 Zaloguj
Zaloguj




Podstawowe operacje zapisu i odczytu
Jeżeli wiesz, jak obsługiwać pliki w Pythonie, to przeskocz do kolejnego rozdziału.
Istnieje kilka sposobów na odczytanie pliku w Pythonie. Zaprezentujemy tylko jeden z nich, moim zdaniem najprostszy i najbezpieczniejszy. Oto on:
content = file.read() # 2
print(content) # 3
W linii 1 rozpoczynamy blok with. Jest to rodzaj zabezpieczenia powodujący, że dostęp do pliku możliwy jest tylko wewnątrz tego bloku. Wyjście z bloku jest równoznaczne z bezpiecznym zamknięciem pliku. Jest to szczególnie istotne, ponieważ opuszczenie bloku może nastąpić w wyniku wystąpienia wyjątku, związanego z jakimś błędem. W takiej sytuacji nie musimy martwić się o zapewnienie prawidłowego zamknięcia dostępu do danych na dysku.
Następnie przy pomocy funkcji open otwieramy plik do odczytu, podając ścieżkę dostępu do niego. Jeżeli plik znajduje się w wewnątrz katalogu, należy podać ścieżkę w postaci „katalog/plik.xxx” – koniecznie z ukośnikiem „/” (tzw. slash), a nie „\” (backslash). Tak otwarty plik będzie dostępny wewnątrz bloku with jako zmienna o nazwie file.
Obiekt file zawiera wiele różnych metod. Jedną z nich jest read, która odczytuje cały plik i zwraca go jako zmienną typu str (opcjonalnym argumentem funkcji read jest liczba znaków/bajtów do odczytania, lecz w naszym przykładzie nie korzystamy z tej możliwości). Tym sposobem w linii 2 odczytujemy zawartość całego pliku i zapisujemy go do zmiennej content. W linii 3 wykonujemy przykładową operację: wyświetlamy zawartość pliku na konsoli. Zwróć uwagę, że w tym miejscu plik już jest zamknięty, a operujemy wyłącznie na jego kopii zapisanej do zmiennej content.
Plik możemy odczytywać nie tylko w całości, za jednym zamachem, ale także partiami – linia po linii. W poniższym przykładzie, w linii 1, otwieramy plik w taki sam sposób, jak wcześniej. Różnica polega natomiast na zastosowaniu funkcji readlines (linia 2). Zwraca ona listę, której każdy element zawiera jedną linię odczytaną z pliku. Tak otrzymaną listę można następnie przetwarzać, np. w pętli for (linia 3), aby wyświetlić ją na konsoli (linia 4).
lines = file.readlines() # 2
for line in lines: # 3
print(line) # 4
Jeżeli chcemy zapisywać dane do pliku, w funkcji open musimy podać drugi argument, który określa tryb dostępu do pliku. Możliwe są między innymi następujące opcje:
- „w” – utworzenie nowego pliku. Jeżeli plik o podanej nazwie już istnieje, jego zawartość zostanie usunięta,
- „a” – dopisywanie danych do istniejącego już pliku,
- „r” – tylko odczyt,
- „wb”, „ab”, „rb” – tak jak powyżej, ale pliki dostępne są w trybie binarnym, czyli bez obsługi Unicode, analizowania znaków końca linii itp.
W poniższym przykładzie otwieramy plik.txt w celu dopisywania do niego nowych danych (linia 1) za pomocą funkcji write (linia 2 i kolejne).
file.write("Pierwsza linia\n") # 2
file.write("Druga linia\n")
file.write("Trzecia linia\n")
We wszystkich przykładach powyżej funkcje przyjmują i zwracają zmienne typu str. Gdybyśmy chcieli pracować z danymi liczbowymi, np. zmiennoprzecinkowymi lub jakimikolwiek innymi, to musielibyśmy je ręcznie konwertować lub skorzystać z zupełnie innego sposobu zapisywania danych, czyli...
Pliki JSON
Format JSON pochodzi z języka JavaScript, ale ma bardzo dużo podobieństw do słowników, jakie są do dyspozycji w Pythonie. Słownik to coś w rodzaju tablicy, ale elementy nie mają kolejnych numerów, lecz unikalne identyfikatory zwane kluczami. Klucze mogą być liczbami, a także stringami. Ponadto wartości przypisane kluczom mogą mieć różne typy, a nawet stanowić kolejne słowniki. W ten sposób można przechowywać różnorodne informacje, zorganizowane w hierarchiczny sposób.
Nie będziemy zagłębiać się w teorię – zobaczmy od razu listing 1. Celem tego programu jest odczytanie pliku JSON i przekonwertowanie go na słownik, a następnie poproszenie użytkownika, aby na konsoli wpisał nową parę klucz-wartość. Zostanie ona dodana do słownika, a następnie przekonwertowana z powrotem na JSON i zapisana do pliku.
import json # 1
data = {} # 2
def read_json(): # 3
try: # 4
with open("test.json") as file: # 5
global data # 6
data = json.load(file) # 7
except:
print("Błąd odczytu pliku test.json")
def save_json(): # 8
with open("test.json", "w") as file: # 9
json.dump(data, file, separators=(",\n", ":")) # 10
if __name__ == "__main__": # 11
read_json() # 12
key = input("Podaj nazwę nowego klucza: ") # 13
value = input("Podaj wartość nowego klucza: ") # 14
data[key] = value # 15
for key, value in data.items(): # 16
print(f"{key}:\t\t{value}")
save_json() # 17
Listing 1. Kod pliku demo_json.py
Rozpoczynamy od zaimportowania modułu json, w którym znajdują się wszystkie interesujące nas funkcje (linia 1). W linii 2 tworzymy pusty słownik o nazwie data. Co prawda nie musimy tego robić w tym miejscu, bo słownik mogłaby wygenerować funkcja odczytująca plik JSON, ale uważam, że zmienne globalne warto tworzyć na początku pliku, gdyż poprawia to czytelność kodu.
W linii 3 rozpoczynamy funkcję read_json, której zadaniem jest odczytanie pliku test.json i zapisanie go do zmiennej globalnej data. Może się zdarzyć, że taki plik jeszcze nie istnieje. Dlatego próbę odczytu powinniśmy wykonać przy pomocy bloku try-except (linia 4). W części try umieszczamy instrukcje, które mogą zakończyć się niepowodzeniem – w tym przypadku chodzi o otwarcie pliku, co do którego istnienia nie jesteśmy pewni lub którego zawartość może wcale nie być sformatowana jako JSON.
