 Zaloguj
Zaloguj





Fotografia 1. Platforma Sabre wyposażona w procesor i.MX 6
Jak wspomniano w pierwszej części artykułu (EP 6/2015), aplikacja OpenCL składa się z dwóch komponentów: jeden jest uruchamiany na Hoście (służy on do zarządzania systemem i zawiera kod kontrolujący wykonywanie aplikacji), natomiast drugi jest uruchamiany na Urządzeniu Przetwarzającym, zwykle wykonującym najcięższą pracę przy przetwarzaniu danych.
W niektórych urządzeniach (na przykład - w typowym komputerze PC wyposażonym w kartę graficzną) są to odseparowane urządzenia, ale nie w systemach embedded, ponieważ większość nowoczesnych procesorów aplikacyjnych zawiera zintegrowaną jednostkę GPU, które może wykonywać aplikacje OpenCL.
Dla potrzeb aplikacji demonstracyjnej wykorzystaliśmy ten sam 4-rdzeniowy procesor i.MX6, który opisywaliśmy w pierwszej części artykułu. Tam posłużyliśmy się nim dla celu zaprezentowania struktury nowoczesnego GPU widzianego z perspektywy OpenCL.

Rysunek 2. Obraz wyświetlany przez aplikację demonstracyjną na ekranie LCD
Host jest reprezentowany przez klaster 4 rdzeni ARM A9, natomiast Urządzenie Przetwarzające przez procesor graficzny GC2000. Jako system do uruchomienia naszej aplikacji wybraliśmy płytkę demonstracyjną i.MX6 Sabre, jedną z platform referencyjnych dla tego układu SoC (pokazano ją na fotografii 1).
Tworząc może nieco mało ambitną aplikację OpenCL typu "Hello World" na ekranie platformy Sabre wyświetlimy symulację przemieszczania się cząstek poddanych (w systemie zamkniętym) oddziaływaniu predefiniowanych sił. Początkowy zestaw cząstek będzie określony za pomocą bitmapy.
Na rysunku 2 pokazano wygląd ekranu w różnych stanach pracy aplikacji (lub czasu życia systemu cząstek). Mamy nadzieję, że ta przykładowa aplikacji zachęci czytelnika do jej powielenia, samodzielnego eksperymentowania, a także przeanalizowania znaczenia i sposobu działania poszczególnych funkcji.
Dla ułatwienia samodzielnej pracy, omówimy niezbędne nastawy systemu, rolę Hosta oraz Urządzenia Przetwarzającego.
Nastawy sytemu

Rysunek 3. Szczegóły implementacji main()
Jako środowiska projektowego dla Hosta użyjemy kompilatora języka C pracującego pod kontrolą Linuksa. Dla naszej przykładowej platformy Sablre użyjemy najnowszej wersji Linuksa BSP, dostępnego do pobrania na stronie http://www.freescale.com w menu Software and Tools/Software development tools dla procesora i.MX6.
W czasie pisania artykułu najnowsza wersja Linuksa BSP nosi oznaczenie L3_10_53_1.1.0. Sposób wykonania obrazu systemu - oczywiście po pobraniu Linuksa BSPA - jest opisany w Freescale Yocto Project User’s Guide. Dla potrzeb aplikacji demonstracyjnej OpenCL będziemy używali bufora ramek obrazu, więc najlepiej posłużyć się obrazem o nazwie fsl-image-gui, ponieważ zawiera on wszystkie potrzebne biblioteki wymagane przez naszą aplikację.
Jeśli program demonstracyjny będzie uruchamiany na innej platformie z i.MX6, to należy włączyć wsparcie dla obsługi bufora ramek oraz mieć zainstalowany pakiet gpu-viv-bin-mx6q.
Kompletny kod źródłowy opisywanej aplikacji oraz instrukcja jej skompilowania i uruchomienia/wgrania na platformie docelowej są opublikowane pod adresem internetowym społeczności Freescale https://community.freescale.com/docs/DOC-103684.
