainstalowane potrzebne biblioteki. Cały kod użyty w projekcie znajduje się w [2]. Na listingu 1 pokazano kod odpowiedzialny za importowanie bibliotek, z których będziemy korzystać. Są to moduły:
- TensorFlow, który dostarcza funkcji dla sieci neuronowych,
- NumPy odpowiadający za efektywne obliczenia numeryczne.
import tensorflow as tf
import numpy as np
print(“TensorFlow version:”, tf.__version__)
Dla sprawdzenia wyświetlamy wersję TensorFlow. Ja używałem wersji 2.8.2.
Kolejnym krokiem jest przygotowanie treningowego zbioru danych (listing 2). Ponieważ w naszym przypadku mamy tylko 4 punkty, dla których będziemy używać naszej sieci, to będą one zarówno zbiorem treningowym jak i użytym do oceny modelu. Zarówno wejścia jak i wyjścia naszej sieci będą liczbami zmiennoprzecinkowymi typu float32. Przyjmiemy więc, że stan 0 zakodujemy jako –127, a 1 jako +127. Natomiast stan wyjścia będziemy oceniać na podstawie znaku. Zero i więcej będą odpowiadać logicznej 1, natomiast liczby ujemne będą interpretowane jako 0.
data_x = np.array([
[-127.0, -127.0],
[-127.0, 127.0],
[127.0, -127.0],
[127.0, 127.0]
], dtype=np.float32)
data_y = np.array([
-127.0,
127.0,
127.0,
-127.0
], dtype=np.float32)
Dla naszego zadania wystarczyłaby mniejsza sieć, ale wtedy algorytm uczenia miałby problem ze znalezieniem satysfakcjonujących nas wag. Moglibyśmy je dobrać ręcznie (co dla naszego małego przypadku byłoby proste). Ale my po prostu zwiększymy rozmiar modelu. Został on pokazany na rysunku 1 oraz listingu 3.
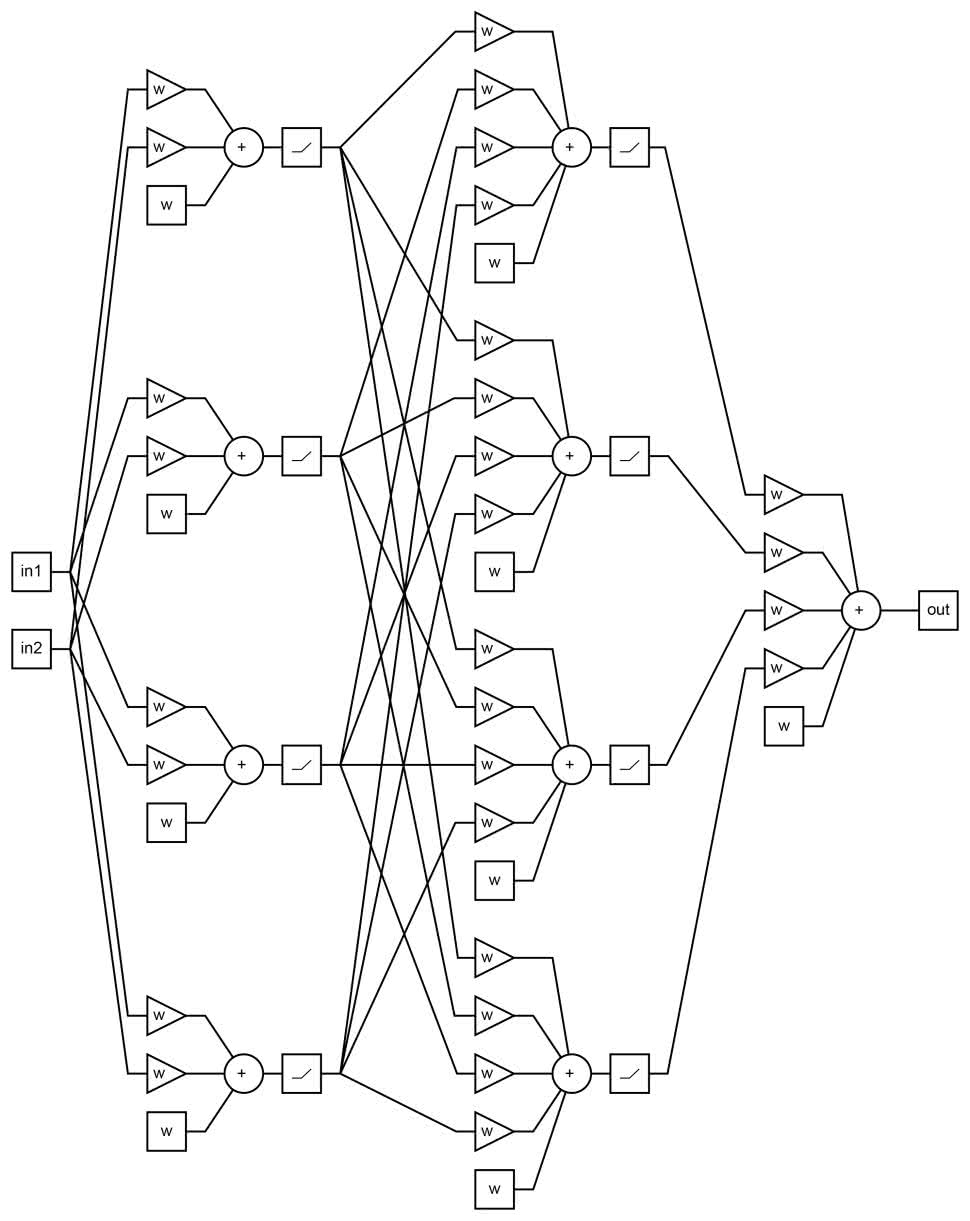
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(4, activation=’relu’),
tf.keras.layers.Dense(4, activation=’relu’),
tf.keras.layers.Dense(1, activation=’linear’),
])
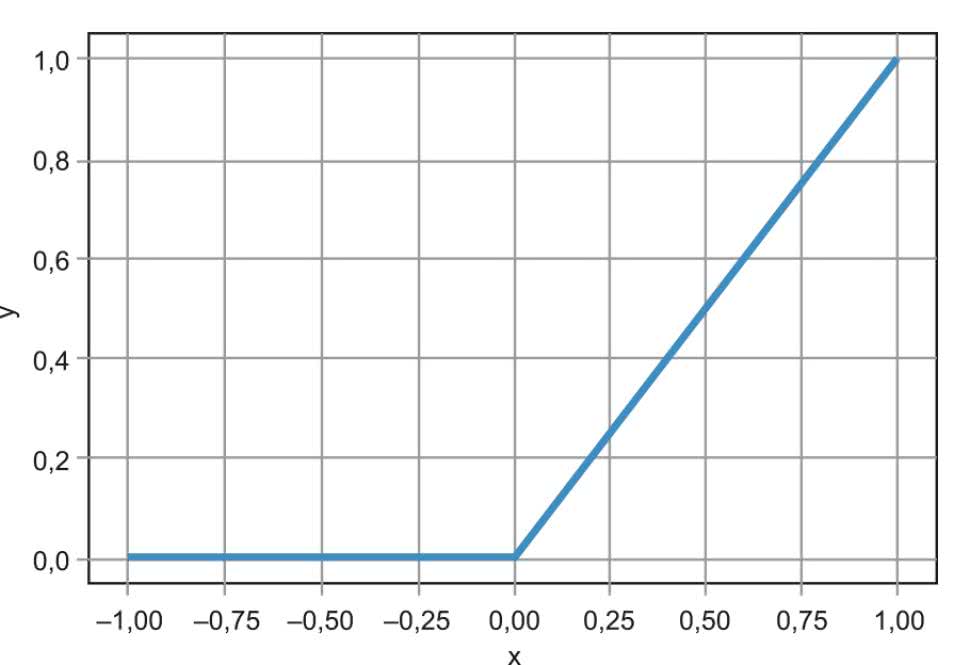
Stosujemy trzy warstwy. W dwóch pierwszych są po cztery neurony z nieliniowością typu ReLU (Rectifed linear unit linear – poprawiona jednostka liniowa). Kształt tej funkcji zaprezentowano na rysunku 2. Można ją zapisać jako:
y = max(0, x)
Na końcu mamy pojedynczą warstwę z wyjściem liniowym. Nie możemy wykorzystać tu nieliniowości ReLU, ponieważ na wyjściu chcemy otrzymywać, także wartości ujemne symbolizujące logiczne 0.