Plik otwieramy do odczytu dokładnie tak samo, jak we wcześniejszych przykładach (linia 5). W linii 6 deklarujemy, że chcemy mieć dostęp do zmiennej globalnej data. Bez tego utworzylibyśmy zmienną lokalną, która zostałaby skasowana po wyjściu z tej funkcji. Z modułu json wywołujemy funkcję load, której argumentem jest otwarty plik, a wartością zwracaną – gotowy słownik, który zapisujemy do zmiennej data (linia 7).
Kolejną funkcję stanowi save_json (linia 8). Jej zadanie polega na zapisaniu słownika do pliku test.json. Najpierw musimy otworzyć plik do zapisu (linia 9). Robimy to zupełnie normalnie, ale interesuje nas tryb „w”, aby skasować dotychczasową zawartość pliku lub utworzyć nowy, jeżeli plik o danej nazwie jeszcze nie istnieje. W linii 10 wywołujemy funkcję dump z modułu json. Pierwsze dwa argumenty funkcji to źródłowy słownik oraz plik, do którego ma być on zapisany. Trzeci argument jest opcjonalny – bez niego wszystkie wpisy słownika zostaną zapisane w pliku bez żadnego formatowania – jeden za drugim, wszystkie w jednej linijce. W tym argumencie możemy zdefiniować separatory, a „\n” oznacza znak przejścia do nowej linii po każdej parze klucz-wartość.
Przejdźmy w końcu do głównej części programu, która zaczyna się w linii 11. Najpierw wywołujemy funkcję read_json (linia 12), omówioną kilka akapitów wcześniej. Następnie program wyświetla komunikaty na konsoli, prosząc użytkownika o wprowadzenie nowego klucza i jego wartości (linia 13 i 14). W kolejnej linii dodajemy nowe dane do słownika data, po czym – za pomocą pętli for – wyświetlamy całą zawartość słownika (linia 16). Na końcu zapisujemy słownik do pamięci plików, wywołując funkcję save_json (linia 17).
Niniejszy program można wywoływać wielokrotnie, wciskając klawisz F5 w środowisku Thonny, aby zaobserwować, w jaki sposób słownik gromadzi kolejne porcje danych. Można zobaczyć je także, otwierając plik test.json bezpośrednio w edytorze Thonny.
Karta microSD
Dotychczas omówiliśmy sposoby dostępu do zwykłych plików oraz plików JSON. Operacje nie różnią się istotnie od tych, które wykonalibyśmy w analogicznym celu za pomocą Pythona, znanego z normalnych komputerów. Zobaczmy teraz, w jaki sposób należy podłączyć kartę microSD do ESP32. Można skorzystać z kilku różnych interfejsów, ale my skupimy się na łączu SPI, które omówimy dokładniej w 6. odcinku kursu MicroPythona.

Rysunek 1 oraz tabela 1 prezentują układ wyprowadzeń karty microSD.

Z moich doświadczeń wynika, że tego typu nośniki pamięci są bardzo czułe na zakłócenia na linii zasilania, dlatego dobrze jest dodać kilka kondensatorów filtrujących i odsprzęgających.
Zobaczmy teraz kod pokazany na listingu 2. Jest on bardzo krótki, bo autorzy MicroPythona przygotowali wielofunkcyjne „gotowce”, które wystarczy tylko skonfigurować i uruchomić. Dokładny opis wszystkich funkcjonalności znajdziemy pod adresem [3]. Najpierw musimy zaimportować moduły: machine – aby uzyskać dostęp do warstwy sprzętowej – oraz os, w którym znajdują się różne funkcje związane z systemem plików.
import os
import machine
sd = machine.SDCard(slot=2, width=1, cs=5, # 1
miso=13, mosi=11, sck=12, freq=20000000)
vfs = os.VfsFat(sd) # 2
os.mount(vfs, "/sd") # 3
print(os.listdir("")) # 4
print(os.listdir("sd")) # 5
Listing 2. Kod pliku sd.py
W linii 1 tworzymy instancję klasy SDCard i zapisujemy ją do zmiennej sd. W konstruktorze klasy podajemy kilka argumentów. Pierwszym jest – niezbyt trafnie nazwany – slot, który określa sposób komunikacji z pamięcią. Ustawienie go na wartość 2 oznacza, że z kartą microSD chcemy komunikować się przez interfejs SPI (uwaga – tylko w przypadku ESP32-S3!). Istnieje możliwość komunikacji z różnymi typami pamięci Flash, mamy także kilka możliwych interfejsów do wyboru. Po opis pozostałych opcji odsyłam zainteresowanych Czytelników do dokumentacji klasy SDCard.
Argument width określa liczbę bitów magistrali, przesyłanych w ciągu jednego taktu zegarowego. W przypadku klasycznego SPI jest to rzecz jasna tylko jeden bit. Pozostałe argumenty określają numery pinów oraz częstotliwość sygnału zegarowego.
W ten sposób utworzyliśmy instancję klasy, pozwalającej na niskopoziomowy dostęp do pamięci karty microSD przy pomocy metod takich, jak sd.readblocks() czy sd.writeblocks(), które wykonują operacje na adresach i tablicach bajtów. Aby przejść na wyższy poziom,i zamiast surowych bajtów odczytywać pliki – musimy najpierw utworzyć klasę obsługującą system plików.
Robimy to w linii 2, gdzie tworzymy instancję klasy VfsFat. Stanowi ona rodzaj pośrednika pomiędzy systemem operacyjnym a bajtami zapisanymi w pamięci. Przede wszystkim interpretuje ona bajty zgodnie ze standardem FAT, z którego korzystają wszystkie systemy operacyjne na komputerach. System ten jest stosowany również do obsługi kart microSD. Dostępna jest także klasa VfsLfs2, implementująca system plików Little FS v2 – optymalny dla małych pamięci EEPROM. Tak utworzony obiekt zapisujemy do zmiennej vfs.
Ostatnim krokiem jest zamontowanie systemu plików. W tym celu z modułu os wywołujemy funkcję mount. Pierwszym argumentem jest utworzony linię wcześniej obiekt systemu plików, a drugim – ścieżka, pod którą ten system ma być zainstalowany. Wszystkie pliki i katalogi, znajdujące się na karcie microSD, widoczne będą jako dodatkowy katalog w systemie plików MicroPytona. W naszym przykładzie jest to „/sd”. Tu warto wspomnieć o ciekawym błędzie, bowiem... pierwszy znak ścieżki jest ignorowany przez interpreter MicroPythona. Może on być zupełnie dowolny, a nazwa katalogu zostanie skopiowana, poczynając od drugiego znaku.