Opis aplikacji dla Hosta
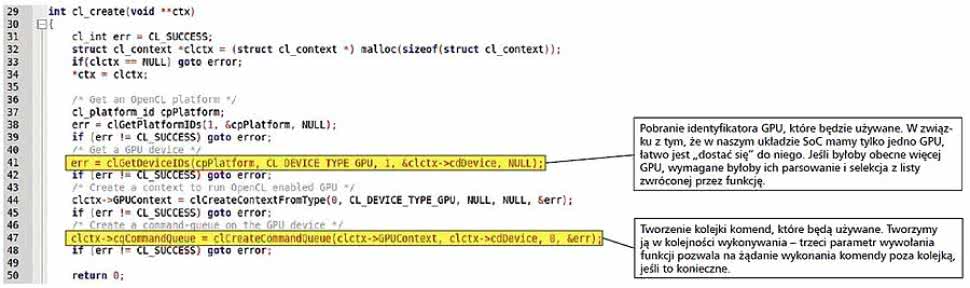
Rysunek 4. Szczegóły funkcji cl_create()
Zanim zaprezentujemy szczegóły dotyczące wykonania aplikacji dla Hosta, pokrótce omówimy funkcje pełnione przez poszczególne komponenty systemu OpenCL:
- Interfejs użytkownika.
- Konfiguracja systemu, wliczając w to rozpoznanie i konfigurowanie Urządzenia Przetwarzającego.
- Utworzenie kanałów komunikacyjnych służących do wymiany danych i komend z Urządzeniem Przetwarzającym.
- Transmisja danych, przetwarzanie, gromadzenie i prezentowanie rezultatów przetwarzania wykonywanego przez Urządzenie Przetwarzające.
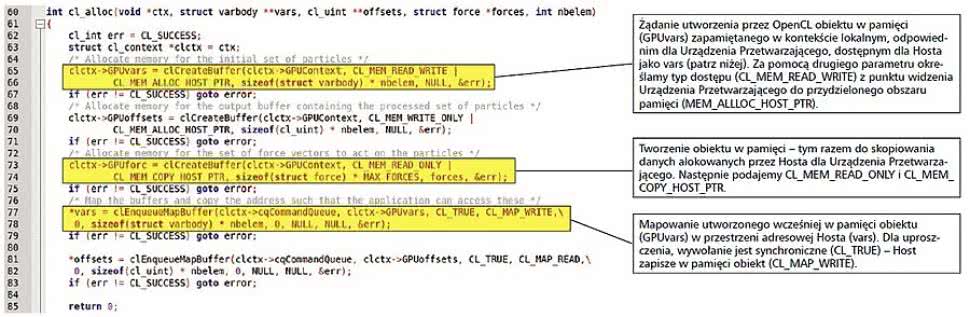
Rysunek 5. Szczegóły implementacji funkcji cl_alloc()
Zanim zidentyfikujemy i wyjaśnimy sposób, w jaki są te zadania realizowane, pokrótce zaprezentujemy minimalny zestaw struktur danych OpenCL, dzięki którym jest możliwe wykonanie wszystkich wymienionych zadań:
- Kontekst (cl_context):
- Program obsługi zapewniany przez framework OpenCL na żądanie dostępu przez Hosta do Urządzenia Przetwarzającego.
- Pozwala frameworkowi OpenC, a w naszym wypadku - sterownikowi GPU, na zarządzenie odpowiednimi obiektami (pamięć, komendy, kernel, synchronizacja) odnoszącymi się do interakcji pomiędzy Hostem a Urządzeniem Przetwarzającym.
- Kolejka komend (cl_command_queue):
- Kanał komunikacyjny pomiędzy Hostem i kontekstem skojarzonym z danym Urządzeniem Przetwarzającym. Pozwala on Hostowi na żądanie wykonywania zadań związanych z obiektami skojarzonymi z kontekstem.
- Użycie kolejki pozwala na łatwe synchronizowanie żądanych operacji - najwygodniejsze jest żądanie wykonania zadań w ramach frameworku Open CL/Urządzenia Przetwarzającego, co może mieć wpływ na wydajność.
- Dozwolone jest powiązanie wielu kolejek z tym samym kontekstem, ale w takim wypadku synchronizacja musi być zapewniana przez Hosta. Ta technika jest używana w celu zapewnienia optymalnej wydajności zwłaszcza wtedy, gdy jest wiele Urządzeń Przetwarzających.
- Kernel (cl_kernel):
- Funkcja przeznaczona do uruchomienia na Urządzeniu Przetwarzającym.
- Jest kompilowana (w trybie off line lub podczas pracy) i ładowana do urządzenia przetwarzającego przez Hosta.