Na początku parametry sieci są wypełniane wartościami losowymi. Możemy sprawdzić jaki uzyskamy wynik dla naszych 4 punktów uruchamiając następujące działanie:
predictions = model(data_x).numpy()
Ja uzyskałem wynik:
array([[-206.96419 ],
[-132.3428 ],
[ -82.97228 ],
[ -21.927877]], dtype=float32)
Odpowiada on zwróceniu logicznego 0 dla każdej pary wejść. Jest on dość daleki od oczekiwanych przez nas wartości. Aby to poprawić musimy przeprowadzić trening sieci. Konfigurujemy więc sposób obliczania błędu pomiędzy wartością oczekiwaną, a zwracaną oraz wybieramy metodę optymalizacji – wpisujemy:
Następnie uruchamiamy szkolenie poleceniem:
W moim przypadku wystarczyło 1000 iteracji (parametr epochs) dla uzyskania satysfakcjonującego wyniku. Aby ocenić, czy efekt szkolenia jest dla nas akceptowalny obliczamy wynik dla potrzebnych nam 4 punktów i sprawdzamy, czy znak odpowiada oczekiwanej przez nas wartości. Ja otrzymałem:
array([[-127.08677 ],
[ 0.72788846],
[ 0.72788846],
[-127.08033 ]], dtype=float32)
Jeżeli wynik jest satysfakcjonujący możemy wygenerować model TensorFlow lite i zapisać go do pliku. W tym celu uruchamiamy kod:
tflite_model = converter.convert()
open(‘xor.tflite’, ‘wb’).write(tflite_model)
Teraz pobieramy wygenerowany plik. Klikamy ikonę folderu w lewej części okna, co powoduje rozwinięcie panelu Pliki pokazanego na rysunku 3 i pobieramy plik xor.tflite.
Jeżeli nie wiemy, w którym miejscu w drzewie katalogów został on zapisany, możemy wywołać w nowym polu typu Kod polecenie pwd. Zawartość pobranej sieci możemy podejrzeć na przykład za pomocą programu Neutron [3], albo bezpośrednio w środowisku STM32CubeIDE.
Mikrokontroler
Sieć jest już zaprojektowana. Musimy teraz przygotować program dla mikrokontrolera. Utworzymy go w środowisku STM32CubeIDE, które można pobrać z [4]. Jest ono zbudowane na bazie edytora Eclipse z dołączonym generatorem kodu Stm32Cube oraz kompilatorem.
Zaczniemy od pobrania biblioteki do sztucznej inteligencji. Z menu wybieramy Help i klikamy Manage embedded software packages. W oknie wybieramy zakładkę STMicroelectronics, a z listy wybieramy X-CUBE-AI w najnowszej wersji i naciskamy Install Now.
Następnie tworzymy nowy projekt, co pokazano na rysunku 4.
W kolejnym oknie (rysunek 5) przechodzimy do zakładki Boards Select (wybór płytek) i znajdujemy płytkę Nucleo, której chcemy użyć. W moim przypadku jest to L476RG.
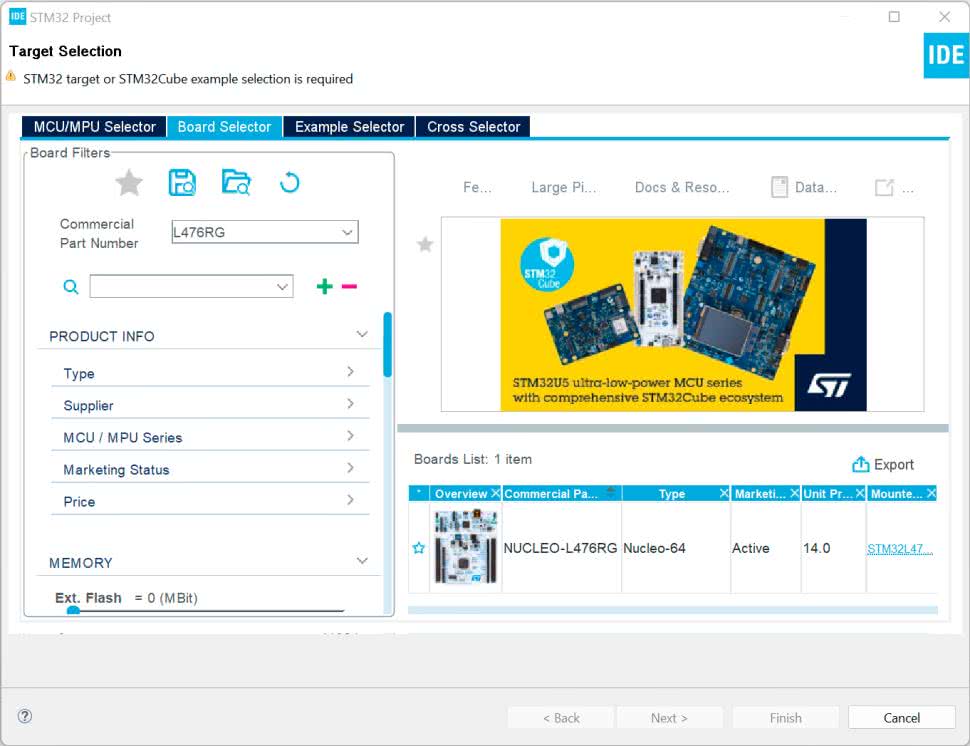
W następnym oknie (rysunek 6) wybieramy nazwę projektu i klikamy Finish, aby zakończyć.