W tym momencie karta microSD jest już zainstalowana w systemie. Można otwierać i zapisywać pliki dokładnie tak samo, jak to opisaliśmy we wcześniejszej części tego odcinka naszego kursu. Linie 4 i 5 mają za zadanie wyświetlenie zawartości katalogu głównego oraz katalogu karty microSD. Efekt działania tego programu powinien być podobny do poniższego.
MPY: soft reboot
['sd', 'boot.py', 'font', 'image', 'mem_used.py', 'ssd1309.py']
['System Volume Information', 'aaa.txt', 'test1', 'test2']
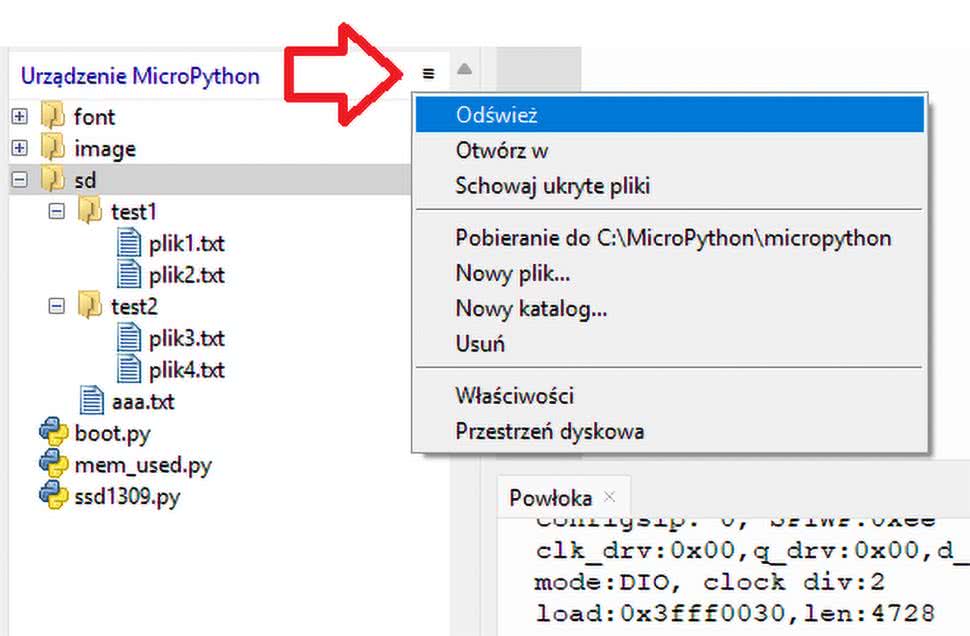
Po wykonaniu programu Thonny nie pokazuje jednak nowego katalogu. Trzeba ręcznie odświeżyć drzewko plików – w tym celu klikamy znajdujący się nad nim przycisk z trzema kreskami (zobacz rysunek 2), a następnie wybieramy Odśwież. Program ponownie odczyta wszystkie pliki i katalogi. Przykładowy rezultat pracy programu widać na rysunku 2.
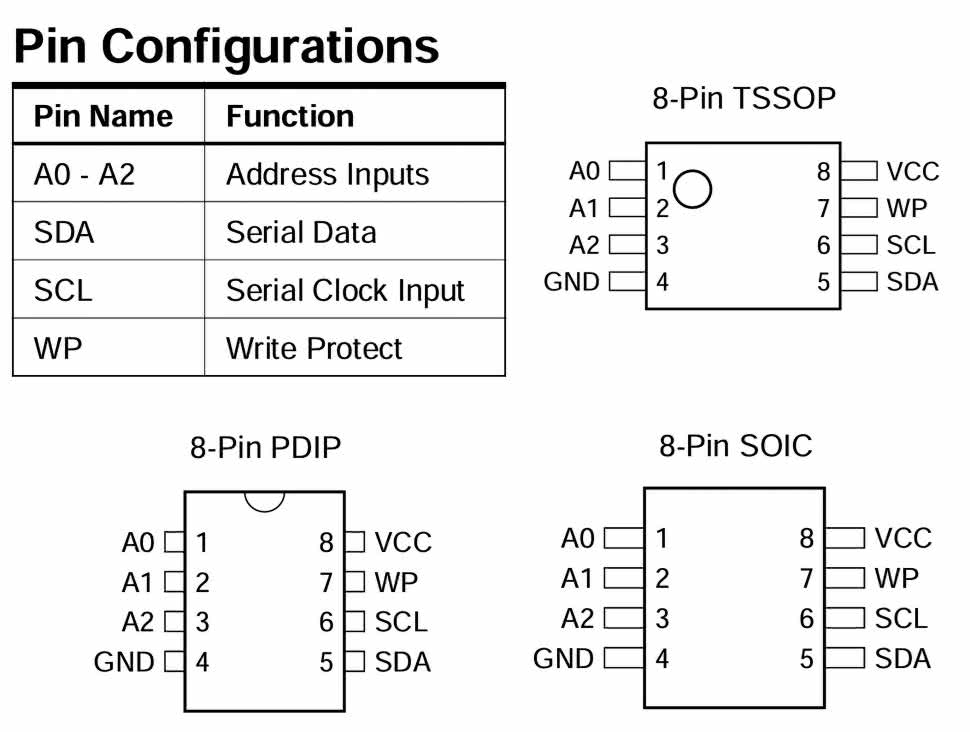
Pamięć EEPROM typu xx24Cxxx
W tej części artykułu weźmiemy pod lupę pamięci EEPROM z popularnej serii 24, takie jak na przykład: AT24C01, AT24C32, AT24C512 itp. Liczba na końcu oznaczenia reprezentuje zwykle pojemność pamięci w kilobitach (a nie w kilobajtach!). Pamięci tego typu dostępne są w wariantach z różnymi obudowami, napięciami zasilania i czasami dostępu. Wspólną cechą tych pamięci jest układ wyprowadzeń (zobacz rysunek 3) oraz sposób komunikacji przez interfejs I²C.