- Obiekty w pamięci (cl_mem):
- Mogą służyć do jednokierunkowej lub dwukierunkowej transmisji danych pomiędzy Hostem i Urządzeniem Przetwarzającym.
- Najprostszą postacią jest tablica niezwymiarowana, ale używane mogą być również tablice wielowymiarowe (do 3 wymiarów).
- W aktualnej implementacji wymiany danych są dwie najważniejsze metody realizacji tego zadania:
- Mapowanie fizycznie dzielonych obszarów pamięci w obu kontekstach wykonywania zadań (Host i Urządzenie Przetwarzające).
- Poleganie na kopiach danych wykonywanych w razie potrzeby przez framework OpenCL.
- Wybór metody transmisji/wymiany danych ma znaczny wpływ na wydajność i jest silnie związany z systemem, pod którego kontrolą jest uruchamiana aplikacja.

Rysunek 6. Szczegóły implementacji funkcji cl_init()
W naszym przykładzie oprogramowanie Hosta jest implementowane w dwóch zbiorach źródłowych w języku C:
- main.c:
- Inicjalizuje ekran i struktury danych reprezentujące siły występujące w systemie.
- Czyta bitmapy wejściowe, oddziela fragmenty, które będą przetwarzane.
- Używa funkcji zaimplementowanych w cl_implem.c do utworzenia, inicjalizacji i zarządzania przetwarzaniem przez GPU.
- cl_implem.c:
- Zawiera funkcje potrzebne do wsparcia interakcji pomiędzy Hostem i Urządzeniem Przetwarzającym, utworzone "w oderwaniu" frameworka OpenCL.

Rysunek 7. Szczegóły funkcji cl_run()
Implementację funkcji main() w pliku main.c pokazano na rysunku 3 z dodatkowymi uwagami odnośnie do kolejności wykonywania. Byłoby idealnie, gdyby czytelnik równolegle zapoznał się z opisem w artykule oraz wyjaśnieniami w ramkach na rys. 3, odnosząc to do kodu źródłowego.
Należy zauważyć, że wersja OpenCL wspierana przez procesor aplikacyjny i.MX 6 GPU to OpenCL 1.1 profil embedded. Znajduje to odzwierciedlenie w API frameworka OpenCL wykorzystanym w przykładowym programie - niektóre jego elementy zmieniły się po przeniesieniu do OpenCL 2.0.
Funkcje pomocnicze obecne w OpenCL, które są wywoływane przez funkcję main() są zaprezentowane na rysunkach 4...8. Nie będziemy komentowali wywołania każdej z funkcji OpenCL, ale opatrzymy uwagami tylko te, które pomogą czytelnikowi w łatwiejszym zrozumieniu aspektów aplikacji utworzonej za pomocą OpenCL.
Opis aplikacji dla Urządzenia Przetwarzającego
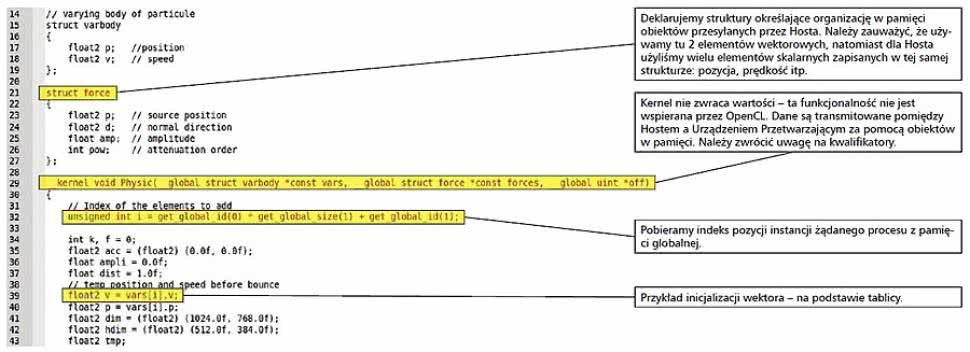
Rysunek 8. Struktury, kernel i deklarowanie zmienny prywatnych
Urządzenie Przetwarzające uruchamia "kernele", które typowo są budowane (kompilowane) przez Hosta (może to być również zrobione off line) i ładowane podczas pracy systemu. Kod źródłowy Kernela jest tworzony w języku bardzo zbliżonym do ANSI C.