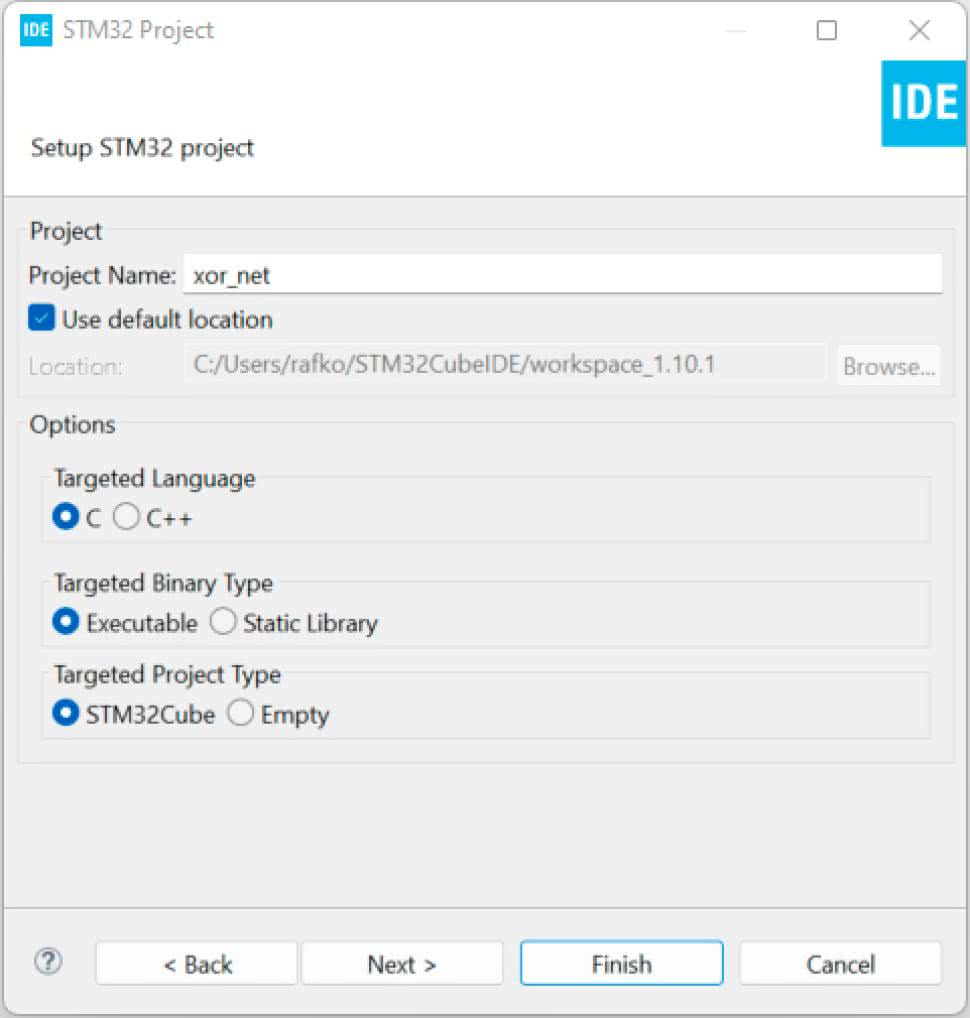
Następnie pojawi się pytanie o zainicjalizowanie peryferiów dostępnych na płytce (rysunek 7).
Potwierdzamy klikając OK. Jeżeli nie mamy wymaganych bibliotek na dysku, to zostaną one automatycznie pobrane o czym poinformuje nas ekran podobny do pokazanego na rysunku 8.
Gdy projekt zostanie utworzony, zostaniemy zapytani, czy otworzyć ekran konfiguracji (rysunek 9) – klikamy Yes.
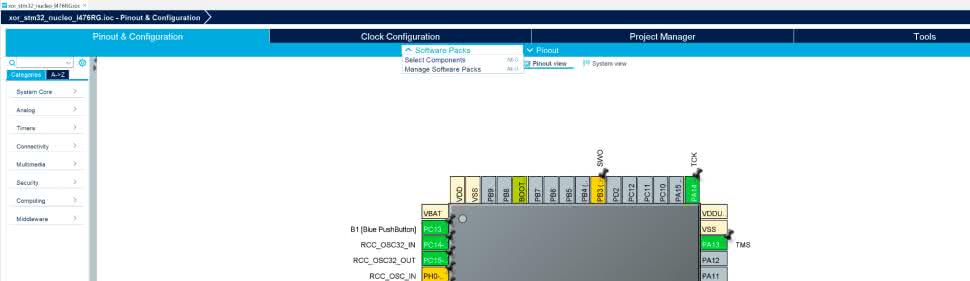
Zobaczymy otwarte okno pozwalające na konfigurację projektu. Zaczniemy od skonfigurowania sieci neuronowej. W tym celu na górnym pasku klikamy Software package i z rozwiniętego menu wybieramy Select Components (rysunek 10).
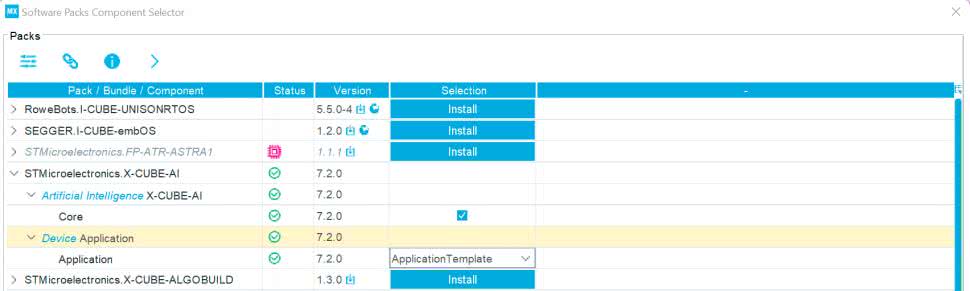
Ukaże się lista dostępnych paczek (rysunek 11), rozwijamy STMicroelectronics X-CUBE-AI. Zaznaczamy tic w polu X-CUBE-AI Core. Natomiast w zakładce Application wybieramy z listy Application Template (szablon aplikacji). Po zatwierdzeniu możemy dostać pytanie, czy chcemy zmienić ustawienia zegara, w celu zwiększenia wydajności. Zgadzamy się klikając Yes.