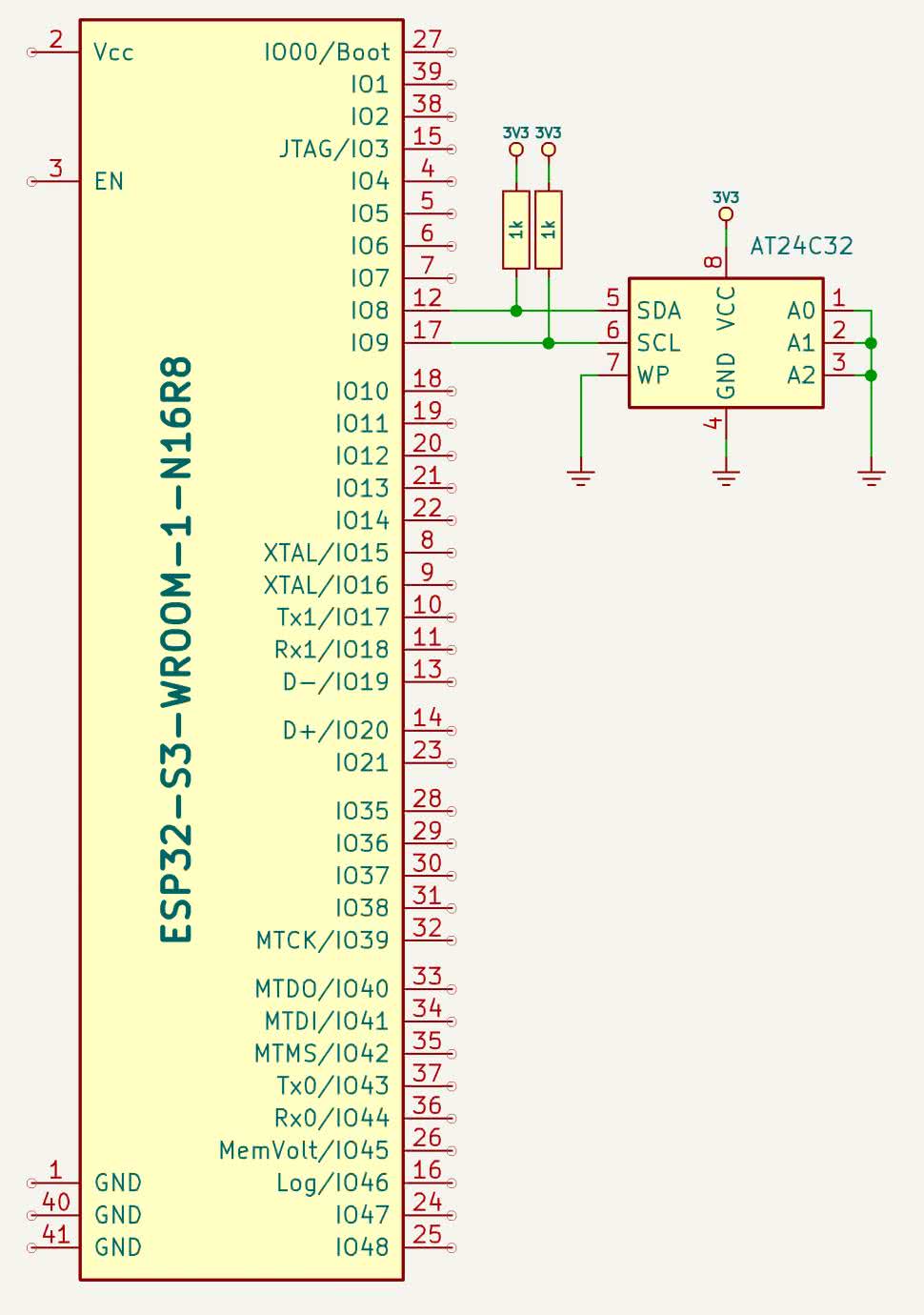
Opracujemy moduł do obsługi pamięci AT24C32, ponieważ taką właśnie zamontowano na płytce z układami DS1307 i 24C32, którą wykorzystywaliśmy w poprzednim odcinku kursu. Istnieje kilka podobieństw pomiędzy AT24C32 i zegarem DS1307, omawianym miesiąc temu. Zegar jest także pamięcią, choć bardzo małą, bo mającą zaledwie 64 bajty. Układ AT24C32 ma 32 kilobity, czyli 4 kB pamięci EEPROM. Wynika z tego kolejna różnica między obydwoma układami – DS1307 mógł być adresowany 8-bitowo, co pozwalało na zaadresowanie 256 bajtów danych, ale AT24C32 musi już stosować adresowanie 16-bitowe, pozwalające na obsługę do 64 kB danych. Ponadto zapis do pamięci RAM odbywa się niemal natychmiast (jest na tyle szybki, że w przypadku komunikacji przez I²C nie musimy się tym wcale przejmować), ale zapis do EEPROM zajmuje pewien czas, w którym pamięć w ogóle nie odpowiada na żadne polecenia. Kolejną różnicę stanowi fakt, że pamięci EEPROM podzielone są na strony. W jednej operacji zapisu możemy zatem zmienić stan tylko tych bajtów, które znajdują się wewnątrz jednej strony. Nie da się zapisać danych na dwóch stronach w tej samej transakcji.
Jest jeszcze jedna, istotna różnica między sposobami komunikacji opisanymi w tym oraz w poprzednim odcinku kursu. Miesiąc temu napisaliśmy kod w postaci osobnych, prostych funkcji. Tym razem utworzymy własną klasę, którą będziemy mogli wykorzystać w różnych programach i działającą z pamięciami o różnych pojemnościach. Przeanalizujmy kod pokazany na listingu 3, zawierający klasę Mem24.