Rzućmy okiem na minimalny zestaw zagadnień, które musi znać czytelnik przed przystąpieniem do analizowania kodu Kernela. Te zagadnienia są związane z: podziałem obszaru pamięci aplikacji, typami danych, prototypem Kernela oraz restrykcjami OpenCL w ANSI C.
W pierwszej części artykułu wprowadziliśmy pojęcie przestrzeni adresowych definiowanych przez OpenCL. Gdy przekazywaliśmy dane pomiędzy Hostem i Urządzeniem Przetwarzającym (jak dla przykładu definicje argumentów Kernela) lub gdy deklarowaliśmy zmienne w Kernelu, musieliśmy podać kwalifikator określający, gdzie będą przechowywane argumenty. Wśród dostępnych kwalifikatorów przestrzeni pamięci dostępne są:
- Global Memory (pamięć globalna): dostępna w systemie dla Hosta i Urządzenia Przetwarzającego. Kwalifikator nosi nazwę __global.
- Constant Memory (pamięć stałych): ma takie same cechy jak pamięć globalna, ale jest przeznaczona tylko do odczytu. Przed użyciem należy zainicjować wszystkie dane umieszczone w pamięci stałej. Kwalifikator: __constant.
- Local Memory (pamięć lokalna): pamięć, która jest przydzielana dla przetwarzanych elementów. Jest ona specyfi kowana dla grupy roboczej i dostępna tylko dla komponentów należących do danej grupy. Nie może być używana do przekazywania parametrów do Kernela. Kwalifikator: __local.
- Private Memory (pamięć prywatna): dostępna dla pojedynczej instancji Kernela/elementu przetwarzanego, niewidoczna dla innych elementów roboczych. Pamięć domyślnie przeznaczona dla argumentów Kernela oraz zmiennych, jeśli nie zdecydowano inaczej. Kwalifikator: __private.

Rysunek 9. Przetwarzanie Kernela i zwracanie zmiennej result.s
Ważna cechą OpenCL jest wsparcie dla standardowych typów zmiennych numerycznych oraz niestandardowych, wektorowych, charakterystycznych dla operacji graficznych. Niektóre z typów zmiennych opisano niżej:
- Skalarne typy danych - typowe: bool, char, int i inne, znane z ANSI C. Warto zauważyć, że dostępny jest również typ half dla 16-bitowych liczb zmiennoprzecinkowych i float dla liczb 32-bitowych. Wsparcie dla 64-bitowych liczb zmiennoprzecinkowych double jest opcjonalne i definiowane za pomocą typu cl_khr_fp64.
- Wektorowe typy danych:
- Bezpośrednio związane z tablicami ANSI C. Nie wolno ani deklarować wektorów o dowolnych długościach, ani o zmiennej długości.
- Wspierane długości wektorów to: 2, 3, 4, 18 oraz 16. Dodatkowo trzeba uważać na ograniczenia sprzętowe związane z typem jednostki cieniującej, ponieważ ma to duży wpływ na wydajność.
- Wektory są deklarowane za pomocą typów zmiennych skalarnych, po których bezpośrednio jest podawana długość wektora: int3, int16, float4, double16.
- Dostęp do elementów wektora może być realizowany na kilka sposobów, ale najczęściej używa się numeru pozycji wektora poprzedzanej przez token s. Na przykład, siódmy element w zmiennej float16 my_vector to my_ vector.s7.
Każdy z wymienionych typów danych, skalarny lub wektorowy, może być używany jako element tablicy.
Uzbrojeni w nową wiedzę, przyjrzyjmy się implementacji Kernela i omówmy najważniejsze aspekty jego kodu źródłowego. Omówiono je w ramkach na rysunkach 8 i 9.
Podsumowanie
Mamy nadzieję, że artykuły będą pomocne w wykonaniu pierwszych kroków z OpenCL. Na pewno zaledwie pokazaliśmy wierzchołek góry lodowej rosnących wyzwań, poczynając od opracowania założeń aplikacji i kroków przetwarzania, jej implementacji oraz przede wszystkim - optymalizacji wydajności dla specyficznego Urządzenia Przetwarzającego. Jeśli zdecydujesz się Czytelniku zgłębiać tę domenę wiedzy, życzę Ci udanej, pouczającej podróży.
Penisoara Nicusor
Freescale Semiconductor