Wracamy do głównego okna konfiguratora. W prawym panelu rozwijamy Software Package i wybieramy STMicroelectronic.X-CUBE-AI. Pojawi się ekran jak na rysunku 12.
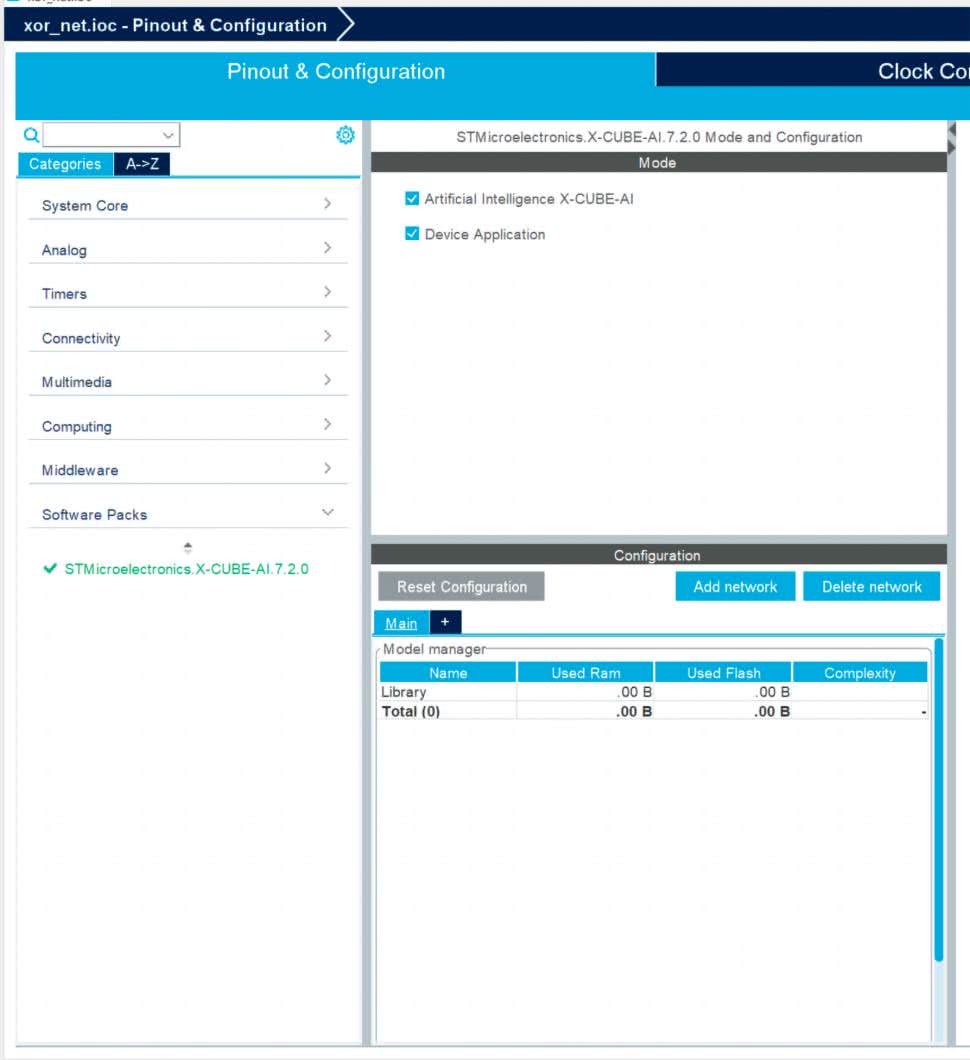
Widzimy, że w polu Mode zaznaczone są obie opcje – zarówno biblioteka jak i przykładowa aplikacja. W polu configure klikamy przycisk Add network. Zobaczymy okno jak na rysunku 13, w polu tekstowym Model Inputs wpisujemy nazwę naszej sieci. Ja wybrałem xor. Wybieramy rodzaj sieci na TFLite oraz STM32Cube.AI runtime.
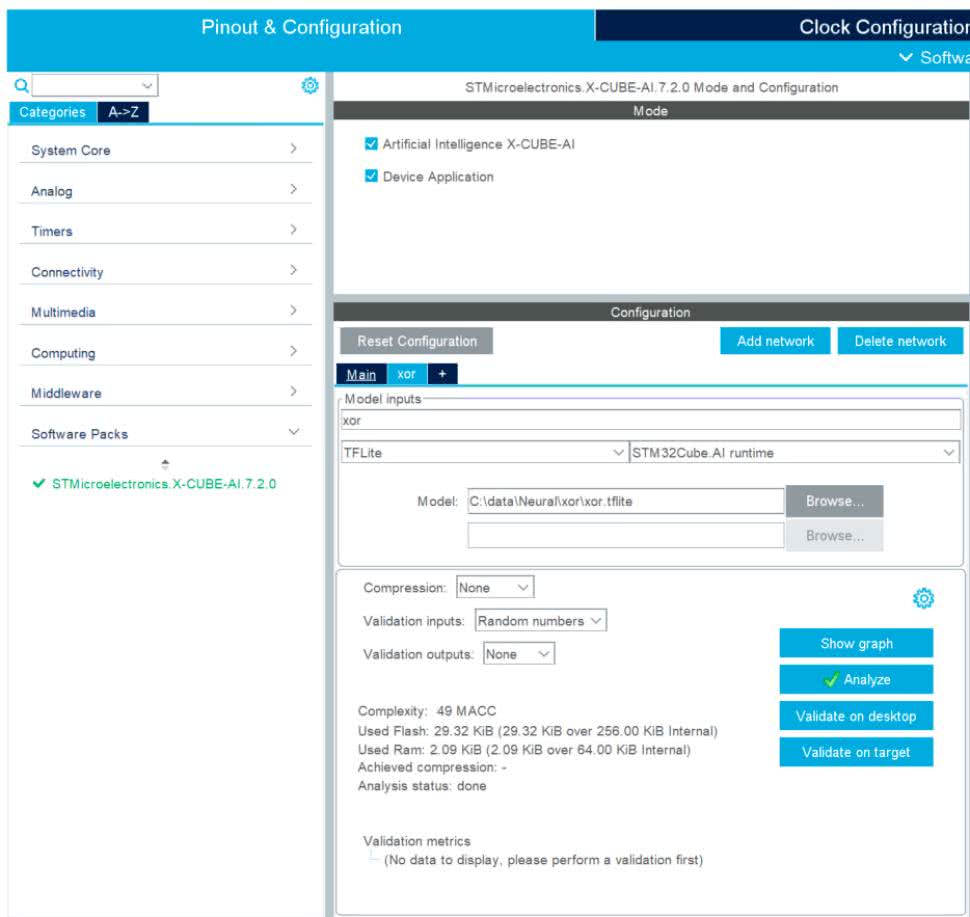
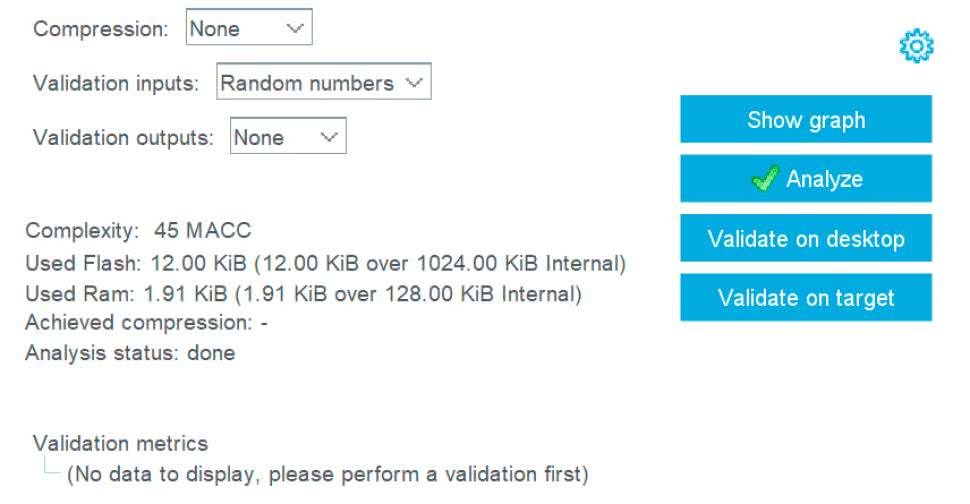
Klikamy Browser i wybieramy pobrany wcześniej plik xor.tflite. Znajdziemy go, także w repozytorium [5] i naciskamy przycisk Analyze. Otworzy się nowe okno, w którym będą pojawiały się informacje o postępach. Gdy się zakończy klikamy OK. Po chwili, w głównej aplikacji zobaczymy parametry naszej sieci oraz ilość potrzebnej pamięci RAM i Flash (rysunek 14).