import time
from machine import Pin, I2C
from micropython import const
TIMEOUT_MS = const(5)
class Mem24(): # 1
def __init__(self, i2c, device_address, memory_size, # 2
page_size, addr_size=16):
self.i2c = i2c
self.device_address = device_address
self.memory_size = memory_size
self.page_size = page_size
self.addr_size = addr_size
def __str__(self): # 3
return f"Mem24({str(self.i2c)}, " \
f"device_address=0x{self.device_address:02X}," \
f"memory_size={self.memory_size}, " \
f"page_size={self.page_size}, " \
f"addr_size={self.addr_size})"
def wait_for_ready(self): # 4
timeout = TIMEOUT_MS
while timeout: # 5
try:
self.i2c.readfrom(self.device_address, 1) # 6
return
except: # 7
time.sleep_ms(1)
timeout -= 1
raise OSError(errno.ETIMEDOUT, # 8
"I2C polling too many times without ACK")
def read(self, memory_address, length): # 9
self.wait_for_ready()
return self.i2c.readfrom_mem(self.device_address,
memory_address, length, addrsize=self.addr_size)
def read_into(self, memory_address, buffer): # 10
self.wait_for_ready()
self.i2c.readfrom_mem_into(self.device_address,
memory_address, buffer, addrsize=self.addr_size)
def write_page(self, memory_address, data): # 11
self.wait_for_ready()
self.i2c.writeto_mem(self.device_address,
memory_address, data, addrsize=self.addr_size)
def write(self, memory_address, data): # 12
address_end = memory_address + len(data) – 1
page_start_num = memory_address // self.page_size
page_end_num = address_end // self.page_size
page_actual_num = page_start_num
page_actual_adr_end = None
actual_start = memory_address
actual_end = None
actual_length = None
bytes_sent = 0
while page_actual_num <= page_end_num:
page_actual_adr_end = self.page_size *
(page_actual_num + 1) – 1
actual_end = address_end if address_end <=
page_actual_adr_end else page_actual_adr_end
actual_length = actual_end – actual_start + 1
self.wait_for_ready()
self.write_page(actual_start,
data[bytes_sent:bytes_sent+actual_length])
bytes_sent += actual_length
page_actual_num += 1
actual_start = actual_end + 1
def erase_chip(self): # 13
buffer = bytes(self.page_size * [0xFF]) # 14
memory_address = 0
while memory_address < self.memory_size: # 15
self.wait_for_ready()
self.write_page(memory_address, buffer)
memory_address += self.page_size
def dump(self): # 16
buffer = bytearray(16)
memory_address = 0
print(" 0 1 2 3 4 5 6 7 8 9 A B C D E F")
while memory_address < self.memory_size:
self.read_into(memory_address, buffer)
print(f"{memory_address:08X}: ", end = "")
for byte in buffer:
print(f"{byte:02X} ", end="")
for byte in buffer:
if byte >= 32 and byte <= 127:
print(chr(byte), end=””)
else:
print(" ", end="")
print()
memory_address += 16
if __name__ == "__main__": # 17
i2c = I2C(0) # 18
print(i2c) # 19
mem = Mem24(i2c, device_address=0x50, memory_size=4096, \ # 20
page_size=32, addr_size=16)
print(mem) # 21
def print_hex(buffer): # 22
for byte in buffer:
print(f"{byte:02X} ", end="")
print()
buffer = mem.read(0x0000, 16)
print_hex(buffer)
buffer = bytearray(16)
mem.read_into(0x0010, buffer)
print_hex(buffer)
mem.write(0x0F10, b'ABCDEFGHIJ')
mem.dump()
Listing 3. Kod pliku mem24.py
Przejdźmy najpierw do linii 17, w której znajduje się kod wykonywany po uruchomieniu pliku (a nie zaimportowaniu go przez inny plik).
Najpierw musimy utworzyć instancję interfejsu obsługiwanego przez naszą klasę. Robimy to w linii 18, powołując do życia instancję klasy I2C z modułu machine i zapisując ją do zmiennej i2c. Celowo pominąłem argumenty sda i scl, aby skorzystać z domyślnych pinów mikrokontrolera. W linii 19 „drukujemy” zawartość zmiennej i2c – na konsoli zostaną wyświetlone wszystkie parametry interfejsu, w tym numery użytych pinów.
W linii 20 tworzymy instancję klasy Mem24. Do konstruktora przekazujemy argumenty takie, jak: wybrany interfejs I²C, adres pamięci na magistrali I²C, rozmiar pamięci (w bajtach), rozmiar strony (w bajtach) oraz długość adresu pamięci (w bitach). Tak utworzoną instancję klasy zapisujemy do zmiennej mem. Następnie, w celach diagnostycznych, wyświetlamy zawartość zmiennej mem, aby mieć pewność, w jaki sposób nasza klasa została skonfigurowana (linia 21).
Na potrzeby testów tworzymy prostą funkcję w linii 22, której zadaniem jest wyświetlanie buforów. Wewnątrz tej funkcji mamy prostą pętlę for, która iteruje po wszystkich bajtach w buforze i wyświetla je jako 2-znakowe liczby szesnastkowe z zakresu od 00 do FF.
Następnie mamy dwa przykłady operacji odczytu 16 bajtów pamięci z adresów 0x0000 oraz 0x0010, po czym pod adresem 0x0F10 zapisujemy przykładowy ciąg znaków. Zwróć uwagę, że nie jest to zwykły string, ale bytestring, o czym świadczy litera b przed cudzysłowem. Jak widać, użycie klasy Mem24 jest bardzo łatwe. Zobaczmy więc, w jaki sposób ta klasa jest zbudowana.
Klasę rozpoczynamy w linii 1. Nasza klasa niczego nie dziedziczy, zatem po nazwie Mem24 nie mamy żadnych nawiasów z nazwą klasy nadrzędnej. Wewnątrz klasy definiujemy różne metody. Pierwszą z nich jest metoda specjalna __init__, będąca konstruktorem klasy (linia 2) i często wykorzystywana do skopiowania argumentów konstruktora do zmiennych wewnętrznych klasy, które poprzedzone są słówkiem self. Tak utworzone zmienne mogą być następnie używane przez inne metody w klasie.
W linii 3 definiujemy metodę specjalną __str__. Jest ona wywoływana podczas rzutowania klasy na string. Przykład takiej operacji widzimy w linii 21. W rezultacie metoda musi zwrócić jakiś napis, który możemy zastosować w celach diagnostycznych.
Metoda wait_for_ready, którą tworzymy w linii 4, jest właściwie najważniejszą ze wszystkich, bo bez niej reszta może nie działać prawidłowo. Jej cele to sprawdzanie, czy pamięć jest gotowa do przyjęcia kolejnego polecenia i cykliczne testowanie gotowości co pewien czas. Wykorzystujemy tu zmienną timeout, która jest inicjalizowana wartością stałej TIMEOUT_MS. Będziemy tę zmienną sprawdzać cyklicznie w pętli while tak długo, aż przyjmie wartość zero, co oznaczać będzie błąd. Wewnątrz pętli mamy blok try-except. W linii 6, w sekcji try, próbujemy wywołać pamięć i odczytać z niej 1 bajt – jego zawartość nie ma żadnego znaczenia i nigdzie go nie zapisujemy, interesuje nas tylko sprawdzenie, czy pamięć odpowie w jakikolwiek sposób na transmisję. Jeżeli tak, to znaczy, że pamięć jest gotowa do przyjmowania kolejnych poleceń, zatem kończymy działanie metody instrukcją return. Jeżeli nie, wówczas wchodzimy do sekcji except, gdzie zawieszamy działanie programu na 1 milisekundę, po czym zmienną timeout zmniejszamy o 1 i próbujemy ponownie.