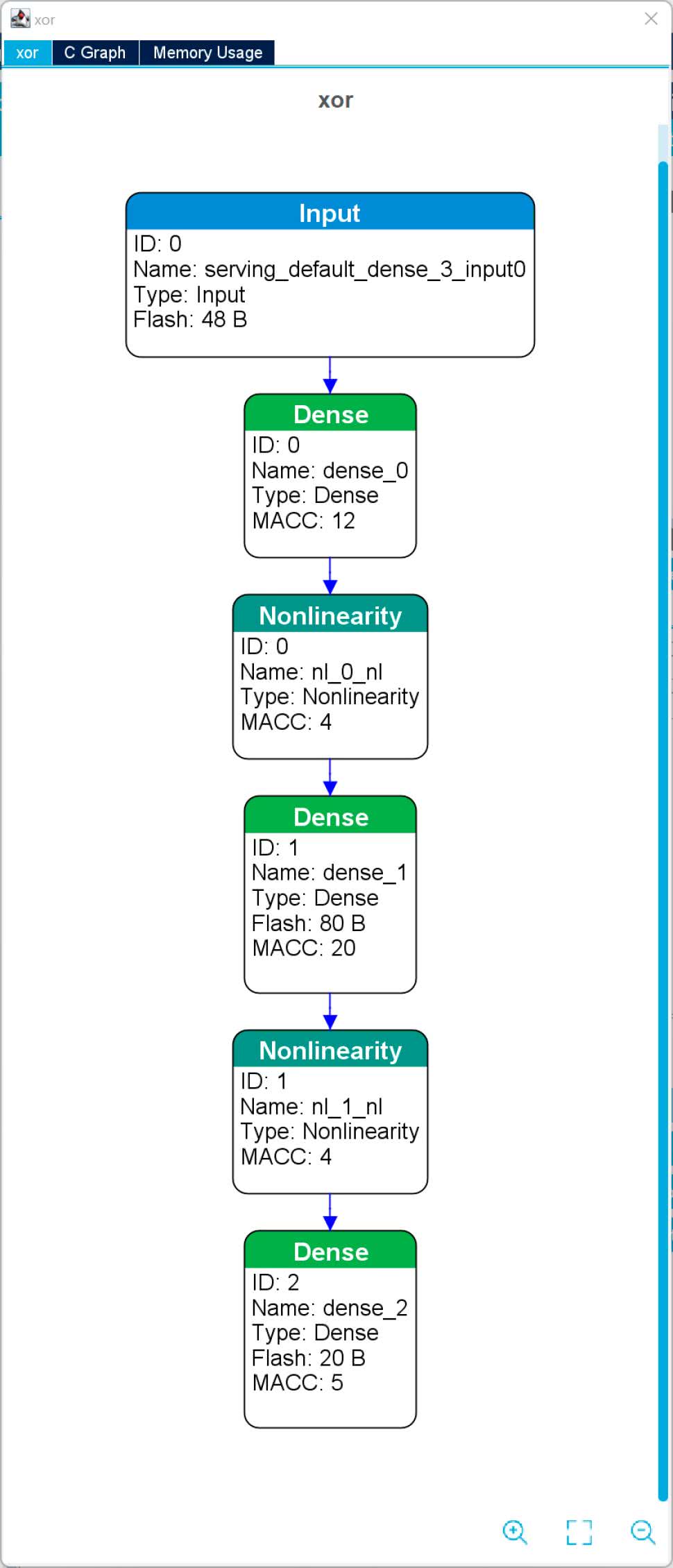
Klikając Show Graph możemy wyświetlić schemat załadowanej sieci (rysunek 15). Ciekawą funkcją jest Validate on Target. Pozwala on na wygenerowanie testowej aplikacji, która zostanie uruchomiona bezpośrednio na naszej płytce. Najpierw jednak musimy wygenerować kod. W tym celu po prostu zapisujemy nasz projekt. Wtedy powinno się pojawić okno dialogowe z pytaniem, czy wygenerować pliki. Potwierdzamy.
Jeżeli zostaniemy przeniesieni do widoku edycji kodu musimy z powrotem wrócić do widoku konfiguracji. W tym celu w znajdujący się w lewej części okna panelu z listą plików wybieramy i otwieramy plik o rozszerzeniu .ino. Teraz możemy już nacisnąć przycisk Validate on target. Po kliknięciu zobaczymy okno konfiguracji (rysunek 16).
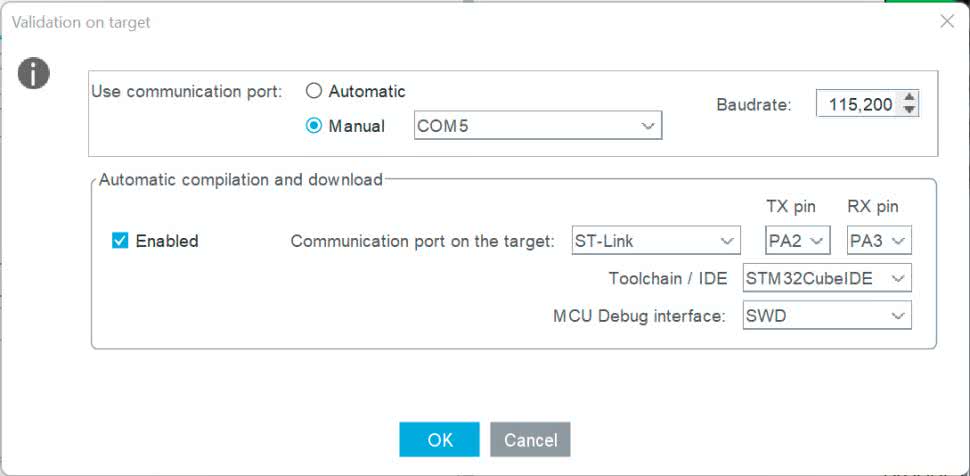
Przy ustawieniach portu szeregowego wybieramy Manual i zaznaczamy port szeregowy pod którym system operacyjny widzi naszą płytkę. W drugiej części zaznaczamy Enabled przy automatycznym tworzeniu i wgrywaniu projektu. Pozostałe opcje pozostawiamy bez zmian. Zatwierdzamy klikając OK. Otworzy się okno, w którym zobaczymy informację o postępach oraz wyniki. Możemy dowiedzieć się o ile różnią się wartości uzyskane na komputerze oraz na mikrokontrolerze. Znajdziemy także czas wykonania się poszczególnych warstw (listing 4). Widzimy, że pojedyncze wywołanie naszej sieci zajmuje 36 μs, czyli 2892 cykle zegara. Znajdziemy także rozpiskę jaki procent czasu zajmuje która warstwa. Gdy zapoznamy się z wynikami zamykamy okno naciskając OK.
Results for 10 inference(s) – average per inference
device : 0x415 – STM32L4x6xx @80/80MHz fpu,art_lat=4,art_prefetch,art_icache,art_dcache
duration : 0.036ms
CPU cycles : 2892
cycles/MACC : 64.28
c_nodes : 5
c_id m_id desc output ms %
------------------------------------------------------------------------
0 0 Dense (0x104) (1,1,1,4)/float32/16B 0.009 25.4%
1 0 NL (0x107) (1,1,1,4)/float32/16B 0.004 12.3%
2 1 Dense (0x104) (1,1,1,4)/float32/16B 0.010 28.1%
3 1 NL (0x107) (1,1,1,4)/float32/16B 0.004 12.1%
4 2 Dense (0x104) (1,1,1,1)/float32/4B 0.008 22.1%
------------------------------------------------------------------------
0.036 ms
Wróćmy jednak do naszego projektu. Zostało nam jeszcze skonfigurowanie portów mikrokontrolera. Przechodzimy do głównego ekranu konfiguratora, tego z rysunkiem układu scalonego (rysunek 17).
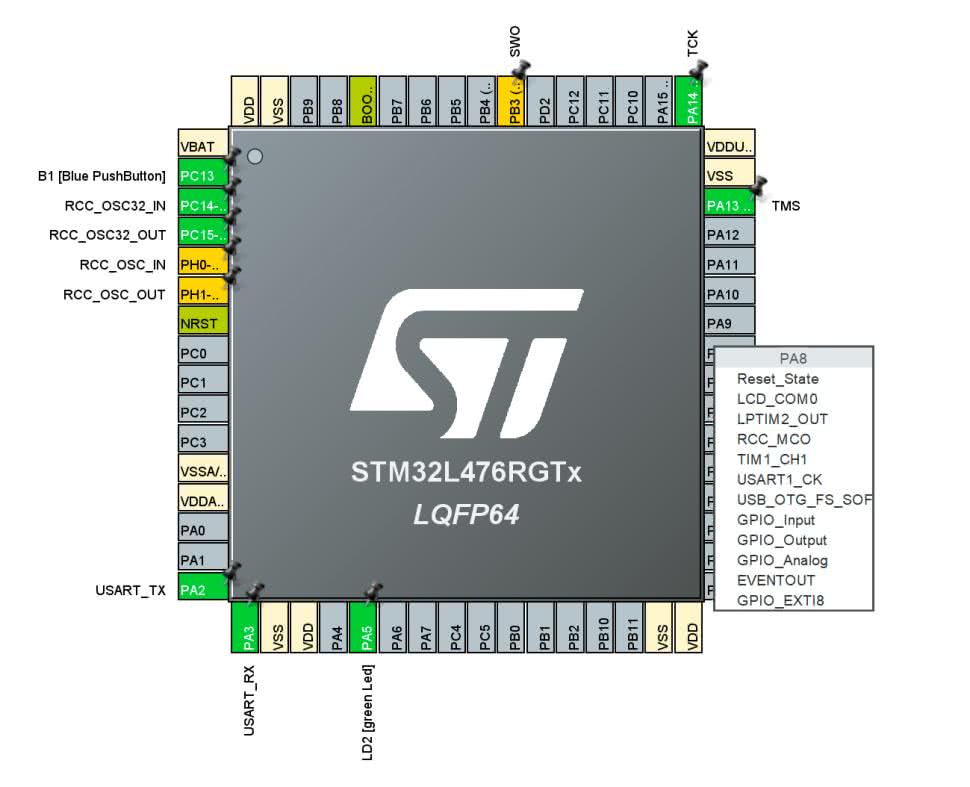
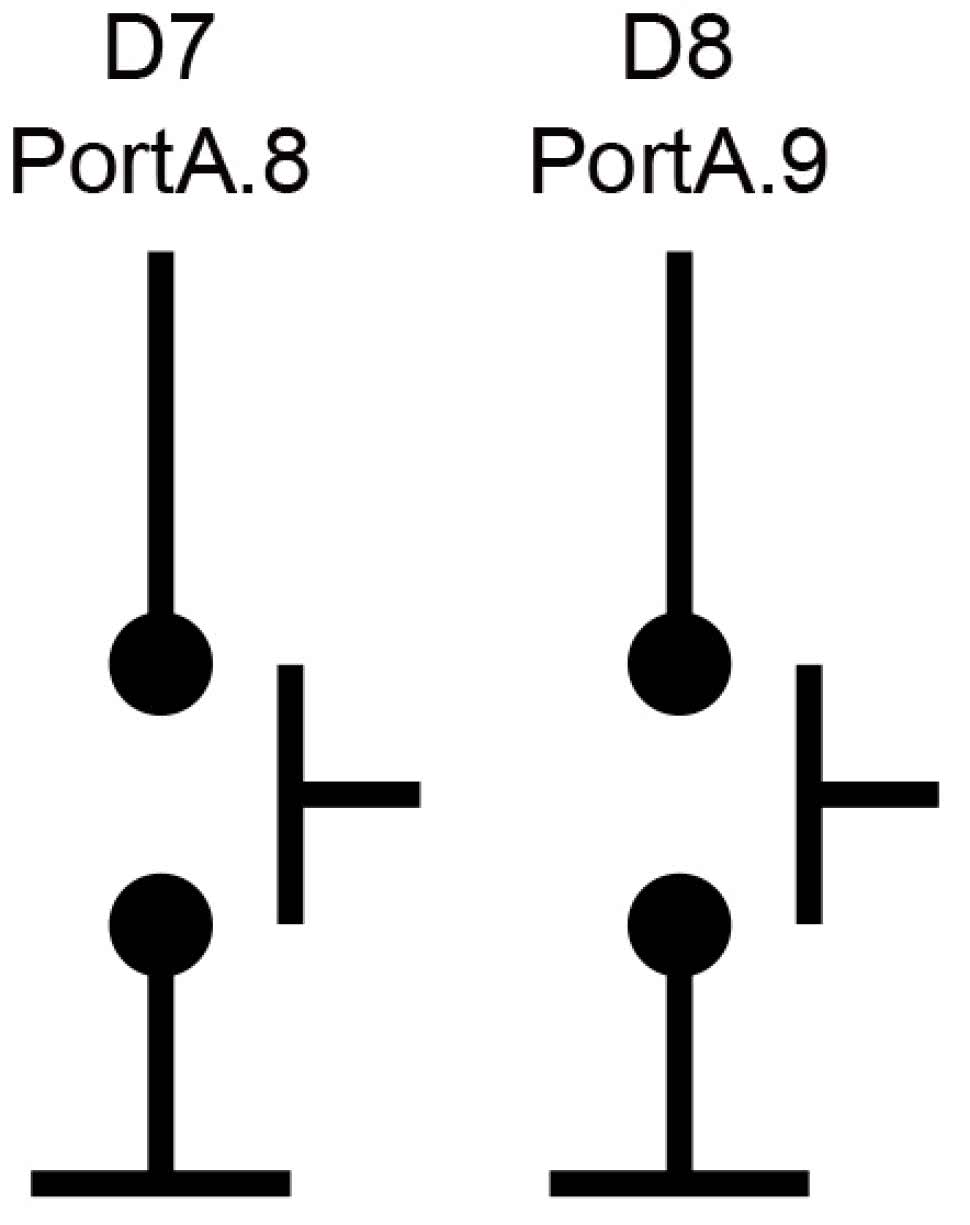