Jeżeli pomimo wielu prób nie uda się nawiązać kontaktu z pamięcią, wtedy przechodzimy do linii 8, gdzie zgłaszamy wyjątek. Należy go w jakiś sposób obsłużyć, bo inaczej program nam się „wysypie”.
W linii 9 mamy metodę read, której zadaniem jest odczytanie ciągu bajtów z pamięci. Adres pierwszego bajtu określany jest argumentem memory_address, a argument length określa liczbę bajtów do odczytania. Wewnątrz tej metody wywołujemy znaną już nam metodę wait_for_ready. Następnie wywołujemy funkcję readfrom_mem, należącą do instancji klasy I2C z modułu machine, która zapisana jest w wewnętrznej zmiennej self.i2c.
W linii 10 znajduje się bardzo podobna metoda, ale korzystająca z innego sposobu przekazywania odczytanych danych. Metoda readfrom_mem_into nie zwraca ciągu bajtów, lecz zapisuje je do bufora wskazanego w argumencie. Liczba bajtów do odczytania jest równa długości podanego bufora.
Przejdźmy do metody write_page, zapisującej dane do pojedynczej strony pamięci (linia 11). W układzie AT24C32 pamięć jest podzielona na 128 stron, każda o pojemności 32 bajtów, co daje razem 4096 B. Podczas operacji zapisu kontroler pamięci może aktualizować zawartość tylko jednej strony. Nie możemy przesyłać danych, które mają być zapisane do co najmniej dwóch stron. W takiej sytuacji zapis zostanie wykonany tylko na pierwszej zaadresowanej stronie, a na pozostałych będzie zignorowany. Korzystając z metody write_page musimy mieć pewność, że zapisujemy maksymalnie 32 bajty, tylko w obrębie pojedynczej strony.
Problem rozwiązuje metoda write. W argumentach podajemy dowolny adres, pod którym możemy zapisać dowolnie długi ciąg danych (oczywiście taki, który zmieści się do pamięci). Metoda sama dzieli dane na strony i będzie wykonywać zapisy w pętli, strona po stronie, aż zapisze wszystkie podane informacje.
W linii 13 mamy metodę erase_chip, której zadaniem jest skasowanie całej pamięci. Układy z serii 24 nie obsługują dedykowanego rozkazu do kasowania. Wobec tego w linii 14 tworzymy bufor o długości strony pamięci, który wypełniamy bajtami 0xFF – ponieważ jest to domyślny stan fabrycznie czystej pamięci EEPROM. Tak utworzony bufor zapisujemy w pętli (linia 15), zaczynając od adresu 0x0000 i dążąc aż do końca pamięci.
Pozostaje już tylko metoda dump (linia 16), której celem jest odczytanie pamięci i wyświetlenie jej na konsoli. Można ją wykorzystywać w celach diagnostycznych.
Gotowe! Wciskamy F5 w edytorze Thonny i testujemy! Na konsoli powinniśmy zobaczyć wynik, jaki pokazano na listingu 4.
MPY: soft reboot
I2C(0, scl=9, sda=8, freq=400000)
Mem24(I2C(0, scl=9, sda=8, freq=400000), device_address=0x50,memory_size=4096, page_size=32, addr_size=16)
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
0 1 2 3 4 5 6 7 8 9 A B C D E F
00000000: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000010: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
...wycięte...
00000F00: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000F10: 41 42 43 44 45 46 47 48 49 4A 4B 4C 4D 4E 4F 50 ABCDEFGHIJKLMNOP
00000F20: 51 52 53 54 55 56 57 58 59 5A 61 62 63 64 65 66 QRSTUVWXYZabcdef
00000F30: 41 42 43 44 45 46 47 48 49 4A 4B 4C 4D 4E 4F 50 ABCDEFGHIJKLMNOP
00000F40: 51 52 53 54 55 56 57 58 59 5A 61 62 63 64 65 66 QRSTUVWXYZabcdef
00000F50: 41 42 43 44 45 46 47 48 49 4A 4B 4C 4D 4E 4F 50 ABCDEFGHIJKLMNOP
00000F60: 51 52 53 54 55 56 57 58 59 5A 61 62 63 64 65 66 QRSTUVWXYZabcdef
00000F70: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000F80: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000F90: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FA0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FB0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FC0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FD0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FE0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000FF0: FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
Listing 4. Wynik pracy kodu z listingu 3
Dysk w pamięci EEPROM
Czas przejść na kolejny poziom – zamiast odczytywać i zapisywać bloki bajtów, chcielibyśmy w pamięci AT24C32 wykonywać operacje na plikach, które w dodatku mogą być przechowywane w różnych folderach. Przechodzimy zatem do najważniejszej części tego odcinka: nauczymy się, w jaki sposób można zainstalować system plików w dowolnej pamięci. W tym celu musimy napisać kolejną klasę, która jest pośrednikiem pomiędzy systemem operacyjnym a klasą transferującą tablice bajtów z i do pamięci. Zobaczmy kod z listingu 5, który zawiera tylko jedną klasę o nazwie Drive.
import os
class Drive:
def __init__(self, memory, path): # 1
self.memory = memory
self.path = path
if memory.page_size < 64: # 2
self.block_size = 64
else:
self.block_size = memory.page_size
try: # 3
os.mount(self, path)
except: # 4
os.VfsLfs2.mkfs(self)
os.mount(self, path)
def format(self): # 5
os.VfsLfs2.mkfs(self)
def deinit(self): # 6
os.umount(self.path)
def readblocks(self, block_num, buf, offset=0): # 7
address = block_num * self.block_size + offset
self.memory.read_into(address, buf)
def writeblocks(self, block_num, buf, offset=0): # 8
if offset is None:
offset = 0
address = block_num * self.block_size + offset
self.memory.write(address, buf)
def ioctl(self, op, arg): # 9
# Number of blocks
if op == 4:
return self.memory.memory_size // self.block_size
# Block size
if op == 5:
return self.block_size
# Block erase
if op == 6:
address = arg * self.block_size
buffer = bytes(b'\x00' * self.block_size)
self.memory.write(address, buffer)
return 0
Listing 5. Kod pliku drive24.py
Już na pierwszy rzut oka widać, że klasa ta jest bardzo prosta i składa się z kilku banalnych metod. Pierwszą z nich stanowi konstruktor __init__ (linia 1). Pobiera on dwa argumenty, nie licząc self. Argument memory to instancja klasy obsługującej pamięć, na przykład Mem24, jaką opracowaliśmy wcześniej. Argument path to string z nazwą folderu, w którym ma zostać zainstalowana pamięć. W przypadku karty SD nazwaliśmy go „/sd”, a tutaj będziemy używać nazwy „/eeprom”.