Widzimy, że PA5, do którego jest podłączona dioda LED został już skonfigurowany. Pozostaje nam jeszcze ustawienie wejść dla przycisków. Podłączymy je na płytce stykowej zgodnie z rysunkiem 18.
Klikamy więc lewym przyciskiem myszy na PortA.8, a następnie PortA.9 i dla każdego z nich wybierzmy GPIO_Input. Następnie w prawym panelu rozwijamy wybieramy System Core i klikamy GPIO (rysunek 19).
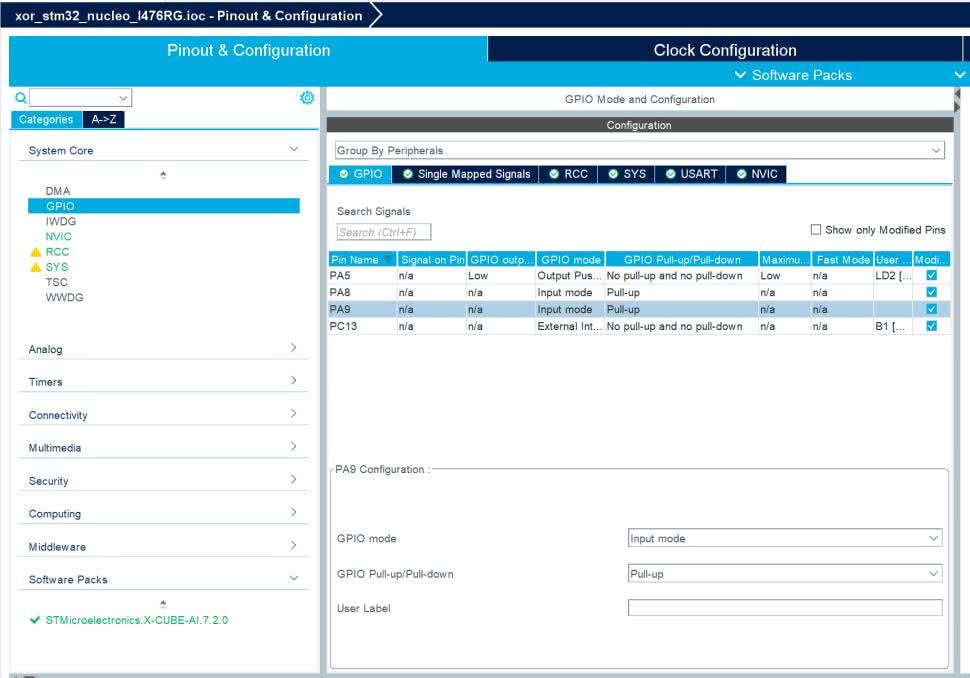
W środkowym panelu wybieramy najpierw PortA.8, a następnie PortA.9 i dla każdego włączamy podciąganie do plusa (pull-up). W tym samym panelu widzimy, że PortA.5, do którego podłączona jest dioda LED znajdująca się w zestawie, został już skonfigurowany jako wyjście. Możemy także sprawdzić, że konfiguracja portu szeregowego, podłączonego do USB, także jest gotowa. Gdy zapiszemy projekt, zostaniemy zapytani, czy wygenerować kod, potwierdzamy.
Kolejne okienko pyta, czy przełączyć w tryb edycji kodu. Tu także potwierdzamy.
Printf
Aby uprościć debbugowanie przekierujemy standardową funkcję z biblioteki C: printf na port szeregowy. W tym celu w pliku Core/Src/main.c w bloku /* USER CODE BEGIN PV */ dodajemy definicję dwóch funkcji (listing 5).
int __io_putchar(int ch){
HAL_UART_Transmit(&huart2, (uint8_t *)&ch, 1, HAL_MAX_DELAY);
return ch;
}
int _write(int file, char *ptr, int len){
int DataIdx;
for (DataIdx = 0; DataIdx < len; DataIdx++){
__io_putchar(*ptr++);
}
return len;
}
Funkcja _write służy do wysłania ciągu znaków na standardowe wyjściu. W niej każdy znak jest przekazany do funkcji __io_putchar. Druga z nich wywołuje funkcję z biblioteki HAL, która odpowiada za obsługę portu szeregowego. Sam UART został automatycznie skonfigurowany przy wyborze płytki na prędkość 115200.