W linii 2 znajduje się potencjalna przyczyna wielu błędów. Tym bardziej że w oficjalnej dokumentacji MicroPythona wcale o tym fakcie nie wspomniano. Algorytmy systemu plików dzielą mianowicie pamięć na strony i rozsądnie jest, aby strona systemu plików miała taką samą pojemność, jak rzeczywista strona podłączonej pamięci. Jednak strona systemu plików nie może być mniejsza niż 64 B i musi stanowić potęgę dwójki. Pamięć AT24C32 ma długość strony równą 32 B, zatem jedna strona systemu plików musi składać się z dwóch stron pamięci fizycznej.
Następnie mamy blok try-except. W linii 3 próbujemy zamontować system plików pod ścieżką wskazaną w argumencie path. Ta operacja może się nie udać, jeżeli pamięć nie została wcześniej sformatowana. W takiej sytuacji przechodzimy do linii 4, gdzie formatujemy pamięć w formacie LittleFS2. Możemy także wykorzystać system plików FAT, jednak do małych pamięci LittleFS2 jest optymalnym rozwiązaniem. Po sformatowaniu ponownie próbujemy zamontować pamięć jeszcze raz.
Dalej mamy kilka metod. Metoda format (linia 5) służy do czyszczenia pamięci i utworzenia systemu plików na nowo, a deinit (linia 6) odinstalowuje pamięć z systemu – co warto zrobić, jeżeli pamięć ma być fizycznie odłączona od mikrokontrolera. Dalej mamy metody readblocks (linia 7) i writeblocks (linia 8), które odczytują i zapisują bloki pamięci. Funkcje te nie są obowiązkowe do zamontowania pamięci w systemie plików MicroPythona. Na samym końcu mamy metodę ioctl (linia 9). Jest ona wykorzystywana przez MicroPythona, by wykonać inne operacje na pamięci. Istotny jest tutaj argument op, który określa, jaką operację należy wykonać. Obligatoryjne jest zaimplementowanie instrukcji dla op równego 4, 5 i 6, które oznaczają odpowiednio: zwrócenie liczby bloków pamięci, zwrócenie rozmiaru bloku i skasowanie bloku.
W taki sposób możemy zaimplementować obsługę zupełnie dowolnych pamięci, aby korzystać z nich poprzez system plików.
Testujemy!
Pora zebrać wszystko w jedną całość. Napiszemy teraz prosty program, który w pamięci EEPROM typu AT24C32 tworzy system plików i montuje go pod ścieżką „/eeprom”. Następnie spróbujemy odczytać plik „eeprom/test.txt”, w którym spodziewamy się zmiennej liczbowej. Po jej znalezieniu program inkrementuje ją o 1, a następnie zapisuje w tym samym pliku.
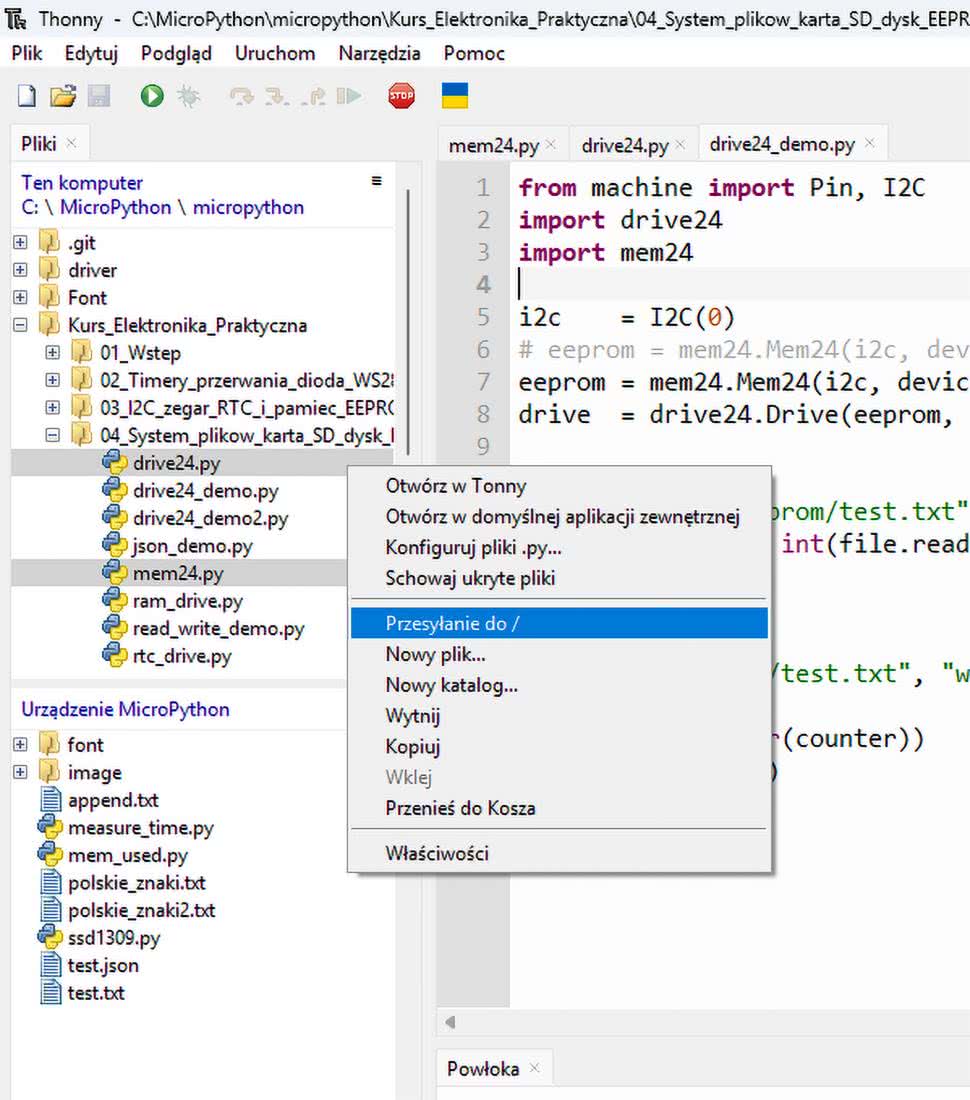
Aby taki skrypt mógł działać, najpierw musimy przesłać napisane przez nas moduły mem24 i drive24 do ESP32. W tym celu, w lewym górnym oknie klikamy odpowiednie pliki prawym przyciskiem myszy, a następnie wybieramy opcję Przesyłanie do /, tak jak pokazuje to rysunek 5. Można zaznaczyć kilka plików do przesłania jednocześnie, klikając je z wciśniętym przyciskiem CTRL lub SHIFT. Po przesłaniu pliki powinny pojawić się w lewym dolnym oknie, gdzie pokazana jest zawartość pamięci w ESP32.