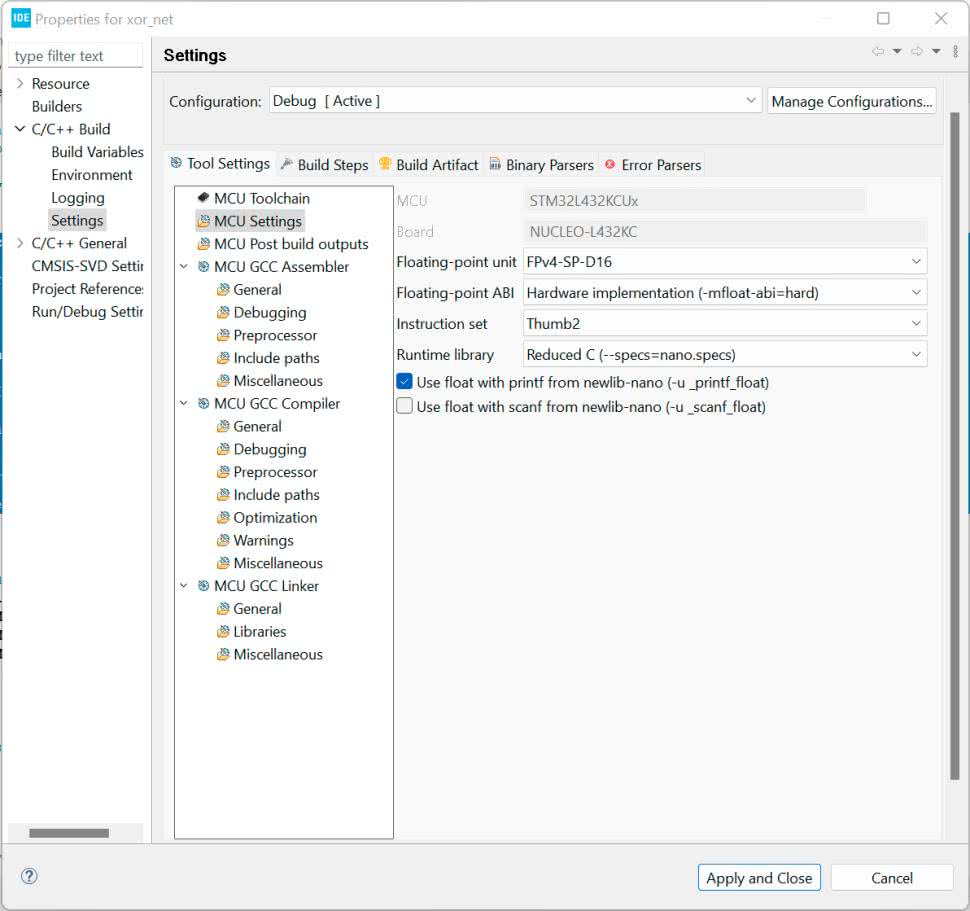
Drugą częścią jest włączenie wypisywania liczb zmiennoprzecinkowych. Aby ograniczyć rozmiar kodu wynikowego ta opcja jest domyślnie wyłączona. Na prawym pasku z listą plików znajdujemy nasz projekt i klikamy go prawym przyciskiem myszy. Z listy wybieramy Properties. W nowym oknie (rysunek 20) przechodzimy do zakładki C/C++ Build —> Settings —> MCU Settings i zaznaczamy tic przy opcji Use float with printf.
Uruchamiamy sieć
Czytając dalej plik main.c znajdziemy, że przy konfiguracji wywoływana jest funkcja MX_X_CUBE_AI_Init(), a w głównej pętli programu MX_X_CUBE_AI_Process(). Ich implementację znajdziemy w X-CUBE-AI/App/app_x-cube-ai.c. Musimy zmodyfikować jedynie drugą z nich. Jej zawartość po zmianach pokazuje listing 6. Na początku definiujemy zmienne: nn_input jest tablicą z wejściami dla sieci, a do nn_output zostaną wpisane wyniki. Rozmiar wejścia i wyjścia jest zdefiniowany przez stałe i wynosi odpowiednio 2 i 1, co jest zgodne z tym co skonfigurowaliśmy w TensorFLow. Wejścia sieci są odczytywane z przycisków. Jeśli przycisk jest naciśnięty wpisujemy 127, a w przeciwnym razie –127.
void MX_X_CUBE_AI_Process(void){
/* USER CODE BEGIN 6 */
ai_i32 batch;
float nn_input[AI_XOR_IN_1_SIZE];
float nn_output[AI_XOR_OUT_1_SIZE];
nn_input[0] = HAL_GPIO_ReadPin(GPIOA, GPIO_PIN_8) ? 127.0 : -127.0;
nn_input[1] = HAL_GPIO_ReadPin(GPIOA, GPIO_PIN_9) ? 127.0 : -127.0;
ai_input->data = nn_input;
ai_output->data = nn_output;
batch = ai_xor_run(xor, ai_input, ai_output);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_5, nn_output[0]>=0 ? 1 : 0);
printf("%f\r\n", nn_output[0]);
if (batch != 1) {
ai_log_err(ai_xor_get_error(xor), "ai_xr_run");
}
/* USER CODE END 6 */
}
Następnie przypisujemy wskaźniki do tablic z danymi do pól data struktur z wejściem i wyjściem sieci. Wywołanie obliczeń następuje w funkcji ai_xor_run. Jeżeli otrzymany wynik jest dodatni, dioda led jest zaświecana, a gdy ujemny gaszona. Na końcu wypisujemy wartość zwrócona przez sieć na port szeregowy. Cały program można pobrać z repozytorium [5]. Podłączamy przyciski do pinów D7 i D8 zgodnie ze schematem z rysunku 18. Kompilujemy projekt i programujemy płytkę za pomocą przycisku Run(). Gotowy model został pokazany na fotografii tytułowej. Stan diody LD2 powinien być funkcją xor przycisków. Gdy otworzymy monitor portu szeregowego zobaczymy dokładny wynik uzyskany z sieci neuronowej.
Uruchomiliśmy pierwszą sieć neuronowa na mikrokontrolerze. Jednak obliczanie funkcji xor nie jest zbyt intrygującym zadaniem. Dlatego w drugiej części uruchomimy rozpoznawanie kształtów.
Rafał Kozik
rafkozik@gmail.com
Bibliografia:
[1] https://bit.ly/3Q9v7b5
[2] https://bit.ly/3IgeYyR
[3] https://bit.ly/3Grh2Ct
[4] https://bit.ly/2XsPWlH
[5] https://bit.ly/3Q3weJx