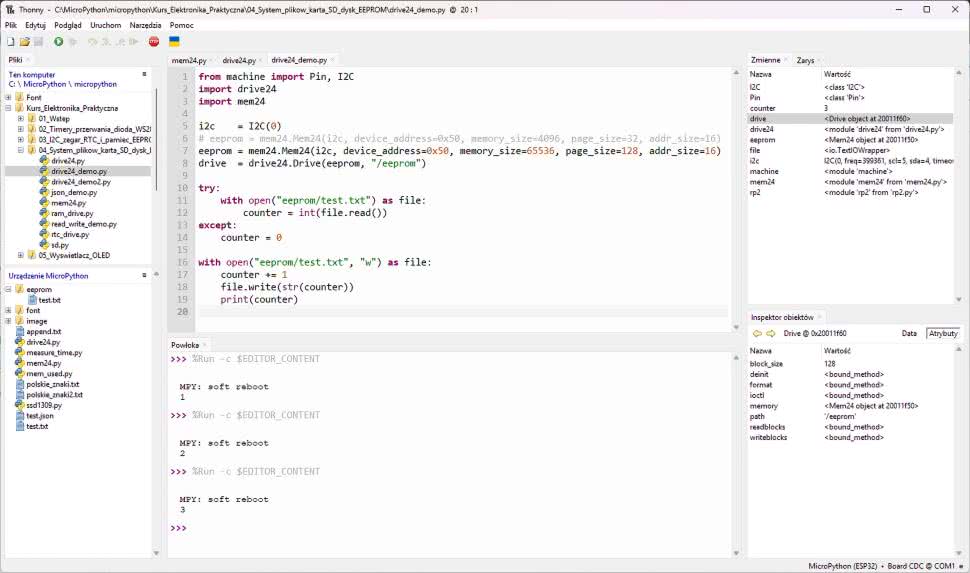
Zobaczmy kod pokazany na listingu 6. W liniach 1 i 2 importujemy moduły, które napisaliśmy w tym odcinku. Następnie tworzymy różne obiekty, które będziemy wykorzystywać później. W linii 3 tworzymy instancję interfejsu I²C w jego domyślnej konfiguracji. Następnie tworzymy instancję pamięci EEPROM. W pierwszym argumencie konstruktora przekazujemy utworzoną wcześniej instancję interfejsu I²C, a w kolejnych znajdują się poszczególne parametry pamięci. Dalej, w linii 4, tworzymy instancję klasy budującej system plików. Pierwszym argumentem konstruktora jest utworzona wcześniej pamięć EEPROM, a drugim – ścieżka dostępu. To wszystko! Utworzyliśmy i skonfigurowaliśmy potrzebne bloki, które są gotowe do użycia.
from machine import Pin, I2C
import drive24 # 1
import mem24 # 2
i2c = I2C(0) # 3
eeprom = mem24.Mem24(i2c, device_address=0x50, \ # 4
memory_size=4096, page_size=32, \
addr_size=16)
drive = drive24.Drive(eeprom, "/eeprom") # 5
try: # 6
with open("eeprom/test.txt") as file:
counter = int(file.read()) # 7
except: # 8
counter = 0
with open("eeprom/test.txt", "w") as file: # 9
counter += 1
file.write(str(counter)) # 10
print(counter)
Listing 6. Kod pliku drive24_demo.py
Dalej widzimy kod, którego celem jest wykonanie właściwego zadania powierzonego naszemu programowi. Plik próbujemy otworzyć w bloku try-except (linia 6). Odczytujemy plik funkcją read, która zwraca jego zawartość jako string. Aby wykonywać operacje matematyczne, musimy jego zawartość przekonwertować na liczbę przy pomocy funkcji int i wynik tej operacji zapisujemy do zmiennej counter. Jeżeli któraś z tych operacji się nie powiedzie, od razu przechodzimy do bloku except, gdzie zmienną counter inicjalizujemy wartością zero. Pozostaje już tylko blok with, w którym zapisujemy zmienną counter powiększoną o 1. Zwróć uwagę, że w linii 10 używamy funkcji str, aby przekształcić liczbę ze zmiennej counter na string.
Uruchamiamy program naciskając F5. Po każdym uruchomieniu na konsoli wyświetli się kolejna liczba, tak jak pokazano na rysunku 6. Odśwież listę plików w okienku Urządzenie MicroPython w lewym dolnym rogu. Wtedy pojawi się katalog eeprom, a w nim plik test.txt. Możesz go otworzyć i edytować jak normalny plik, mimo że zapisany jest w pamięci EEPROM.
W następnym odcinku poznamy sterownik wyświetlacza OLED typu SSD1309 firmy Solomon Systech. Wykorzystamy wyświetlacz o rozdzielczości 128×64 px, pracujący z interfejsem I²C. Na rynku jest dużo różnych płytek z takimi wyświetlaczami. Gorąco polecam zakupić „niebieską” płytkę z wyświetlaczem o przekątnej 2,42 cala, z 7-pinowym konektorem. Takie moduły mogą pracować z interfejsem SPI lub I²C, a zmiana interfejsu jest bardzo prosta i wymaga przylutowania lub odlutowania małych zworek. Wyświetlacze OLED 128×64 px dostępne są w kolorach białym, żółtym, zielonym i niebieskim.
Dominik Bieczyński
leonow32@gmail.com
• Repozytorium kursu na GitHubie https://github.com/leonow32/micropython
• Tryby otwierania plików https://www.geeksforgeeks.org/file-mode-in-python/
• Dokumentacja klasy SDCard https://docs.micropython.org/en/latest/library/machine.SDCard.html












